# 자습서: AWS Glue for Ray에서 ETL 스크립트 작성
**중요**
AWS Glue for Ray는 더 이상 신규 고객에게 공개되지 않습니다. 기존 고객은 정상적으로 서비스를 계속 이용할 수 있습니다. 자세한 내용은 [AWS Glue for Ray 지원 종료](https://docs.aws.amazon.com/glue/latest/dg/awsglue-ray-jobs-availability-change.html)를 참조하세요.
Ray는 기본적으로 Python에서 배포된 작업을 작성하고 규모를 조정할 수 있는 기능을 제공합니다. AWS Glue for Ray는 작업과 대화형 세션 모두에서 액세스할 수 있는 서버리스 Ray 환경을 제공합니다(Ray 대화형 세션은 평가판 단계임). AWS Glue 작업 시스템은 일정에 따라, 트리거 또는 AWS Glue 콘솔을 통해 작업을 관리하고 실행할 수 있는 일관된 방법을 제공합니다.
이러한 AWS Glue 도구를 결합하면 추출, 전환, 적재(ETL) 워크로드에 사용할 수 있는 강력한 도구 모음이 생성되며, AWS Glue의 사용 사례에 많이 사용됩니다. 이 자습서에서는 이 솔루션을 구성하는 기본 사항을 학습합니다.
또한 ETL 워크로드에서 AWS Glue for Spark를 사용할 수 있도록 지원합니다. AWS Glue for Spark 스크립트 작성에 대한 자습서는 [자습서: AWS Glue for Spark 스크립트 작성](aws-glue-programming-intro-tutorial.md) 섹션을 참조하세요. 사용 가능한 엔진에 대한 자세한 내용은 [AWS Glue for Spark 및 AWS Glue for Ray](how-it-works-engines.md) 섹션을 참조하세요. Ray는 분석, 기계 학습(ML) 및 애플리케이션 개발 분야에서 다양한 종류의 작업을 처리할 수 있습니다.
이 자습서에서는 Amazon Simple Storage Service(S3)에 호스팅된 CSV 데이터 세트를 추출, 전환 및 적재합니다. 먼저 퍼블릭 Amazon S3 버킷에 저장된 New York City Taxi and Limousine Commission (TLC) Trip Record Data 데이터 세트로 시작합니다. 이 데이터 세트에 대한 자세한 내용은 [AWS의 오픈 데이터 레지스트리](https://registry.opendata.aws/nyc-tlc-trip-records-pds/)를 참조하세요.
Ray Data 라이브러리에서 사용할 수 있는 미리 정의된 변환을 사용하여 데이터를 변환합니다. Ray Data는 Ray에서 설계한 데이터 세트 준비 라이브러리이며 AWS Glue for Ray 환경에 기본적으로 포함되어 있습니다. 기본적으로 포함된 라이브러리에 대한 자세한 내용은 [Ray 작업과 함께 제공되는 모듈](edit-script-ray-env-dependencies.md#edit-script-ray-modules-provided) 섹션을 참조하세요. 그런 다음 사용자가 제어하는 Amazon S3 버킷에 변환된 데이터를 작성합니다.
**사전 조건** - 이 자습서에서는 AWS Glue 및 Amazon S3에 액세스할 수 있는 AWS 계정이 필요합니다.
## 1단계: Amazon S3에 출력 데이터를 보관할 버킷 생성
이 자습서에서 생성한 데이터의 싱크 역할을 하기 위해 사용자가 제어하는 Amazon S3 버킷이 필요합니다. 다음 절차에 따라 이 버킷을 생성할 수 있습니다.
**참고**
사용자가 제어하는 기존 버킷에 데이터를 쓰려면 이 단계를 건너뛰면 됩니다. 이후 단계에서 사용하기 위해 기존 버킷 이름({{yourBucketName}})을 기록해둡니다.
**Ray 작업 출력을 위한 버킷을 생성하려면**
+ *Amazon S3 사용 설명서*의 [버킷 생성](https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html)에 나와 있는 단계에 따라 버킷을 생성합니다.
+ 버킷 이름을 선택할 때는 {{yourBucketName}}을 기록해둡니다. 이 이름은 이후 단계에서 참조합니다.
+ 다른 구성의 경우 Amazon S3 콘솔에서 제공하는 제안된 설정도 이 자습서에서 작동할 수 있습니다.
예를 들어 Amazon S3 콘솔의 버킷 생성 대화 상자는 다음과 비슷할 수 있습니다.
## 2단계: Ray 작업에 대한 IAM 역할 생성
작업에는 다음을 포함하는 AWS Identity and Access Management(IAM) 역할이 필요합니다.
+ `AWSGlueServiceRole` 관리형 정책에서 부여한 권한. 이는 AWS Glue 작업을 실행하는 데 필요한 기본 권한입니다.
+ `nyc-tlc/*` Amazon S3 리소스에 대한 `Read` 액세스 수준 권한.
+ `{{yourBucketName}}/*` Amazon S3 리소스에 대한 `Write` 액세스 수준 권한.
+ `glue.amazonaws.com` 보안 주체가 역할을 수임할 수 있도록 하는 신뢰 관계.
다음 절차에 따라 이 역할을 생성할 수 있습니다.
**AWS Glue for Ray 작업에 대한 IAM 역할을 생성하려면**
**참고**
다양한 절차에 따라 IAM 역할을 생성할 수 있습니다. IAM 리소스를 프로비저닝하는 방법에 대한 자세한 내용이나 옵션은 [AWS Identity and Access Management 설명서](https://docs.aws.amazon.com/iam/index.html)를 참조하세요.
1. *IAM 사용 설명서*의 [시각적 편집기를 사용하여 IAM 정책(콘솔) 생성](https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies_create-console.html#access_policies_create-visual-editor)에 나온 단계를 수행하여 이전에 설명한 Amazon S3 권한을 정의하는 정책을 생성합니다.
+ 서비스를 선택할 때 Amazon S3를 선택합니다.
+ 정책에 대한 권한을 선택할 때 앞서 언급한 다음 리소스에 대해 다음 작업 세트를 연결합니다.
+ `nyc-tlc/*` Amazon S3 리소스에 대한 읽기 액세스 수준 권한.
+ `{{yourBucketName}}/*` Amazon S3 리소스에 대한 쓰기 액세스 수준 권한.
+ 정책 이름을 선택할 때는 {{YourPolicyName}}을 기록해둡니다. 이 이름은 이후 단계에서 참조합니다.
1. *IAM 사용 설명서*의 [AWS 서비스에 대한 역할 생성(콘솔)](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-service.html#roles-creatingrole-service-console)에 나온 단계에 따라 AWS Glue for Ray 작업의 역할을 생성합니다.
+ 신뢰할 수 있는 AWS 서비스 엔터티를 선택할 때 `Glue`를 선택합니다. 그러면 작업에 필요한 신뢰 관계가 자동으로 채워집니다.
+ 권한 정책에 대한 정책을 선택할 때 다음 정책을 연결합니다.
+ `AWSGlueServiceRole`
+ {{YourPolicyName}}
+ 역할 이름을 선택할 때는 {{YourRoleName}}을 기록해둡니다. 이 이름은 이후 단계에서 참조합니다.
## 3단계: AWS Glue for Ray 작업 생성 및 실행
이 단계에서는 AWS Management Console을 사용하여 AWS Glue 작업을 생성하고 샘플 스크립트를 함께 제공하며 작업을 실행합니다. 작업을 생성하면 콘솔에 Ray 스크립트를 저장, 구성 및 편집할 수 있는 위치가 생성됩니다. 작업 생성에 대한 자세한 내용은 [AWS 콘솔에서 AWS Glue 작업 관리](author-job-glue.md#console-jobs) 섹션을 참조하세요.
이 자습서에서는 다음과 같은 ETL 시나리오를 다룹니다. New York City TLC Trip Record 데이터 세트에서 2022년 1월 기록을 읽고, 기존 열의 데이터를 결합하여 데이터 세트에 새 열(`tip_rate`)을 추가한 다음, 현재 분석과 관련이 없는 열을 여러 개 제거하고 결과를 {{yourBucketName}}에 쓰려고 합니다. 다음 Ray 스크립트에서 다음 단계를 수행합니다.
```
import ray
import pandas
from ray import data
ray.init('auto')
ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv")
# Add the given new column to the dataset and show the sample record after adding a new column
ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"])
# Dropping few columns from the underlying Dataset
ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"])
ds.write_parquet("s3://{{yourBucketName}}/ray/tutorial/output/")
```
**AWS Glue for Ray 작업을 생성하고 실행하려면**
1. AWS Management Console에서 AWS Glue 랜딩 페이지로 이동합니다.
1. 측면 탐색 창에서 **ETL 작업**을 선택합니다.
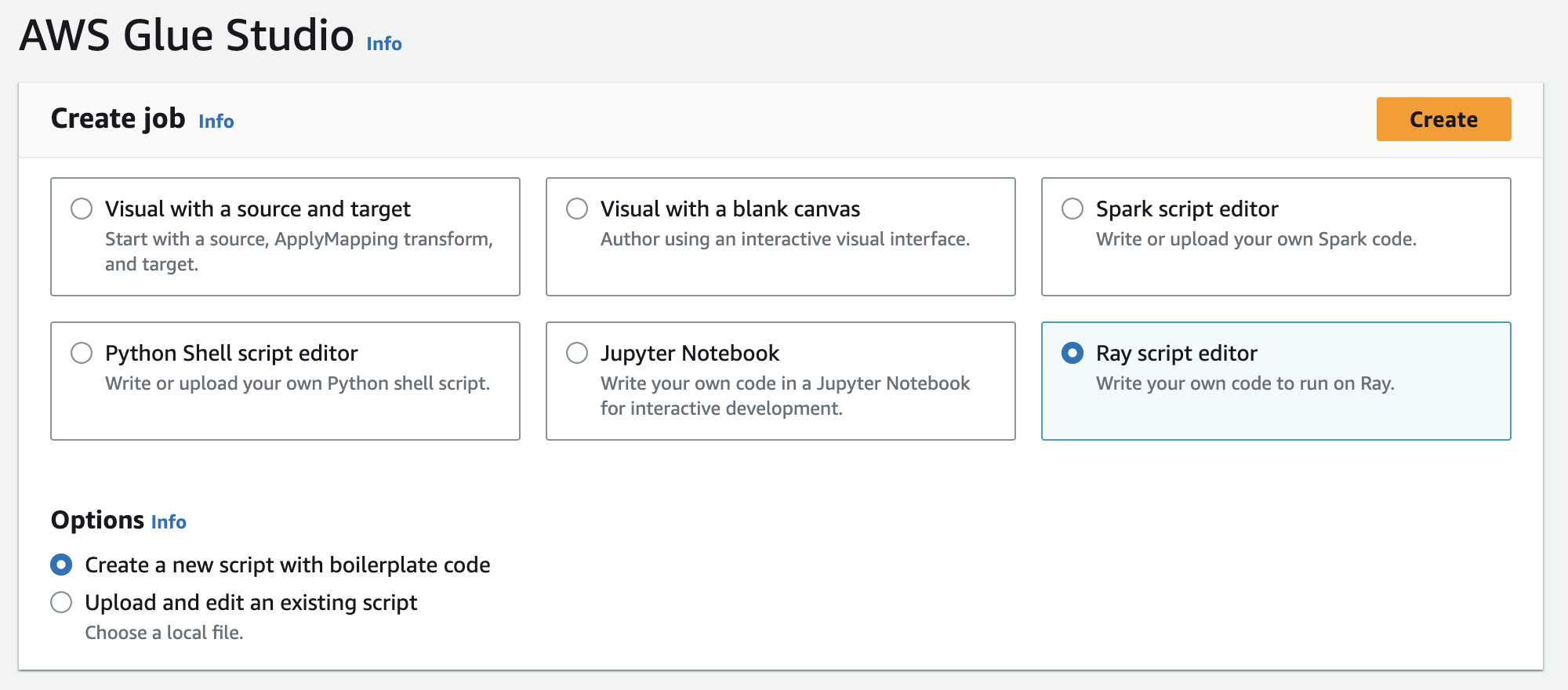
1. 다음 그림과 같이 **작업 생성**에서 **Ray 스크립트 편집기**를 선택한 다음 **생성**을 선택합니다.
1. 스크립트의 전체 텍스트를 **스크립트** 창에 붙여넣고 기존 텍스트를 모두 바꿉니다.
1. **작업 세부 정보**로 이동하여 **IAM 역할** 속성을 {{YourRoleName}}으로 설정합니다.
1. **저장**을 선택한 다음 **실행**을 선택합니다.
## 4단계: 출력 검사
AWS Glue 작업을 실행한 후에는 출력이 이 시나리오의 예상과 일치하는지 확인해야 합니다. 다음 구문을 사용하면 이 작업을 수행할 수 있습니다.
**Ray 작업이 성공적으로 실행되었는지 확인하려면**
1. 작업 세부 정보 페이지에서 **실행**으로 이동합니다.
1. 몇 분 후 **실행 상태**가 **성공**인 실행이 표시됩니다.
1. Amazon S3 콘솔([https://console.aws.amazon.com/s3/](https://console.aws.amazon.com/s3/))로 이동하여 {{yourBucketName}}을 검사합니다. 출력 버킷에 쓴 파일이 표시됩니다.
1. Parquet 파일을 읽고 해당 콘텐츠를 확인합니다. 기존 도구를 사용하여 이 작업을 수행할 수 있습니다. Parquet 파일을 검증하는 프로세스가 없는 경우 Spark 또는 Ray(평가판)를 사용하여 AWS Glue 대화형 세션이 있는 AWS Glue 콘솔에서 이 작업을 수행할 수 있습니다.
대화형 세션에서는 선택한 엔진에 따라 기본적으로 제공되는 Ray Data, Spark 또는 pandas 라이브러리에 액세스할 수 있습니다. 파일 콘텐츠를 확인하려면 해당 라이브러리에서 사용할 수 있는 일반적인 검사 방법(예: `count`, `schema` 및 `show`)을 사용할 수 있습니다. 콘솔에서의 대화형 세션에 대한 자세한 내용은 [AWS Glue Studio 및 AWS Glue에서 노트북 사용](https://docs.aws.amazon.com/glue/latest/ug/notebooks-chapter.html)을 참조하세요.
파일이 버킷에 기록된 것을 확인했으므로 출력에 문제가 있는 경우 IAM 구성과 관련이 없다고 비교적 확신할 수 있습니다. 관련 파일에 액세스할 수 있도록 {{yourRoleName}}으로 세션을 구성합니다.
예상된 결과를 얻지 못하면 이 안내서의 문제 해결 콘텐츠를 살펴보고 오류의 원인을 파악하고 해결합니다. [AWS Glue 문제 해결](troubleshooting-glue.md) 장에서 문제 해결 콘텐츠를 찾을 수 있습니다. Ray 작업과 관련된 특정 오류에 대해서는 문제 해결 장의 [로그에서 AWS Glue for Ray 오류 해결](troubleshooting-ray.md) 섹션을 참조하세요.
## 다음 단계
지금까지 AWS Glue for Ray를 사용하여 ETL 프로세스를 처음부터 끝까지 확인하고 수행했습니다. 다음 리소스를 통해 AWS Glue for Ray가 대규모로 데이터를 변환하고 해석하기 위해 제공하는 도구를 이해할 수 있습니다.
+ Ray의 작업 모델에 대한 자세한 내용은 [AWS Glue for Ray에서 Ray Core 및 Ray Data 사용](edit-script-ray-scripting.md) 섹션을 참조하세요. Ray 작업 사용에 대한 더 많은 경험을 쌓으려면 Ray Core 설명서의 예제를 따르세요. Ray 설명서의 [Ray Core: Ray Tutorials and Examples (2.4.0)](https://docs.ray.io/en/releases-2.4.0/ray-core/examples/overview.html)를 참조하세요.
+ AWS Glue for Ray에서 사용 가능한 데이터 관리 라이브러리에 대한 지침은 [Ray 작업의 데이터에 연결](edit-script-ray-connections-formats.md) 섹션을 참조하세요. Ray Data를 사용하여 데이터 세트를 변환하고 작성하는 데 더 많은 경험을 쌓으려면 Ray Data 설명서의 예제를 따르세요. [Ray Data: Examples (2.4.0)](https://docs.ray.io/en/releases-2.4.0/data/examples/index.html)를 참조하세요.
+ AWS Glue for Ray 작업 구성에 대한 자세한 내용은 [AWS Glue에서 Ray 작업 사용](ray-jobs-section.md) 섹션을 참조하세요.
+ AWS Glue for Ray 스크립트 작성에 대한 자세한 내용은 이 섹션의 설명서를 계속 읽어보세요.