",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
(ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4)
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"compositeRuleEvaluation.method":"ROW"
}
"""
)
)
}
```
AWS Glue Data Catalog에서는 아래와 같이 사용자 인터페이스에서 이 옵션을 쉽게 구성할 수 있습니다.
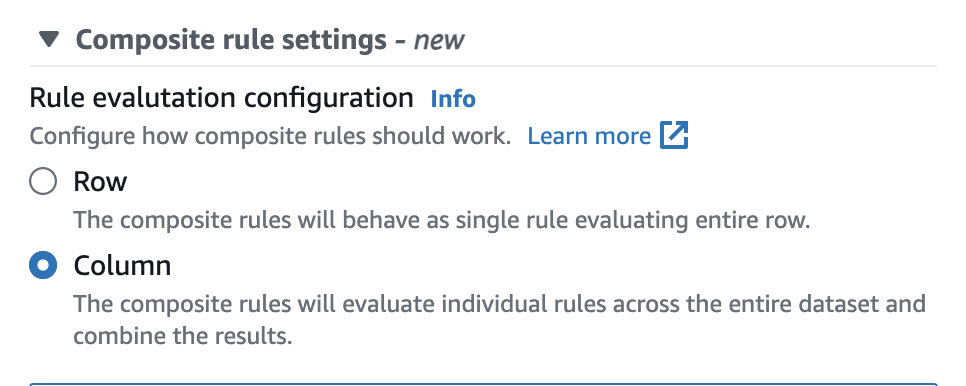
일단 설정되면 복합 규칙은 전체 행을 평가하는 단일 규칙으로 작동합니다. 다음 예제는 이 동작을 보여 줍니다.
```
# Row Level outcome
+------+------+------------------------------------------------------------+---------------------------+
|myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult|
+------+------+------------------------------------------------------------+---------------------------+
|2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
|0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
+------+------+------------------------------------------------------------+---------------------------+
```
일부 규칙은 임계값이나 비율에 따라 전체 결과가 달라지므로 이 기능에서 지원되지 않습니다. 이는 아래에 나열되어 있습니다.
비율에 따른 규칙:
+ 완전성
+ DatasetMatch
+ ReferentialIntegrity
+ Uniqueness
임계값에 따른 규칙:
다음 규칙에 with threshold가 포함된 경우 해당 규칙은 지원되지 않습니다. 그러나 `with threshold`를 포함하지 않는 규칙은 계속 지원됩니다.
+ ColumnDataType
+ ColumnValues
+ CustomSQL
### Expressions
규칙 유형이 부울 응답을 생성하지 않는 경우 부울 응답을 생성하려면 표현식을 파라미터로 제공해야 합니다. 예를 들어 다음 규칙은 열에 있는 모든 값의 중앙값(평균)을 표현식과 비교하여 true 또는 false 결과를 반환합니다.
```
Mean "colA" between 80 and 100
```
`IsUnique` 및 `IsComplete`와 같은 일부 규칙 유형은 이미 부울 응답을 반환합니다.
다음 표는 DQDL 규칙에서 사용할 수 있는 표현식을 나열합니다.
**지원되는 DQDL 표현식**
| 표현식 | 설명 | 예제 |
| --- | --- | --- |
| ={{x}} | 규칙 유형 응답이 {{x}}와 같은 경우 true로 확인됩니다. | Completeness "colA" = "1.0",
ColumnValues "colA" = "2022-06-30"
|
| \!={{x}} | 규칙 유형 응답이 {{x}}와 같지 않으면 x는 true로 확인됩니다. | ColumnValues "colA" != "a",
ColumnValues "colA" != "2022-06-30"
|
| > {{x}} | 규칙 유형 응답이 {{x}}보다 큰 경우 true로 확인됩니다. | ColumnValues "colA" > 10
|
| < {{x}} | 규칙 유형 응답이 {{x}}보다 작은 경우 true로 확인됩니다. | ColumnValues "colA" < 1000,
ColumnValues "colA" < "2022-06-30"
|
| >= {{x}} | 규칙 유형 응답이 {{x}}보다 크거나 같은 경우 true로 확인됩니다. | ColumnValues "colA" >= 10
|
| <= {{x}} | 규칙 유형 응답이 {{x}}보다 작거나 같은 경우 true로 확인됩니다. | ColumnValues "colA" <= 1000
|
| between {{x }}and {{y}} | 규칙 유형 응답이 지정된 범위(제외)에 속하는 경우 true로 확인됩니다. 이 표현식 유형은 숫자 및 날짜 유형에만 사용해야 합니다. | Mean "colA" between 8 and 100,
ColumnValues "colA" between "2022-05-31" and "2022-06-30"
|
| {{x}} 및 {{y}} 사이가 아님 | 규칙 유형 응답이 지정된 범위(포함)에 속하지 않으면 true로 확인됩니다. 이 표현식 유형은 숫자 및 날짜 유형에만 사용해야 합니다. | ColumnValues "colA" not between "2022-05-31" and "2022-06-30"
|
| in [{{a, b, c, ...}}] | 규칙 유형 응답이 지정된 세트 내에 있는 경우 true로 확인됩니다. | ColumnValues "colA" in [ 1, 2, 3 ],
ColumnValues "colA" in [ "a", "b", "c" ]
|
| not in [{{a, b, c, ...}}] | 규칙 유형 응답이 지정된 세트에 없으면 true로 확인됩니다. | ColumnValues "colA" not in [ 1, 2, 3 ],
ColumnValues "colA" not in [ "a", "b", "c" ]
|
| matches {{/ab\+c/i}} | 규칙 유형 응답이 정규 표현식과 일치하는 경우 true로 확인됩니다. | ColumnValues "colA" matches "[a-zA-Z]*"
|
| {{/ab\+c/i}}와 일치하지 않음 | 규칙 유형 응답이 정규식과 일치하지 않는 경우 true로 확인됩니다. | ColumnValues "colA" not matches "[a-zA-Z]*"
|
| now() | ColumnValues 규칙 유형에서만 작동하여 날짜 표현식을 생성합니다. | ColumnValues "load_date" > (now() - 3 days)
|
| matches/in […]/not matches/not in [...] with threshold | 규칙 조건과 일치하는 값의 백분율을 지정합니다. ColumnValues, ColumnDataType, CustomSQL 규칙 유형에만 적용됩니다. | ColumnValues "colA" in ["A", "B"] with threshold > 0.8,
ColumnValues "colA" matches "[a-zA-Z]*" with threshold between 0.2 and 0.9
ColumnDataType "colA" = "Timestamp" with threshold > 0.9
|
#### NULL, EMPTY, WHITESPACES\_ONLY에 대한 키워드
문자열 열에 null, 비어 있음 또는 공백만 있는 문자열이 있는지 확인하려면 다음 키워드를 사용할 수 있습니다.
+ NULL/null - 이 키워드는 문자열 열의 `null` 값에 대해 true로 확인됩니다.
`ColumnValues "colA" != NULL with threshold > 0.5`는 데이터의 50% 이상에 null 값이 없는 경우 true를 반환합니다.
`(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)`는 null 값이 있거나 길이가 5를 초과하는 모든 행에 대해 true를 반환합니다. **이 경우 "compositeRuleEvaluation.method" = "ROW" 옵션을 사용해야 한다는 점에 유의하세요.
+ EMPTY/empty - 이 키워드는 문자열 열의 빈 문자열("") 값에 대해 true로 확인됩니다. 일부 데이터 형식은 문자열 열의 null을 빈 문자열로 변환합니다. 이 키워드는 데이터에서 빈 문자열을 필터링하는 데 도움이 됩니다.
`(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])`는 행이 비어 있거나 "a" 또는 "b"인 경우 true를 반환합니다. **이 경우 "compositeRuleEvaluation.method" = "ROW" 옵션을 사용해야 한다는 점에 유의하세요.
+ WHITESPACES\_ONLY/whitespaces\_only - 이 키워드는 문자열 열에 공백(" ") 값만 있는 문자열에 대해 true로 확인됩니다.
`ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]`는 ‘a’, ‘b’ 또는 공백만 있는 행이 아닌 경우 true를 반환합니다.
지원되는 규칙:
+ [ColumnValues](https://docs.aws.amazon.com/glue/latest/dg/dqdl.html#dqdl-rule-types-ColumnValues)
숫자 또는 날짜 기반 표현식에서 열에 null이 있는지 확인하려는 경우 다음 키워드를 사용할 수 있습니다.
+ NULL/null - 이 키워드는 문자열 열의 null 값에 대해 true로 확인됩니다.
`ColumnValues "colA" in [NULL, "2023-01-01"]`은 열의 날짜가 `2023-01-01`이거나 null인 경우 true를 반환합니다.
`(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)`는 null 값이 있거나 1에서 9 사이의 값을 갖는 모든 행에 대해 true를 반환합니다. **이 경우 "compositeRuleEvaluation.method" = "ROW" 옵션을 사용해야 한다는 점에 유의하세요.
지원되는 규칙:
+ [ColumnValues](https://docs.aws.amazon.com/glue/latest/dg/dqdl.html#dqdl-rule-types-ColumnValues)
#### Where 절을 사용한 필터링
**참고**
여기에서 조항은 AWS Glue 4.0에서만 지원됩니다.
규칙을 작성할 때 데이터를 필터링할 수 있습니다. 이는 조건부 규칙을 적용하려는 경우에 유용합니다.
```
where " "
```
필터는 `where` 키워드와 따옴표(`("")`)로 묶인 유효한 SparkSQL 문을 사용하여 지정해야 합니다.
임계값이 있는 규칙에 where 절을 추가하려면 임계값 조건보다 먼저 where 절을 지정해야 합니다.
```
where "valid SparkSQL statement>" with threshold
```
이 구문을 사용하면 다음과 같은 규칙을 작성할 수 있습니다.
```
Completeness "colA" > 0.5 where "colB = 10"
ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9
ColumnLength "colC" > 10 where "colD != Concat(colE, colF)"
```
제공된 SparkSQL 문이 유효한지 검증해보겠습니다. 유효하지 않은 경우 규칙 평가가 실패하고 다음 형식의 `IllegalArgumentException`이 실행됩니다.
```
Rule where "" has provided an invalid where clause :
```
**행 수준 오류 레코드 식별 기능이 켜져 있을 때의 Where 절 동작**
AWS Glue Data Quality를 사용하면 실패한 특정 레코드를 식별할 수 있습니다. 행 수준 결과를 지원하는 규칙에 where 절을 적용할 때는 where 절로 필터링된 행에 `Passed`라는 레이블을 지정합니다.
필터링된 행에 별도로 `SKIPPED`라는 레이블을 지정하려는 경우 ETL 작업에 대해 다음 `additionalOptions`를 설정할 수 있습니다.
```
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="",
tableName="",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
IsComplete "att2" where "att1 = 'a'"
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"rowLevelConfiguration.filteredRowLabel":"SKIPPED"
}
"""
)
)
}
```
다음 규칙 및 데이터 프레임을 예시로 참조하세요.
```
IsComplete att2 where "att1 = 'a'"
```
| id | att1 | att2 | 행 수준 결과(기본값) | 행 수준 결과(Skipped 옵션) | 설명 |
| --- | --- | --- | --- | --- | --- |
| 1 | a | f | 통과 | 통과 | |
| 2 | b | d | 통과 | SKIPPED | att1이 "a"가 아니므로 행이 필터링됩니다. |
| 3 | a | null | FAILED | FAILED | |
| 4 | a | f | 통과 | 통과 | |
| 5 | b | null | 통과 | SKIPPED | att1이 "a"가 아니므로 행이 필터링됩니다. |
| 6 | a | f | 통과 | 통과 | |
### 상수
DQDL에서 상수 값을 정의하고 스크립트 전체에서 참조할 수 있습니다. 이는 허용 가능한 경계를 초과할 수 있는 큰 SQL 문으로 작업할 때처럼 쿼리 크기 제한과 관련된 문제를 방지하는 데 도움이 됩니다. 이러한 값을 상수에 할당하면 DQDL을 간소화하고 이러한 제한에 도달하지 않도록 할 수 있습니다.
다음 예제는 상수를 정의하고 사용하는 방법을 보여줍니다.
```
mySql = "select count(*) from primary"
Rules = [
CustomSql $mySql between 0 and 100
]
```
이 예제에서는 SQL 쿼리가 상수 `mySql`에 할당된 다음 이 상수가 `$` 접두사를 사용하여 규칙에서 참조됩니다.
### 레이블
레이블은 데이터 품질 결과를 구성하고 분석하는 효과적인 방법을 제공합니다. 특정 레이블로 결과를 쿼리하여 특정 범주 내의 실패한 규칙을 식별하고, 팀 또는 도메인별로 규칙 결과를 계산하고, 다양한 이해관계자를 위한 집중 보고서를 생성할 수 있습니다.
예를 들어 `"team=finance"` 레이블을 사용하여 재무 팀과 관련된 모든 규칙을 적용하고 재무 팀과 관련된 품질 지표를 보여주는 사용자 지정 보고서를 생성할 수 있습니다. 우선순위가 높은 규칙에 `"criticality=high"` 레이블을 지정하여 문제 해결 작업의 우선순위를 지정할 수 있습니다. 레이블은 DQDL의 일부로 작성할 수 있습니다. 규칙 결과, 행 수준 결과, API 응답의 일부로 레이블을 쿼리할 수 있어, 기존 모니터링 및 보고 워크플로와 쉽게 통합할 수 있습니다.
**참고**
레이블은 AWS Glue ETL에서만 사용할 수 있으며 AWS Glue Data Catalog 기반 Data Quality에서는 사용할 수 없습니다.
#### DQDL 레이블 구문
DQDL은 기본 레이블과 규칙별 레이블을 모두 지원합니다. 기본 레이블은 규칙 세트 수준에서 정의되며 해당 규칙 세트 내의 모든 규칙에 자동 적용됩니다. 개별 규칙에는 자체 레이블이 있을 수 있으며, 레이블이 키 값 페어로 구현되므로 동일한 키를 사용할 때 규칙별 레이블이 기본 레이블을 재정의할 수 있습니다.
다음 예제에서는 기본 레이블과 규칙별 레이블을 사용하는 방법을 보여줍니다.
```
DefaultLabels=["frequency"="monthly"]
Rules = [
// Auto includes the default label ["frequency"="monthly"]
ColumnValues "col" > 21,
// Add ["foo"="bar"] to default label. Labels for this rule would be ["frequency"="monthly", "foo"="bar"]
RowCount > 0 with threshold > 0.8 labels=["foo"="bar"],
// Override default label. Labels for this rule would be ["frequency"="daily", "foo"="bar"]
ColumnValues "colA" in ["A", "B"] with threshold > 0.8 labels=["foo"="bar", "frequency"="daily"]
// Labels must be applied to the entire composite rule (parentheses required)
(isComplete "col" AND RowCount > 0) labels=["foo"="bar]
]
```
다음 예제에서는 레이블과 복합 규칙이 있는 잘못된 구문을 보여줍니다.
```
(isComplete "colA") AND (RowCount > 0) labels=["foo"="bar"]
(isComplete "colA" labels=["foo"="bar"]) AND (RowCount > 0)
isComplete "col" AND RowCount > 0 labels=["foo"="bar]
```
##### 레이블 제약 조건
레이블의 제약 조건은
+ DQDL 규칙당 최대 10개의 레이블입니다.
+ 레이블은 키 값 페어 목록으로 지정됩니다.
+ 레이블 키와 레이블 값은 대소문자를 구분합니다.
+ 레이블 키의 최대 길이는 128자입니다. 레이블 키는 비어 있거나 null이면 안 됩니다.
+ 레이블 값의 최대 길이는 256자입니다. 레이블 값은 비어 있거나 null일 수 있습니다.
#### DQDL 레이블 검색
규칙 결과, 행 수준 결과, API 응답에서 DQDL 레이블을 검색할 수 있습니다.
##### 규칙 결과
DQDL 레이블은 규칙 결과에 항상 표시됩니다. DQDL 레이블을 활성화하기 위해 필요한 추가 구성은 없습니다.
##### 행 수준 결과
DQDL 레이블은 행 수준 결과에서 기본적으로 비활성화되지만 `EvaluateDataQuality`에서 `AdditionalOptions`를 사용하여 활성화할 수 있습니다.
다음 예제는 행 수준 결과에서 레이블을 활성화하는 방법을 보여줍니다.
```
val evaluateResult = EvaluateDataQuality.processRows(
frame=AmazonS3_node1754591511068,
ruleset=example_ruleset,
publishingOptions=JsonOptions("""{
"dataQualityEvaluationContext": "evaluateResult",
"enableDataQualityCloudWatchMetrics": "true",
"enableDataQualityResultsPublishing": "true"
}"""),
additionalOptions=JsonOptions("""{
"performanceTuning.caching":"CACHE_NOTHING",
"observations.scope":"ALL",
"rowLevelConfiguration.ruleWithLabels":"ENABLED"
}""")
)
```
활성화되면 행 수준 결과 데이터 프레임에 `DataQualityRulesPass`, `DataQualityRulesFail`, `DataQualityRulesSkip` 열의 각 규칙의 레이블이 포함됩니다.
##### API 응답
DQDL 레이블은 `RuleResults` 객체의 새 필드 `Labels` 아래에 있는 API 응답에 항상 표시됩니다.
다음 예제는 API 응답의 레이블을 보여줍니다.
```
{
"ResultId": "dqresult-example",
"ProfileId": "dqprofile-example",
"Score": 0.6666666666666666,
"RulesetName": "EvaluateDataQuality_node1754591514205",
"EvaluationContext": "EvaluateDataQuality_node1754591514205",
"StartedOn": "2025-08-22T19:36:10.448000+00:00",
"CompletedOn": "2025-08-22T19:36:16.368000+00:00",
"JobName": "anniezc-test-labels",
"JobRunId": "jr_068f6d7a45074d9105d14e4dee09db12c3b95664b45f6ee44fa29ed7e5619ba8",
"RuleResults": [
{
"Name": "Rule_0",
"Description": "IsComplete colA",
"EvaluationMessage": "Input data does not include column colA!",
"Result": "FAIL",
"EvaluatedMetrics": {},
"EvaluatedRule": "IsComplete colA",
"Labels": {
"frequency": "monthly"
}
},
{
"Name": "Rule_1",
"Description": "Rule 1 with threshold > 0.8",
"Result": "PASS",
"EvaluatedMetrics": {},
"EvaluatedRule": "Rule 1 with threshold > 0.8",
"Labels": {
"frequency": "monthly",
"foo": "bar"
}
},
{
"Name": "Rule_3",
"Description": "Rule 2 with threshold > 0.8",
"Result": "PASS",
"EvaluatedMetrics": {},
"EvaluatedRule": "Rule 2 with threshold > 0.8",
"Labels": {
"frequency": "daily",
"foo": "bar"
}
}
]
}
```
### 동적 규칙
**참고**
동적 규칙은 AWS Glue ETL에서만 지원되며 AWS Glue Data Catalog에서 지원되지 않습니다.
이제 동적 규칙을 작성하여 규칙에 의해 생성된 현재 지표를 기록 값과 비교할 수 있습니다. 이러한 기록 비교는 표현식에 `last()` 연산자를 사용하여 사용할 수 있습니다. 예를 들어 현재 실행 중인 행 수가 동일한 데이터 세트에 대한 가장 최근의 이전 행 수보다 많을 때 규칙 `RowCount > last()`가 성공합니다. `last()`는 고려할 기록 지표의 개수를 나타내는 선택적 자연수 인수를 취하고, `last(k)`는 마지막 `k` 지표를 참조하는 `k >= 1`을 취합니다.
+ 사용 가능한 데이터 포인트가 없는 경우 `last(k)`는 기본값 0.0을 반환합니다.
+ 사용할 수 있는 지표가 `k`개 미만인 경우 `last(k)`는 이전 지표를 모두 반환합니다.
유효한 표현식을 만들려면 `last(k)`를 사용합니다. 여기서 `k > 1`에는 여러 개의 기록 결과를 하나의 숫자로 줄이는 집계 함수가 필요합니다. 예를 들어 `RowCount > avg(last(5))`는 현재 데이터 세트의 행 수가 동일한 데이터 세트의 최근 5개 행 수의 평균보다 확실하게 큰지 확인합니다. `RowCount > last(5)`는 현재 데이터 세트 행 수를 목록과 유의미하게 비교할 수 없기 때문에 오류를 생성합니다.
지원되는 집계 함수:
+ `avg`
+ `median`
+ `max`
+ `min`
+ `sum`
+ `std`(표준 편차)
+ `abs`(절대값)
+ `index(last(k), i)`를 사용하면 최근 `k`개 중 가장 최근인 `i`번째 값을 선택할 수 있습니다. `i`는 0으로 인덱싱되므로 `index(last(3), 0)`은 가장 최근의 데이터 포인트를 반환하고, `index(last(3), 3)`은 데이터 포인트가 3개뿐이지만 4번째 가장 최근의 데이터 포인트를 인덱싱하려고 시도하기 때문에 오류가 발생합니다.
**샘플 표현식**
**ColumnCorrelation**
+ `ColumnCorrelation "colA" "colB" < avg(last(10))`
**DistinctValuesCount**
+ `DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1`
숫자 조건 또는 임곗값이 있는 대부분의 규칙 유형은 동적 규칙을 지원합니다. 제공된 테이블인 [분석기 및 규칙](#dqdl-analyzers-table)을 참조하여 해당 규칙 유형에 동적 규칙이 지원되는지 확인하세요.
**동적 규칙에서 통계 제외**
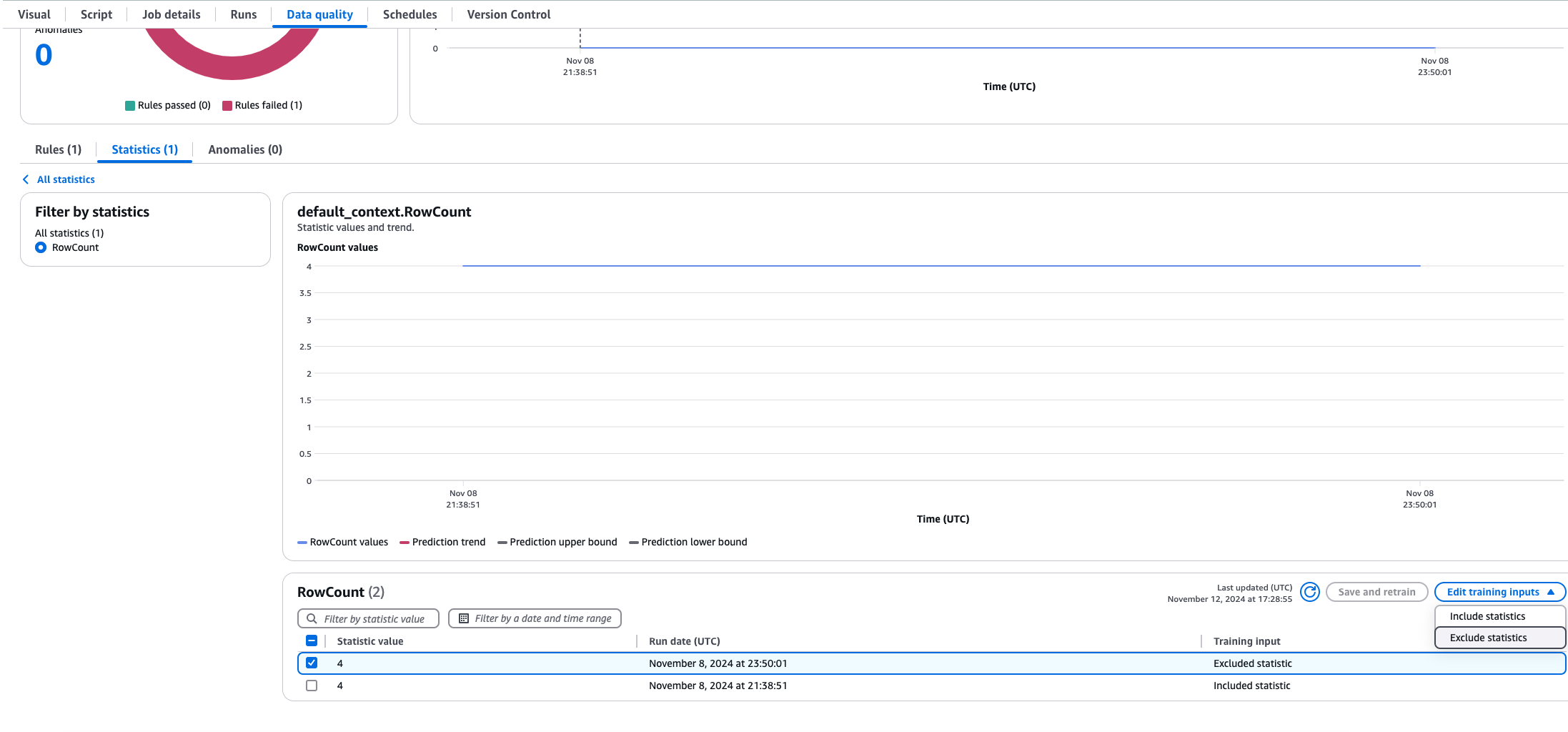
때때로 동적 규칙 계산에서 데이터 통계를 제외해야 합니다. 과거 데이터 로드를 수행했지만 평균에 영향을 주지 않기를 원한다고 가정합니다. 이를 위해 AWS Glue ETL에서 작업을 열고 **데이터 품질** 탭을 선택한 다음, **통계**를 선택하고 제외하려는 통계를 선택합니다. 통계 테이블과 함께 추세 차트를 볼 수 있습니다. 제외하려는 값을 선택하고 **통계 제외**를 선택합니다. 이제 제외된 통계는 동적 규칙 계산에 포함되지 않습니다.
### 분석기
**참고**
분석기는 AWS Glue 데이터 카탈로그에서 지원되지 않습니다.
DQDL 규칙은 분석기**라는 함수를 사용하여 데이터에 대한 정보를 수집합니다. 이 정보는 규칙의 부울 표현식에 의해 사용되어 규칙의 성공 또는 실패 여부를 결정합니다. 예를 들어 RowCount 규칙 `RowCount > 5 `는 행 수 분석기를 사용하여 데이터 세트의 행 수를 검색하고, 그 수를 표현식 `> 5`와 비교하여 현재 데이터 세트에 5개 이상의 행이 존재하는지 확인합니다.
때로는 규칙을 작성하는 대신 분석기를 생성한 다음 이상을 탐지하는 데 사용할 수 있는 통계를 생성하는 것을 권장합니다. 이러한 경우에는 분석기를 생성할 수 있습니다. 분석기는 다음과 같은 점에서 규칙과 다릅니다.
| 기능 | 분석기 | 규칙 |
| --- | --- | --- |
| 규칙 세트의 일부 | 예 | 예 |
| 통계 생성 | 예 | 예 |
| 관찰 결과 생성 | 예 | 예 |
| 조건 평가 및 어설션 가능 | 아니요 | 예 |
| 실패 시 작업 중지, 작업 계속 처리 등의 작업을 구성할 수 있음 | 아니요 | 예 |
분석기는 규칙 없이 독립적으로 존재할 수 있으므로 신속하게 구성하고 데이터 품질 규칙을 점진적으로 구축할 수 있습니다.
일부 규칙 유형은 규칙 세트의 `Analyzers` 블록에 입력하여 분석기에 필요한 규칙을 실행하고 조건에 대한 검사를 적용하지 않고 정보를 수집할 수 있습니다. 일부 분석기는 규칙과 연결되지 않으며 `Analyzers` 블록에만 입력할 수 있습니다. 다음 테이블에는 각 항목이 규칙 또는 독립 실행형 분석기로 지원되는지 여부와 각 규칙 유형에 대한 추가 세부 정보가 나와 있습니다.
**분석기를 사용한 규칙 세트 예제**
다음 규칙 세트는 다음을 사용합니다.
+ 데이터 세트가 지난 세 번의 작업 실행에 대한 후행 평균보다 증가하고 있는지 확인하는 동적 규칙
+ 데이터 세트의 `Name` 열에 고유한 값의 수를 기록하는 `DistinctValuesCount` 분석기
+ 시간 경과에 따른 최소 및 최대 `Name` 크기를 추적하는 `ColumnLength` 분석기
분석기 메트릭 결과는 작업 실행의 Data Quality 탭에서 확인할 수 있습니다.
```
Rules = [
RowCount > avg(last(3))
]
Analyzers = [
DistinctValuesCount "Name",
ColumnLength "Name"
]
```
AWS Glue Data Quality는 다음 분석기를 지원합니다.
| 분석기 이름 | 기능 |
| --- | --- |
| RowCount | 데이터 세트의 행 수를 계산합니다. |
| Completeness | 열의 완전성 백분율을 계산합니다. |
| Uniqueness | 열의 고유성 비율을 계산합니다. |
| Mean | 숫자 열의 평균을 계산합니다. |
| Sum | 숫자 열의 합계를 계산합니다. |
| StandardDeviation | 숫자 열의 표준 편차를 계산합니다. |
| Entropy | 숫자 열의 엔트로피를 계산합니다. |
| DistinctValuesCount | 열의 고유 값 수를 계산합니다. |
| UniqueValueRatio | 열의 고유 값 비율을 계산합니다. |
| ColumnCount | 데이터 세트의 열 수를 계산합니다. |
| ColumnLength | 열의 길이를 계산합니다. |
| ColumnValues | 숫자 열의 최소값, 최대값을 계산합니다. 숫자가 아닌 열의 최소 열 길이 및 최대 열 길이를 계산합니다. |
| ColumnCorrelation | 지정된 열의 열 상관 관계를 계산합니다. |
| CustomSql | CustomSQL에서 반환된 통계를 계산합니다. |
| AllStatistics | 다음 통계를 계산합니다.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/glue/latest/dg/dqdl.html) |
### 설명
‘\#’ 문자를 사용하여 DQDL 문서에 설명을 추가할 수 있습니다. ‘\#’ 문자 이후부터 줄 끝까지의 모든 내용은 DQDL에서 무시됩니다.
```
Rules = [
# More items should generally mean a higher price, so correlation should be positive
ColumnCorrelation "price" "num_items" > 0
]
```