# 자습서: AWS Glue for Spark 스크립트 작성
이 자습서에서는 AWS Glue 스크립트 작성 과정을 소개합니다. 작업을 사용하여 일정에 따라 스크립트를 실행하거나, 대화형 세션을 사용하여 대화형으로 실행할 수 있습니다. 작업에 대한 자세한 내용은 [Visual ETL 작업 구축](author-job-glue.md) 섹션을 참조하세요. 대화형 세션에 대한 자세한 내용을 알아보려면 [AWS Glue 대화형 세션 개요](interactive-sessions-chapter.md#interactive-sessions-overview)을(를) 참조하세요.
AWS Glue Studio 시각적 편집기는 AWS Glue 작업 빌드를 위한 그래픽의 코드가 없는 인터페이스를 제공합니다. AWS Glue 스크립트는 시각적 작업을 뒷받침합니다. 이를 통해 Apache Spark 프로그램과 함께 작동하는 데 사용할 수 있는 확장된 도구 세트에 액세스할 수 있습니다. 기본 Spark API와 AWS Glue 스크립트 내에서 추출, 전환, 적재(ETL) 워크플로를 용이하게 하는 AWS Glue 라이브러리에 액세스할 수 있습니다.
이 자습서에서는 주차 티켓 데이터 세트를 추출, 변환 및 로드합니다. 이 작업을 수행하는 스크립트는 AWS Glue Studio 시각적 편집기를 소개하는 AWS Big Data Blog의 [Making ETL easier with AWS Glue Studio](https://aws.amazon.com/blogs/big-data/making-etl-easier-with-aws-glue-studio/)에서 생성한 스크립트와 형태와 기능이 동일합니다. 작업에서 이 스크립트를 실행하여 시각적 작업과 비교하고 AWS Glue ETL 스크립트가 어떻게 작동하는지 확인할 수 있습니다. 이렇게 하면 시각적 작업에서 아직 사용할 수 없는 추가 기능을 사용할 수 있습니다.
이 자습서에서는 Python 언어 및 라이브러리를 사용합니다. Scala에서도 비슷한 기능을 사용할 수 있습니다. 이 자습서를 진행한 후에는 샘플 Scala 스크립트를 생성하고 검사하여 Scala AWS Glue ETL 스크립트 작성 프로세스를 수행하는 방법을 파악할 수 있습니다.
## 사전 조건
이 자습서의 사전 요구 사항은 다음과 같습니다.
+ CloudFormation 템플릿을 실행하도록 안내하는 AWS Glue Studio 블로그 게시물과 동일한 사전 조건입니다.
이 템플릿은 AWS Glue 데이터 카탈로그를 사용하여 `s3://aws-bigdata-blog/artifacts/gluestudio/`에서 제공되는 주차 티켓 데이터 세트를 관리합니다. 참조할 다음 리소스를 생성합니다.
+ **AWS Glue Studio역할** — AWS Glue 작업을 실행할 IAM 역할
+ **AWS Glue StudioAmazon S3Bucket** — 블로그 관련 파일을 저장할 Amazon S3 버킷의 이름
+ **AWS Glue StudioTicketsYYZDB** – AWS Glue 데이터 카탈로그 데이터베이스
+ **AWS Glue StudioTableTickets** — 소스로 사용할 데이터 카탈로그 테이블
+ **AWS Glue StudioTableTrials** — 소스로 사용할 데이터 카탈로그 테이블
+ **AWS Glue StudioParkingTicketCount **– 대상으로 사용할 데이터 카탈로그 테이블
+ AWS Glue Studio 블로그 게시물에서 생성된 스크립트입니다. 블로그 게시물이 변경되면 다음 텍스트에서도 스크립트를 사용할 수 있습니다.
### 샘플 스크립트 생성
AWS Glue Studio 시각적 편집기는 작성하려는 스크립트에 대한 스캐폴드를 생성하는 강력한 코드 생성 도구로 사용할 수 있습니다. 이 도구를 사용하여 샘플 스크립트를 생성합니다.
이 단계를 건너뛰려는 경우, 스크립트가 제공됩니다.
#### 자습서 샘플 스크립트
```
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node S3 bucket
S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog(
database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1"
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("tag_number_masked", "string", "tag_number_masked", "string"),
("date_of_infraction", "string", "date_of_infraction", "string"),
("ticket_date", "string", "ticket_date", "string"),
("ticket_number", "decimal", "ticket_number", "float"),
("officer", "decimal", "officer_name", "decimal"),
("infraction_code", "decimal", "infraction_code", "decimal"),
("infraction_description", "string", "infraction_description", "string"),
("set_fine_amount", "decimal", "set_fine_amount", "float"),
("time_of_infraction", "decimal", "time_of_infraction", "decimal"),
],
transformation_ctx="ApplyMapping_node2",
)
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="glueparquet",
connection_options={"path": "s3://{{DOC-EXAMPLE-BUCKET}}", "partitionKeys": []},
format_options={"compression": "gzip"},
transformation_ctx="S3bucket_node3",
)
job.commit()
```
**샘플 스크립트 생성**
1. AWS Glue Studio 자습서를 완료합니다. 이 자습서를 완료하려면 [예제 작업을 통해 AWS Glue Studio에서 작업 생성](https://docs.aws.amazon.com/glue/latest/dg/edit-nodes-chapter.html#create-jobs-start.html)을 참조하세요.
1. 다음 스크린샷에 나와 있는 것처럼 작업 페이지의 **Script**(스크립트) 탭으로 이동합니다.
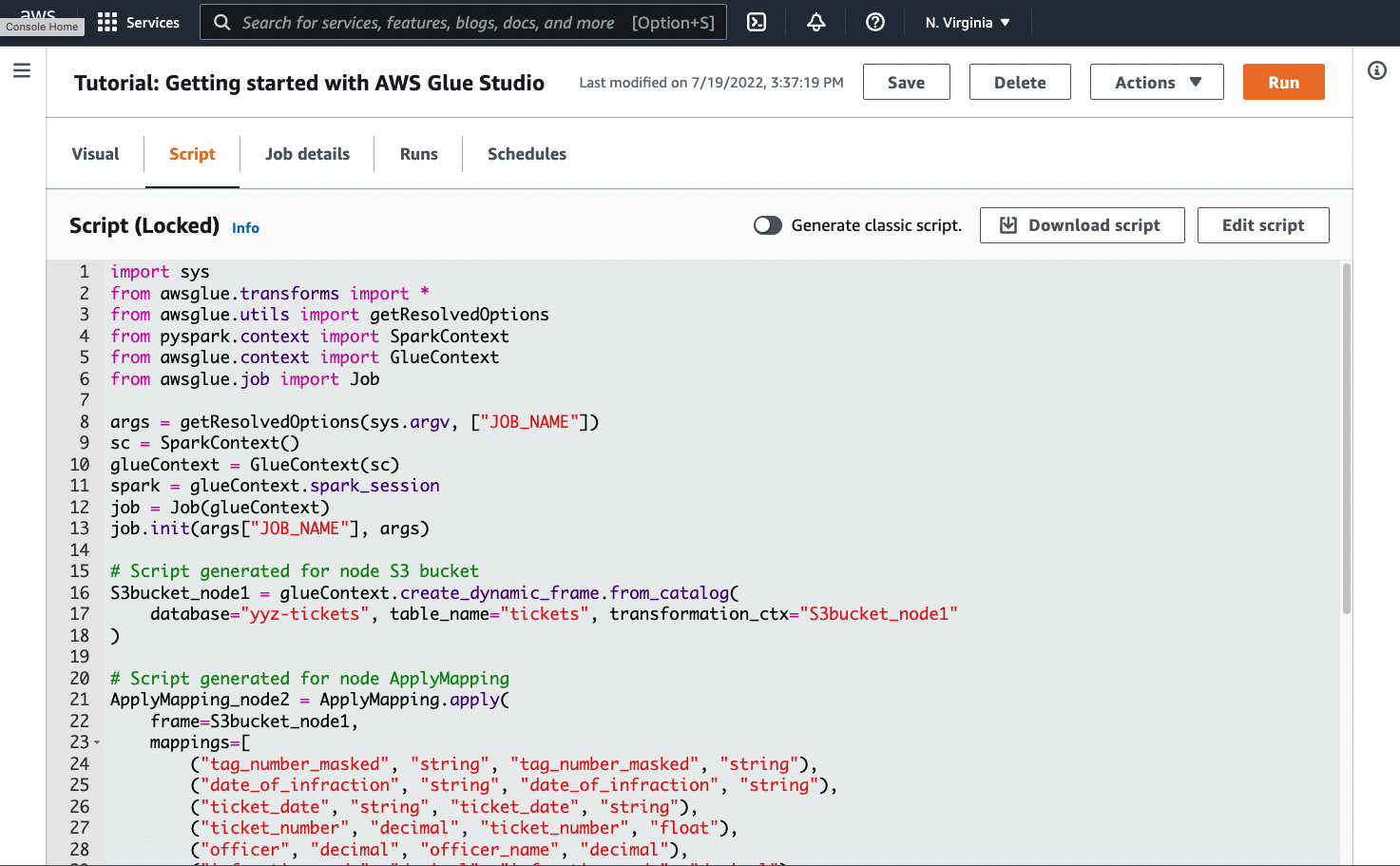
1. **Script**(스크립트) 탭의 전체 내용을 복사합니다. **Job details**(작업 세부 정보)에서 스크립트 언어를 설정하여 Python 또는 Scala 코드 생성 간을 전환할 수 있습니다.
## 1단계. 작업 생성 및 스크립트 붙여넣기
이 단계에서는 AWS Management Console에서 AWS Glue 작업을 생성합니다. 이렇게 하면 AWS Glue에서 스크립트를 실행할 수 있는 구성이 설정됩니다. 또한 스크립트를 저장하고 편집할 수 있는 장소가 생성됩니다.
**작업 생성**
1. AWS Management Console에서 AWS Glue 랜딩 페이지로 이동합니다.
1. 왼쪽 탐색 창에서 **Jobs**(작업)을 선택합니다.
1. **Create job**(작업 생성)에서 **Spark script editor**(Spark 스크립트 편집기)를 선택한 다음 **Create**(생성)을 선택합니다.
1. **선택 사항** - 스크립트의 전체 텍스트를 **Script**(스크립트) 창에 붙여 넣습니다. 자습서를 따라 할 수도 있습니다.
## 2단계. AWS Glue 라이브러리 가져오기
스크립트 외부에 정의된 코드 및 구성과 상호 작용하도록 스크립트를 설정해야 합니다. 이 작업은 AWS Glue Studio에서 백그라운드로 수행됩니다.
이 단계에서 다음 작업을 수행합니다.
+ `GlueContext` 객체를 가져오고 초기화합니다. 이는 스크립트 작성 관점에서 가장 중요한 가져오기입니다. 이를 통해 모든 ETL 스크립트의 시작점인 소스 및 대상 데이터 세트를 정의하기 위한 표준 메서드가 노출됩니다. `GlueContext` 클래스에 대한 자세한 내용을 알아보려면 [GlueContext 클래스](aws-glue-api-crawler-pyspark-extensions-glue-context.md) 섹션을 참조하세요.
+ `SparkContext`와 `SparkSession`을 초기화합니다. 이를 통해 AWS Glue 작업 내에서 사용 가능한 Spark 엔진을 구성할 수 있습니다. 입문용 AWS Glue 스크립트 내에서 이러한 Spark 엔진을 직접 사용할 필요는 없습니다.
+ `getResolvedOptions`를 호출하여 스크립트 내에서 사용할 작업 인수를 준비합니다. 작업 파라미터 확인에 대한 자세한 내용을 알아보려면 [`getResolvedOptions`를 사용한 파라미터 액세스](aws-glue-api-crawler-pyspark-extensions-get-resolved-options.md) 섹션을 참조하세요.
+ `Job`을 초기화합니다. `Job` 객체는 다양한 선택적 AWS Glue 기능에 대한 구성을 설정하고 상태를 추적합니다. 스크립트는 `Job` 객체 없이 실행될 수 있지만, 이러한 기능이 나중에 통합되는 경우 혼동을 피하기 위해 작업을 초기화하는 것이 좋습니다.
이러한 기능 중 하나는 이 자습서에서 선택적으로 구성할 수 있는 작업 북마크입니다. [선택 사항 - 작업 북마크 활성화](#aws-glue-programming-intro-tutorial-create-job-bookmarks) 섹션에서 작업 북마크에 대해 알아볼 수 있습니다.
이 절차에서는 다음 코드를 작성합니다. 이 코드는 생성된 샘플 스크립트의 일부입니다.
```
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
```
**AWS Glue 라이브러리 가져오기**
+ 코드의 이 섹션을 복사하여 **Script**(스크립트) 편집기에 붙여 넣습니다.
**참고**
코드 복사는 잘못된 엔지니어링 관행으로 간주될 수도 있습니다. 이 자습서에서는 모든 AWS Glue ETL 스크립트에서 핵심 변수의 이름을 일관되게 지정하기 위해 이를 권장합니다.
## 3단계. 소스에서 데이터 추출
모든 ETL 프로세스에서 먼저 변경하려는 소스 데이터 세트를 정의해야 합니다. AWS Glue Studio 시각적 편집기에서 **Source**(소스) 노드를 생성하여 이 정보를 제공합니다.
이 단계에서는 AWS Glue Data Catalog에 구성된 소스에서 데이터를 추출할 `database` 및 `table_name`을(를) `create_dynamic_frame.from_catalog` 메서드에 제공합니다.
전 단계에서 `GlueContext` 객체를 초기화했습니다. 이 객체를 사용하여 소스를 구성하는 데 사용되는 `create_dynamic_frame.from_catalog`와(과) 같은 메서드를 찾습니다.
이 절차에서는 `create_dynamic_frame.from_catalog`를 사용하여 다음 코드를 작성합니다. 이 코드는 생성된 샘플 스크립트의 일부입니다.
```
S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog(
database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1"
)
```
**소스에서 데이터 추출**
1. 설명서를 검토하여 `GlueContext`에서 AWS Glue 데이터 카탈로그에 정의된 소스에서 데이터를 추출하는 메서드를 찾습니다. 이러한 메서드는 [GlueContext 클래스](aws-glue-api-crawler-pyspark-extensions-glue-context.md)에 문서화되어 있습니다. [create\_dynamic\_frame.from\_catalog](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-create_dynamic_frame_from_catalog) 메서드를 선택합니다. `glueContext`에서 이 메서드를 호출합니다.
1. 설명서에서 `create_dynamic_frame.from_catalog`를 검토합니다. 이 메서드에는 `database` 및 `table_name` 파라미터가 필요합니다. `create_dynamic_frame.from_catalog`에 필요한 파라미터를 제공합니다.
AWS Glue 데이터 카탈로그는 소스 데이터의 위치와 형식에 대한 정보를 저장하며 사전 조건 섹션에서 설정되었습니다. 스크립트에 해당 정보를 직접 제공할 필요는 없습니다.
1. **선택 사항** – 작업 책갈피를 지원하려면 메서드에 `transformation_ctx` 파라미터를 제공합니다. [선택 사항 - 작업 북마크 활성화](#aws-glue-programming-intro-tutorial-create-job-bookmarks) 섹션에서 작업 북마크에 대해 알아볼 수 있습니다.
**참고**
**데이터를 추출하는 데 일반적으로 사용되는 메서드**
[create\_dynamic\_frame\_from\_catalog](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-create_dynamic_frame_from_catalog)는 AWS Glue 데이터 카탈로그의 테이블에 연결하는 데 사용됩니다.
소스의 구조와 위치를 설명하는 구성을 작업에 직접 제공해야 하는 경우 [create\_dynamic\_frame\_from\_options](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-create_dynamic_frame_from_options) 메서드를 참조하세요. `create_dynamic_frame.from_catalog`를 사용할 때보다 데이터를 설명하는 더 자세한 파라미터를 제공해야 합니다.
필요한 파라미터를 식별하려면 `format_options` 및 `connection_parameters`에 대한 보충 문서를 참조하세요. 소스 데이터 형식에 대한 스크립트 정보를 제공하는 방법에 대한 설명을 보려면 [AWS Glue for Spark에서 입력 및 출력의 데이터 형식 옵션](aws-glue-programming-etl-format.md) 섹션을 참조하세요. 소스 데이터 위치에 대한 스크립트 정보를 제공하는 방법에 대한 설명을 보려면 [AWS Glue for Spark에서 ETL에 대한 연결 유형 및 옵션](aws-glue-programming-etl-connect.md) 섹션을 참조하세요.
스트리밍 소스에서 정보를 읽는 경우 [create\_data\_frame\_from\_catalog](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-create-dataframe-from-catalog) 또는 [create\_data\_frame\_from\_options](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-create-dataframe-from-options) 메서드를 통해 소스 정보를 작업에 제공합니다. 이러한 메서드는 Apache Spark `DataFrames`를 반환합니다.
생성된 코드는 `create_dynamic_frame.from_catalog`를 호출하는 반면 참조 문서는 `create_dynamic_frame_from_catalog`를 참조합니다. 이러한 메서드는 최종적으로 동일한 코드를 호출하며 더 깔끔한 코드를 작성할 수 있도록 포함되어 있습니다. [https://github.com/awslabs/aws-glue-libs/blob/master/awsglue/context.py](https://github.com/awslabs/aws-glue-libs/blob/master/awsglue/context.py)에서 제공되는 Python 래퍼의 소스를 보고 이를 확인할 수 있습니다.
## 4단계. AWS Glue로 데이터 변환
ETL 프로세스에서 소스 데이터를 추출한 후 데이터를 어떻게 변경할지 설명해야 합니다. AWS Glue Studio 시각적 편집기에서 **Transform**(변환) 노드를 생성하여 이 정보를 제공합니다.
이 단계에서는 `ApplyMapping` 메서드에 현재 필드 이름 및 유형과 원하는 필드 이름 및 유형의 맵을 제공하여 `DynamicFrame`을(를) 변환합니다.
다음 변환을 수행할 수 있습니다.
+ 4개의 `location` 및 `province` 키를 삭제합니다.
+ `officer`의 이름을 `officer_name`으로 변경합니다.
+ `ticket_number`와 `set_fine_amount`의 유형을 `float`로 변경합니다.
`create_dynamic_frame.from_catalog`가 `DynamicFrame` 객체를 제공합니다. `DynamicFrame`은 AWS Glue의 데이터 세트를 나타냅니다. AWS Glue 변환은 `DynamicFrames`를 변경하는 작업입니다.
**참고**
`DynamicFrame`란 무엇입니까?
`DynamicFrame`은 데이터에 있는 항목의 이름 및 유형에 대한 설명과 함께 데이터 세트를 연결할 수 있는 추상화입니다. Apache Spark에는 DataFrame이라는 유사한 추상화가 있습니다. DataFrames에 대한 설명을 보려면 [Spark SQL Guide](https://spark.apache.org/docs/latest/sql-programming-guide.html)(Spark SQL 가이드)를 참조하세요.
`DynamicFrames`을(를) 사용하면 데이터 세트 스키마를 동적으로 설명할 수 있습니다. 일부 항목은 가격을 문자열로 저장하고 다른 항목은 가격을 실수(double)로 저장하는 가격 열이 있는 데이터세트를 예로 들어 보겠습니다. AWS Glue는 즉석에서 스키마를 계산하여 각 행에 대한 자체 설명 레코드를 생성합니다.
가격과 같은 불일치 필드는 프레임 스키마에서 유형(`ChoiceType`)으로 명시적으로 표시됩니다. 불일치 필드는 `DropFields`(으)로 삭제하거나 `ResolveChoice`(으)로 확인하여 해결할 수 있습니다. 다음은 `DynamicFrame`에서 사용할 수 있는 변환입니다. 그런 다음 `writeDynamicFrame`을 사용하여 데이터를 데이터 레이크에 다시 쓸 수 있습니다.
`DynamicFrame` 클래스의 메서드에서 동일한 변환을 많이 호출할 수 있으므로 스크립트를 더 쉽게 읽을 수 있습니다. `DynamicFrame`에 대한 자세한 정보는 [DynamicFrame 클래스](aws-glue-api-crawler-pyspark-extensions-dynamic-frame.md) 섹션을 참조하세요.
이 절차에서는 `ApplyMapping`를 사용하여 다음 코드를 작성합니다. 이 코드는 생성된 샘플 스크립트의 일부입니다.
```
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("tag_number_masked", "string", "tag_number_masked", "string"),
("date_of_infraction", "string", "date_of_infraction", "string"),
("ticket_date", "string", "ticket_date", "string"),
("ticket_number", "decimal", "ticket_number", "float"),
("officer", "decimal", "officer_name", "decimal"),
("infraction_code", "decimal", "infraction_code", "decimal"),
("infraction_description", "string", "infraction_description", "string"),
("set_fine_amount", "decimal", "set_fine_amount", "float"),
("time_of_infraction", "decimal", "time_of_infraction", "decimal"),
],
transformation_ctx="ApplyMapping_node2",
)
```
**AWS Glue로 데이터 변환**
1. 설명서를 검토하여 필드를 변경하고 삭제하는 변환을 식별합니다. 자세한 내용은 [GlueTransform 베이스 클래스](aws-glue-api-crawler-pyspark-transforms-GlueTransform.md)을 참조하세요. `ApplyMapping` 변환을 선택합니다. `ApplyMapping`에 대한 자세한 정보는 [ApplyMapping 클래스](aws-glue-api-crawler-pyspark-transforms-ApplyMapping.md) 섹션을 참조하세요. `ApplyMapping` 변환 객체에서 `apply`를 호출합니다.
**참고**
`ApplyMapping`이란 무엇인가요?
`ApplyMapping`은 `DynamicFrame`을 가져와서 변환합니다. 이는 필드의 변환을 나타내는 튜플 목록인 '매핑'을 가져옵니다. 처음 두 튜플 요소인 필드 이름과 유형은 프레임에서 필드를 식별하는 데 사용됩니다. 두 번째 두 파라미터는 필드 이름과 유형이기도 합니다.
ApplyMapping은 소스 필드를 대상 이름으로 변환하고 반환할 새 `DynamicFrame`을(를) 입력합니다. 제공되지 않은 필드는 반환 값에서 삭제됩니다.
`apply`를 호출하는 대신 `DynamicFrame`에서 `apply_mapping` 메서드로 동일한 변환을 호출하여 보다 매끄럽고 읽기 쉬운 코드를 생성할 수 있습니다. 자세한 내용은 [apply\_mapping](aws-glue-api-crawler-pyspark-extensions-dynamic-frame.md#aws-glue-api-crawler-pyspark-extensions-dynamic-frame-apply_mapping) 섹션을 참조하세요.
1. 설명서에서 `ApplyMapping`을 검토하여 필수 파라미터를 식별합니다. [ApplyMapping 클래스](aws-glue-api-crawler-pyspark-transforms-ApplyMapping.md)을(를) 참조하세요. 이 메서드에는 `frame` 및 `mappings` 파라미터가 필요합니다. `ApplyMapping`에 필요한 파라미터를 제공합니다.
1. **선택 사항** – 작업 책갈피를 지원하려면 메서드에 `transformation_ctx`을(를) 제공합니다. [선택 사항 - 작업 북마크 활성화](#aws-glue-programming-intro-tutorial-create-job-bookmarks) 섹션에서 작업 북마크에 대해 알아볼 수 있습니다.
**참고**
**Apache Spark 기능**
작업 내에서 ETL 워크플로를 간소화하기 위한 변환을 제공합니다. 또한 작업 중에 보다 일반적인 용도로 구축된 Spark 프로그램에서 사용할 수 있는 라이브러리에 액세스할 수 있습니다. 이러한 라이브러리를 사용하기 위해 `DynamicFrame`와(과) `DataFrame` 간을 변환합니다.
[toDF](aws-glue-api-crawler-pyspark-extensions-dynamic-frame.md#aws-glue-api-crawler-pyspark-extensions-dynamic-frame-toDF)(으)로 `DataFrame`을(를) 생성할 수 있습니다. 그런 다음 DataFrame에서 사용 가능한 메서드를 사용하여 데이터 세트를 변환할 수 있습니다. 이러한 메서드에 대한 자세한 내용을 알아보려면 [DataFrame](https://spark.apache.org/docs/3.1.1/api/python/reference/api/pyspark.sql.DataFrame.html)을 참조하세요. 그런 다음 [fromDF](aws-glue-api-crawler-pyspark-extensions-dynamic-frame.md#aws-glue-api-crawler-pyspark-extensions-dynamic-frame-fromDF)(으)로 역방향으로 변환하여 대상에 프레임을 로드하는 데 AWS Glue 작업을 사용할 수 있습니다.
## 5단계. 대상에 데이터 로드
데이터를 변환한 후 일반적으로 변환된 데이터를 소스와 다른 장소에 저장합니다. AWS Glue Studio 시각적 편집기에서 **target**(대상) 노드를 생성하여 이 작업을 수행합니다.
이 단계에서는 `write_dynamic_frame.from_options` 메서드에 `connection_type`, `connection_options`, `format` 및 `format_options`을(를) 제공하여 Amazon S3의 대상 버킷에 데이터를 로드합니다.
1단계에서 `GlueContext` 객체를 초기화했습니다. AWS Glue의 경우 여기에서 소스와 마찬가지로 대상을 구성하는 데 사용되는 메서드를 찾을 수 있습니다.
이 절차에서는 `write_dynamic_frame.from_options`를 사용하여 다음 코드를 작성합니다. 이 코드는 생성된 샘플 스크립트의 일부입니다.
```
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="glueparquet",
connection_options={"path": "s3://{{amzn-s3-demo-bucket}}", "partitionKeys": []},
format_options={"compression": "gzip"},
transformation_ctx="S3bucket_node3",
)
```
**대상에 데이터 로드**
1. 설명서를 검토하여 대상 Amazon S3 버킷에 데이터를 로드하는 방법을 찾습니다. 이러한 메서드는 [GlueContext 클래스](aws-glue-api-crawler-pyspark-extensions-glue-context.md)에 문서화되어 있습니다. [write\_dynamic\_frame\_from\_options](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-write_dynamic_frame_from_options) 메서드를 선택합니다. `glueContext`에서 이 메서드를 호출합니다.
**참고**
**데이터를 로드하는 데 일반적으로 사용되는 메서드**
`write_dynamic_frame.from_options`는 데이터를 로드하는 데 가장 일반적으로 사용되는 메서드로서, AWS Glue에서 사용 가능한 모든 대상을 지원합니다.
AWS Glue 연결에 정의된 JDBC 대상에 쓰는 경우 [write\_dynamic\_frame\_from\_jdbc\_conf](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-write_dynamic_frame_from_jdbc_conf) 메서드를 사용합니다. AWS Glue 연결은 데이터 소스에 연결하는 방법에 대한 정보를 저장합니다. 이렇게 하면 해당 정보를 `connection_options`에 제공할 필요가 없습니다. 그러나 `dbtable`을(를) 제공하려면 여전히 `connection_options`을(를) 사용해야 합니다.
`write_dynamic_frame.from_catalog`는 데이터를 로드하는 데 일반적으로 사용되는 메서드가 아닙니다. 이 메서드는 기본 데이터 세트를 업데이트하지 않고 AWS Glue 데이터 카탈로그를 업데이트하며 기본 데이터 세트를 변경하는 다른 프로세스와 함께 사용됩니다. 자세한 내용은 [AWS Glue ETL 작업을 사용하여 데이터 카탈로그에서 스키마 업데이트 및 새 파티션 추가](update-from-job.md) 섹션을 참조하세요.
1. 설명서에서 [write\_dynamic\_frame\_from\_options](aws-glue-api-crawler-pyspark-extensions-glue-context.md#aws-glue-api-crawler-pyspark-extensions-glue-context-write_dynamic_frame_from_options)를 검토합니다. 이 메서드에는 `frame`, `connection_type`, `format`, `connection_options` 및 `format_options`이(가) 필요합니다. `glueContext`에서 이 메서드를 호출합니다.
1. 필요한 파라미터를 식별하려면 `format_options`와 `format`에 대한 보충 문서를 참조하세요. 데이터 형식에 대한 설명을 보려면 [AWS Glue for Spark에서 입력 및 출력의 데이터 형식 옵션](aws-glue-programming-etl-format.md) 섹션을 참조하세요.
1. 필요한 파라미터를 식별하려면 `connection_type`와 `connection_options`에 대한 보충 문서를 참조하세요. 연결에 대한 설명을 보려면 [AWS Glue for Spark에서 ETL에 대한 연결 유형 및 옵션](aws-glue-programming-etl-connect.md) 섹션을 참조하세요.
1. `write_dynamic_frame.from_options`에 필요한 파라미터를 제공합니다. 이 메서드는 `create_dynamic_frame.from_options`와(과) 유사한 구성을 가지고 있습니다.
1. **선택 사항** – 작업 책갈피를 지원하려면 `write_dynamic_frame.from_options`에 `transformation_ctx`을(를) 제공합니다. [선택 사항 - 작업 북마크 활성화](#aws-glue-programming-intro-tutorial-create-job-bookmarks) 섹션에서 작업 북마크에 대해 알아볼 수 있습니다.
## 6단계. `Job` 객체 커밋
1단계에서 `Job` 객체를 초기화했습니다. 작업 북마크를 사용하는 경우와 같이 특정 선택적 기능이 제대로 작동하려면 스크립트가 끝날 때 수명 주기를 수동으로 종료해야 할 수 있습니다. 이 작업은 AWS Glue Studio에서 백그라운드로 수행됩니다.
이 단계에서는 `Job` 객체에 대한 `commit` 메서드를 호출합니다.
이 절차에서는 다음 코드를 작성합니다. 이 코드는 생성된 샘플 스크립트의 일부입니다.
```
job.commit()
```
**`Job` 객체 커밋**
1. 이 단계를 아직 수행하지 않은 경우 이전 섹션에 설명된 선택적 단계를 수행하여 `transformation_ctx`을(를) 포함합니다.
1. `commit`를 호출합니다.
## 선택 사항 - 작업 북마크 활성화
모든 이전 단계에서 `transformation_ctx` 파라미터를 설정하라는 지시를 받았습니다. 이는 작업 북마크라는 기능과 관련이 있습니다.
작업 북마크를 사용하면 이전 작업을 쉽게 추적할 수 있는 데이터 세트에 대해 반복적으로 실행되는 작업을 통해 시간과 비용을 절약할 수 있습니다. 작업 북마크는 이전 실행의 데이터 세트에서 AWS Glue 변환의 진행 상황을 추적합니다. AWS Glue는 이전 실행이 끝난 위치를 추적하여 이전에 처리하지 않은 행으로 작업을 제한할 수 있습니다. 작업 북마크에 대한 자세한 내용을 알아보려면 [처리된 데이터를 작업 북마크로 추적](monitor-continuations.md)을(를) 참조하세요.
작업 북마크를 활성화하려면 먼저 이전 예제에서 설명한 대로 제공된 함수에 `transformation_ctx` 문을 추가합니다. 작업 북마크 상태는 실행 시에도 유지됩니다. `transformation_ctx` 파라미터는 해당 상태에 액세스하는 데 사용되는 키입니다. 이러한 문은 그 자체로는 아무 것도 하지 않습니다. 작업에 대한 구성에서도 기능을 활성화해야 합니다.
이 절차에서는 AWS Management Console을(를) 사용하여 작업 북마크를 활성화합니다.
**작업 북마크 활성화**
1. 해당 작업의 **Job details**(작업 세부 정보) 섹션으로 이동합니다.
1. **Job bookmark**(작업 북마크)를 **Enable**(활성화)로 설정합니다.
## 7단계. 코드를 작업으로 실행
이 단계에서는 작업을 실행하여 이 자습서를 성공적으로 완료했는지 확인합니다. 이 작업은 AWS Glue Studio 시각적 편집기에서와 같이 버튼 클릭으로 수행됩니다.
**코드를 작업으로 실행**
1. 제목 표시줄에서 **Untitled job**(제목 없는 작업)을 선택하여 작업 이름을 편집하고 설정합니다.
1. **Job details**(작업 세부 정보) 탭으로 이동합니다. 작업에 **IAM Role**(IAM 역할)을 할당합니다. AWS Glue Studio 자습서의 사전 조건에서 CloudFormation 템플릿으로 생성한 역할을 사용할 수 있습니다. 해당 자습서를 완료했다면 `AWS Glue StudioRole`을 사용할 수 있습니다.
1. **Save**(저장)를 선택하여 스크립트를 저장합니다.
1. **Run**(실행)을 선택하여 작업을 실행합니다.
1. **Runs**(실행) 탭으로 이동하여 작업이 완료되었는지 확인합니다.
1. `write_dynamic_frame.from_options`의 대상인 {{amzn-s3-demo-bucket}}으로 이동합니다. 출력이 예상과 일치하는지 확인합니다.
작업 구성 및 관리에 대한 자세한 내용을 알아보려면 [사용자 지정 스크립트 제공](console-custom-created.md)을(를) 참조하세요.
## 추가 정보
Apache Spark 라이브러리 및 메서드는 AWS Glue 스크립트에서 사용할 수 있습니다. 포함된 라이브러리로 수행할 수 있는 작업을 알아보려면 Spark 설명서를 참조하세요. 자세한 내용을 알아보려면 [Spark 소스 리포지토리의 예제 섹션](https://github.com/apache/spark/tree/master/examples/src/main/python)을 참조하세요.
AWS Glue 2.0\+에는 기본적으로 몇 가지 일반적인 Python 라이브러리가 포함되어 있습니다. Scala 또는 Python 환경의 AWS Glue 작업에 자체 종속성을 로드하는 메커니즘도 있습니다. Python 종속성에 대한 내용을 알아보려면 [AWS Glue와 함께 Python 라이브러리 사용](aws-glue-programming-python-libraries.md)을(를) 참조하세요.
Python에서 AWS Glue 기능을 사용하는 방법에 대한 더 많은 예제를 알아보려면 [AWS Glue Python 코드 샘플](aws-glue-programming-python-samples.md)을(를) 참조하세요. Scala 및 Python 작업은 기능 패리티가 있으므로 Python 예제를 통해 Scala에서 비슷한 작업을 수행하는 방법을 알아볼 수 있습니다.