Spark DataFrame이 지원되는 DynamoDB 커넥터
Spark DataFrame이 지원되는 DynamoDB 커넥터를 사용하면 Spark DataFrame API를 사용하여 DynamoDB의 테이블에서 읽고 쓸 수 있습니다. 커넥터 설정 단계는 DynamicFrame 기반 커넥터와 동일하며 여기에서 찾을 수 있습니다.
DataFrame 기반 커넥터 라이브러리에서 로드하려면 DynamoDB 연결을 Glue 작업에 연결해야 합니다.
참고
Glue 콘솔 UI는 현재 DynamoDB 연결 생성을 지원하지 않습니다. Glue CLI(CreateConnection)를 사용하여 DynamoDB 연결을 생성할 수 있습니다.
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
DynamoDB 연결 생성 시 CLI(CreateJob, UpdateJob)를 통해 또는 ‘작업 세부 정보’ 페이지에서 이 연결을 직접 Glue 작업에 연결할 수 있습니다.
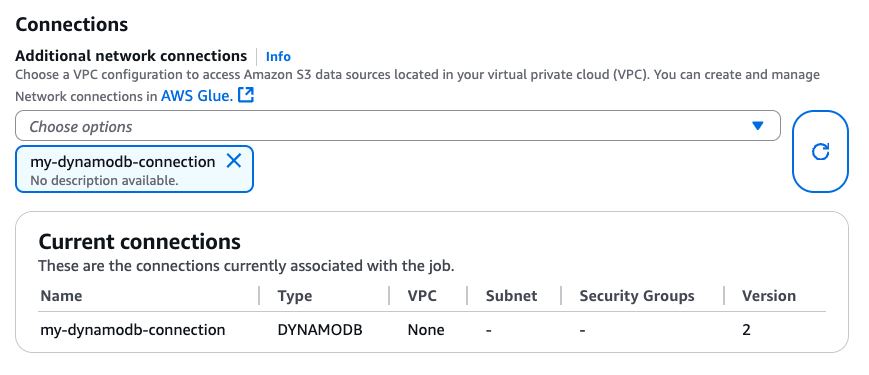
DYNAMODB 유형과의 연결이 Glue 작업에 연결되도록 하면 DataFrame 기반 커넥터에서 다음과 같은 읽기, 쓰기, 내보내기 작업을 활용할 수 있습니다.
DataFrame 기반 커넥터를 사용하여 DynamoDB에서 읽기 및 쓰기
다음 코드 예제는 DataFrame 기반 커넥터를 통해 DynamoDB 테이블에서 읽고 쓰는 방법을 보여줍니다. 한 테이블에서 읽고 다른 테이블에 쓰는 것을 보여줍니다.
DataFrame 기반 커넥터를 통한 DynamoDB 내보내기 사용
80GB보다 큰 DynamoDB 테이블의 경우 읽기 작업보다 내보내기 작업이 선호됩니다. 다음 코드 예제는 테이블에서 읽고, S3로 내보내고, DataFrame 기반 커넥터를 통해 파티션 수를 인쇄하는 방법을 보여줍니다.
참고
DynamoDB 내보내기 기능은 Scala DynamoDBExport 객체를 통해 사용할 수 있습니다. Python 사용자는 Spark의 JVM 인터럽을 통해 액세스하거나 DynamoDB ExportTableToPointInTime API와 함께 AWS SDK for Python(Boto3)을 사용할 수 있습니다.
구성 옵션
읽기 옵션
| 옵션 | 설명 | 기본값 |
|---|---|---|
dynamodb.input.tableName |
DynamoDB 테이블 이름(필수) | - |
dynamodb.throughput.read |
사용할 읽기 용량 단위(RCU)입니다. 지정하지 않으면 dynamodb.throughput.read.ratio가 계산에 사용됩니다. |
- |
dynamodb.throughput.read.ratio |
사용할 읽기 용량 단위(RCU)의 비율 | 0.5 |
dynamodb.table.read.capacity |
처리량을 계산하는 데 사용되는 온디맨드 테이블의 읽기 용량입니다. 이 파라미터는 온디맨드 용량 테이블에서만 유효합니다. 기본값은 웜 처리량 읽기 단위입니다. | - |
dynamodb.splits |
병렬 스캔 작업에 사용되는 세그먼트 수를 정의합니다. 제공하지 않으면 커넥터가 적절한 기본값을 계산합니다. | - |
dynamodb.consistentRead |
강력하게 일관된 읽기 사용 여부 | FALSE |
dynamodb.input.retry |
재시도 가능한 예외가 있을 때 수행하는 재시도 횟수를 정의합니다. | 10 |
쓰기 옵션
| 옵션 | 설명 | 기본값 |
|---|---|---|
dynamodb.output.tableName |
DynamoDB 테이블 이름(필수) | - |
dynamodb.throughput.write |
사용할 쓰기 용량 단위(WCU)입니다. 지정하지 않으면 dynamodb.throughput.write.ratio가 계산에 사용됩니다. |
- |
dynamodb.throughput.write.ratio |
사용할 쓰기 용량 단위(WCU)의 비율 | 0.5 |
dynamodb.table.write.capacity |
처리량을 계산하는 데 사용되는 온디맨드 테이블의 쓰기 용량입니다. 이 파라미터는 온디맨드 용량 테이블에서만 유효합니다. 기본값은 웜 처리량 쓰기 단위입니다. | - |
dynamodb.item.size.check.enabled |
true인 경우 커넥터는 항목 크기를 계산하고 크기가 최대 크기를 초과하면 항목을 DynamoDB 테이블에 쓰기 전에 중단합니다. | TRUE |
dynamodb.output.retry |
재시도 가능한 예외가 있을 때 수행하는 재시도 횟수를 정의합니다. | 10 |
내보내기 옵션
| 옵션 | 설명 | 기본값 |
|---|---|---|
dynamodb.export |
ddb로 설정하면 AWS Glue 작업 중에 새 ExportTableToPointInTimeRequet가 간접적으로 호출되는 AWS Glue DynamoDB 내보내기 커넥터가 활성화됩니다. dynamodb.s3.bucket 및 dynamodb.s3.prefix에서 전달된 위치로 새 내보내기가 생성됩니다. s3로 설정하면 AWS Glue DynamoDB 내보내기 커넥터가 활성화되지만, 새 DynamoDB 내보내기 생성을 건너뛰고 대신 dynamodb.s3.bucket 및 dynamodb.s3.prefix를 해당 테이블의 과거 내보내기 Amazon S3 위치로 사용합니다. |
ddb |
dynamodb.tableArn |
읽을 DynamoDB 테이블입니다. dynamodb.export이 ddb로 설정된 경우 필수입니다. |
|
dynamodb.simplifyDDBJson |
true로 설정하면 변환을 수행하여 내보내기에 있는 DynamoDB JSON 구조의 스키마를 간소화합니다. |
FALSE |
dynamodb.s3.bucket |
DynamoDB 내보내기 중에 임시 데이터를 저장할 S3 버킷(필수) | |
dynamodb.s3.prefix |
DynamoDB 내보내기 중에 임시 데이터를 저장할 S3 접두사 | |
dynamodb.s3.bucketOwner |
교차 계정 Amazon S3 액세스를 위해 필요한 버킷 소유자를 나타냅니다. | |
dynamodb.s3.sse.algorithm |
임시 데이터가 저장될 버킷에 사용되는 암호화 유형입니다. 유효 값은 AES256 및 KMS입니다. |
|
dynamodb.s3.sse.kmsKeyId |
임시 데이터가 저장될 S3 버킷을 암호화하는 데 사용되는 AWS KMS 관리형 키의 ID입니다(해당하는 경우). | |
dynamodb.exportTime |
내보내기를 수행해야 하는 시점입니다. 유효 값: ISO-8601 인스턴트를 나타내는 문자열. |
일반 옵션
| 옵션 | 설명 | 기본값 |
|---|---|---|
dynamodb.sts.roleArn |
교차 계정 액세스를 위해 수임할 IAM 역할 ARN | - |
dynamodb.sts.roleSessionName |
STS 세션 이름 | glue-dynamodb-sts-session |
dynamodb.sts.region |
STS 클라이언트의 리전(교차 리전 역할 수임용) | region 옵션과 동일 |
