이 페이지 개선에 도움 주기
이 사용자 가이드에 기여하려면 모든 페이지의 오른쪽 창에 있는 GitHub에서 이 페이지 편집 링크를 선택합니다.
Amazon EKS에서 Amazon Application Recovery Controller(ARC)의 영역 전환에 대해 알아보기
Kubernetes에는 가용 영역(AZ)의 상태 저하 또는 손상과 같은 이벤트에 대해 애플리케이션을 보다 탄력적으로 만들 수 있는 기본 기능이 있습니다. Amazon EKS 클러스터에서 워크로드를 실행하는 경우때 Amazon Application Recovery Controller(ARC) 영역 전환 또는 영역 자동 전환을 사용하여 애플리케이션 환경의 내결함성 및 애플리케이션 복구를 추가적으로 개선할 수 있습니다. ARC 영역 전환은 영역 전환이 만료되거나 사용자가 이를 취소할 때까지 리소스에 대한 트래픽을 장애가 발생한 AZ에서 다른 위치로 이전할 수 있는 임시 조치로 설계되었습니다. 필요한 경우 영역 전환을 확장할 수 있습니다.
EKS 클러스터에 대한 영역 전환을 시작하거나 영역 자동 전환을 활성화하여 AWS가 대신 수행하도록 허용할 수 있습니다. 이 변경은 클러스터의 동서 네트워크 트래픽 흐름을 업데이트하여 정상 AZ의 워커 노드에서 실행 중인 포드에 대한 네트워크 엔드포인트만 고려하도록 합니다. 또한 EKS 클러스터의 애플리케이션에 대한 인그레스 트래픽을 처리하는 모든 ALB 또는 NLB는 트래픽을 정상 AZ의 타깃으로 자동 라우팅합니다. 고가용성 목표를 추구하는 고객의 경우, AZ가 장애가 발생하는 경우 복구될 때까지 모든 트래픽을 장애가 발생한 AZ로부터 멀리 이동시키는 것이 중요할 수 있습니다. 이를 위해 ARC 영역 전환을 사용하여 ALB 또는 NLB를 활성화할 수도 있습니다.
포드 간 동서 네트워크 트래픽 흐름 이해
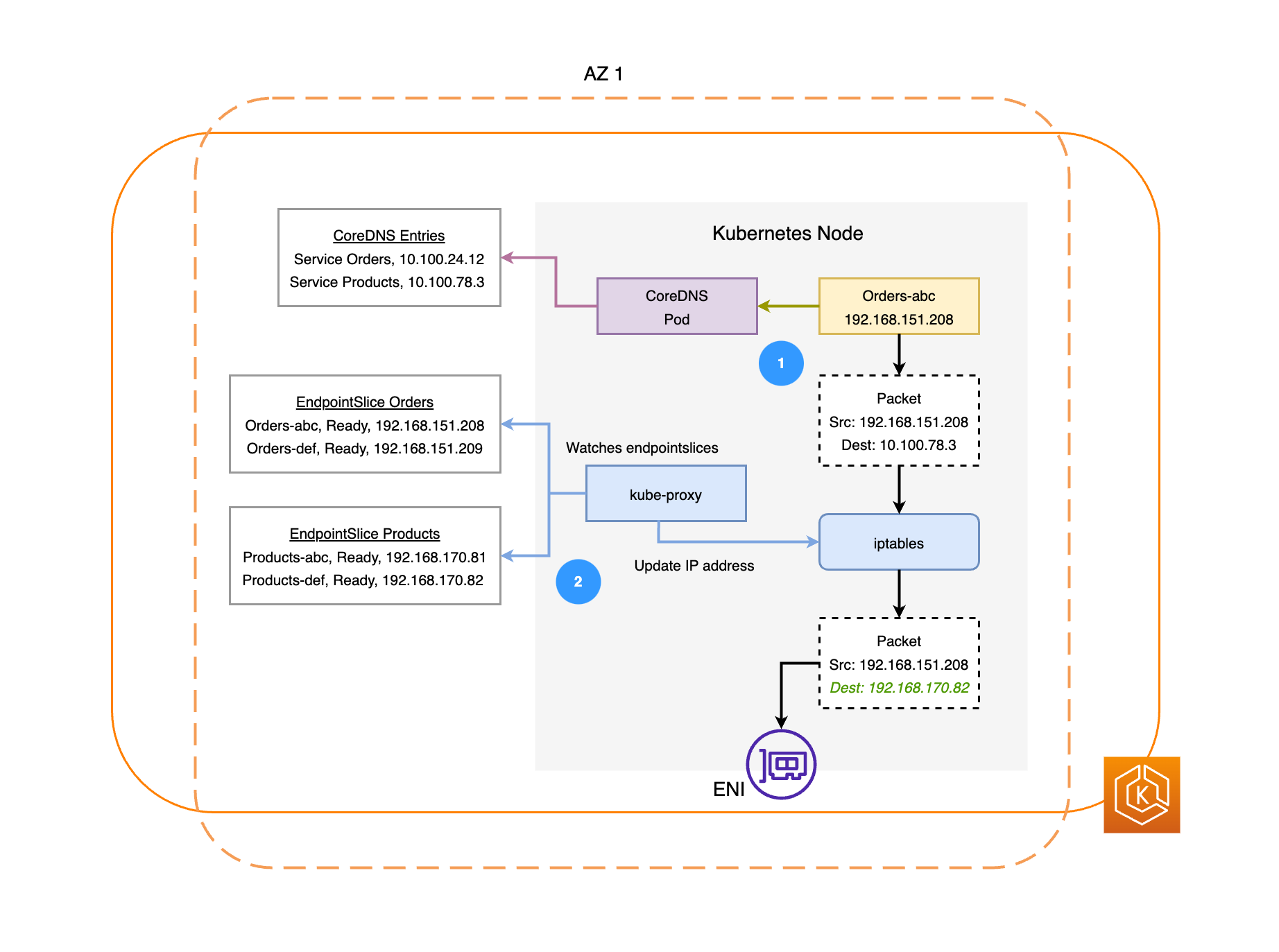
다음 다이어그램은 주문과 제품이라는 두 가지 워크로드 예시를 보여줍니다. 이 예시의 목적은 서로 다른 AZ의 워크로드와 포드가 통신하는 방법을 보여주기 위한 것이다.
-
주문이 제품과 통신하려면 먼저 주문에서 대상 서비스의 DNS 이름을 확인해야 합니다. 주문은 CoreDNS와 통신하여 해당 서비스의 가상 IP 주소(클러스터 IP)를 가져옵니다. 주문이 제품 서비스 이름을 확인하면 해당 대상 IP로 트래픽을 전송합니다.
-
kube-proxy는 클러스터의 모든 노드에서 실행되며 서비스의 EndpointSlices
를 지속적으로 감시합니다. 서비스가 생성되면 EndpointSlice 컨트롤러에 의해 백그라운드에서 EndpointSlice가 생성 및 관리됩니다. 각 EndpointSlice에는 엔드포인트가 실행 중인 노드와 함께 포드 주소의 하위 집합을 포함하는 엔드포인트 목록 또는 테이블이 있습니다. kube-proxy는 노드에서 iptables를 사용하여 이러한 각 Pod 엔드포인트에 대한 라우팅 규칙을 설정합니다. 또한 kube-proxy는 서비스의 클러스터 IP로 향하는 트래픽을 대신 포드의 IP 주소로 직접 전송하도록 리디렉션하여 기본적인 형태의 로드 밸런싱도 담당합니다. kube-proxy는 발신 연결에서 대상 IP 주소를 다시 작성하여 이를 수행합니다. -
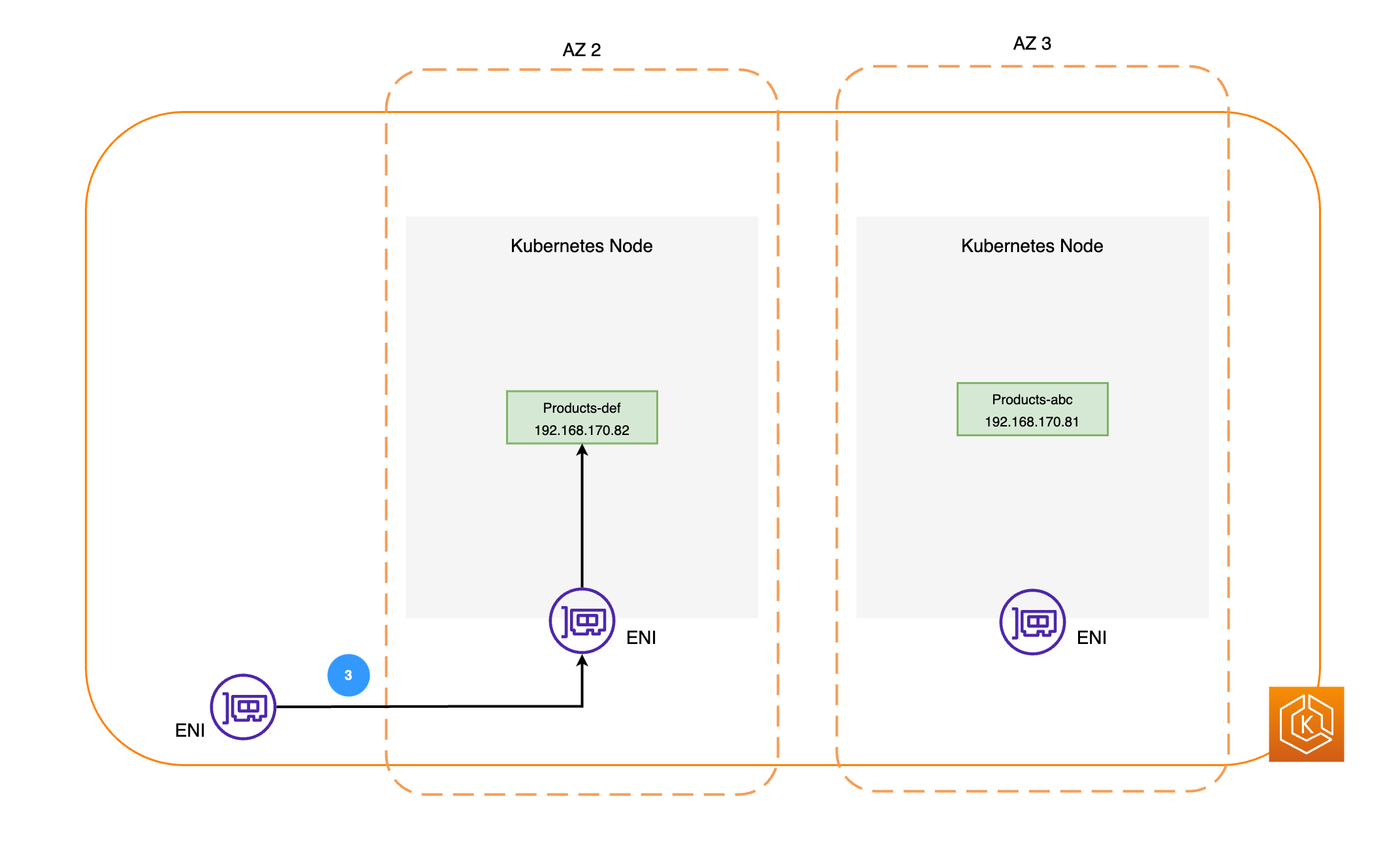
그런 다음 위 다이어그램에 표시된 대로 각 노드의 ENI를 사용하여 AZ 2의 제품 포드로 네트워크 패킷이 전송됩니다.
Amazon EKS에서 ARC 영역 전환 이해
사용자 환경에 AZ 장애가 있는 경우 EKS 클러스터 환경에 대한 영역 전환을 시작할 수 있습니다. 또는 AWS가 영역 자동 전환을 사용하여 트래픽 전환을 관리하도록 허용할 수 있습니다. 영역 자동 전환을 사용하면 AWS는 클러스터 환경에서 장애가 발생한 AZ에서 다른 위치로 트래픽을 자동으로 전환하여 전체 AZ 상태를 모니터링하고 잠재적인 AZ 장애에 대응합니다.
Amazon EKS 클러스터에서 ARC로 영역 전환이 활성화된 후, ARC 콘솔, AWS CLI 또는 영역 전환 및 영역 자동 전환 API를 사용하여 영역 전환을 시작하거나 영역 자동 전환을 활성화할 수 있습니다. EKS 영역 전환 중에는 다음이 자동으로 수행됩니다.
-
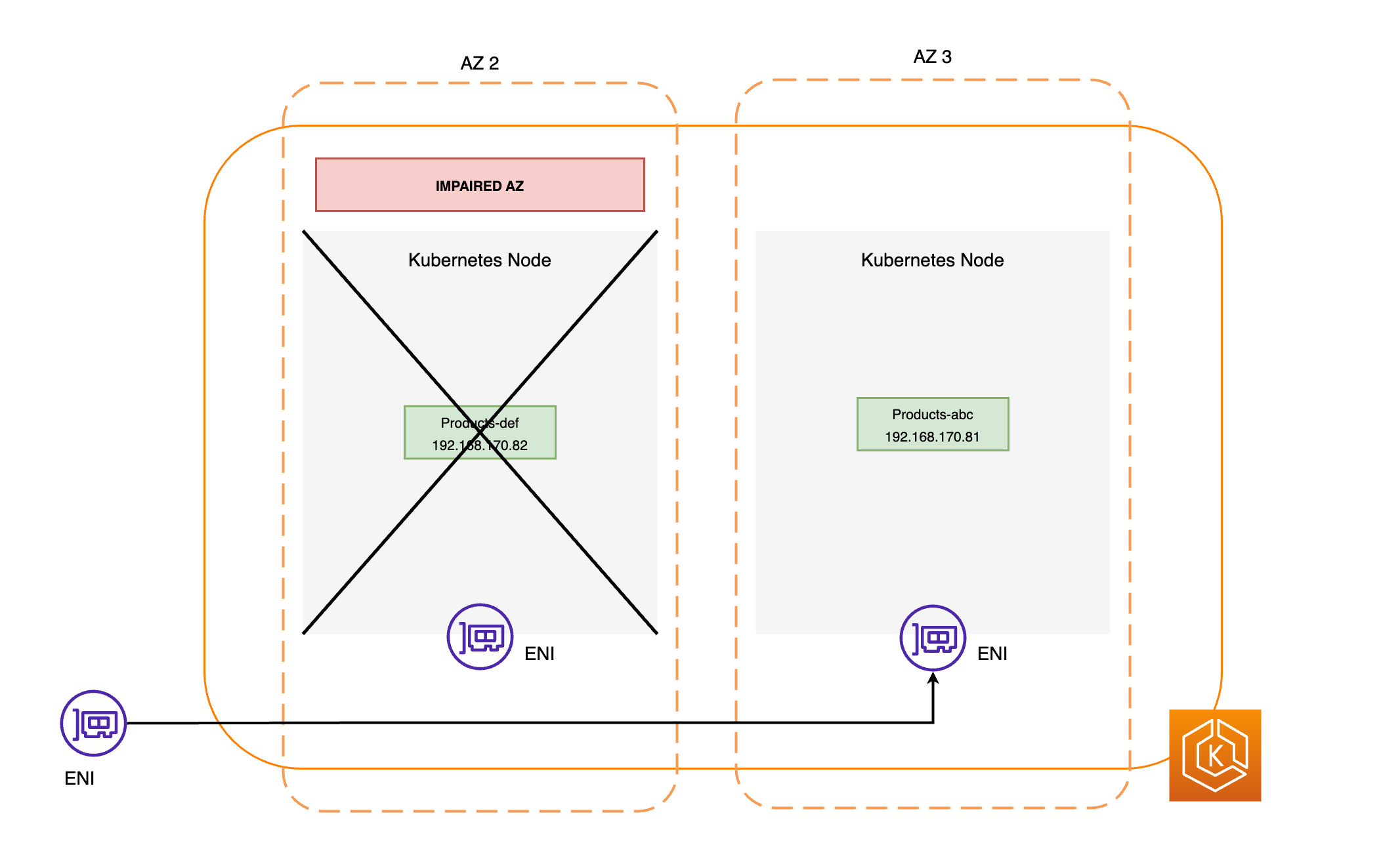
영향을 받는 가용 영역의 모든 노드가 폐쇄됩니다. 이렇게 하면 Kubernetes 스케줄러가 비정상 AZ의 노드에 새 포드를 예약하지 못합니다.
-
관리형 노드 그룹을 사용하는 경우 가용 영역 리밸런싱이 일시 중단되고 새 EKS 데이터 플레인 노드가 정상 AZ에서만 시작되도록 Auto Scaling 그룹이 업데이트됩니다.
-
비정상 AZ의 노드는 종료되지 않으며, 포드는 이러한 노드에서 제거되지 않습니다. 영역 전환이 만료되거나 취소될 때 전체 용량을 위해 트래픽이 AZ로 안전하게 돌아갈 수 있도록 하기 위해서입니다.
-
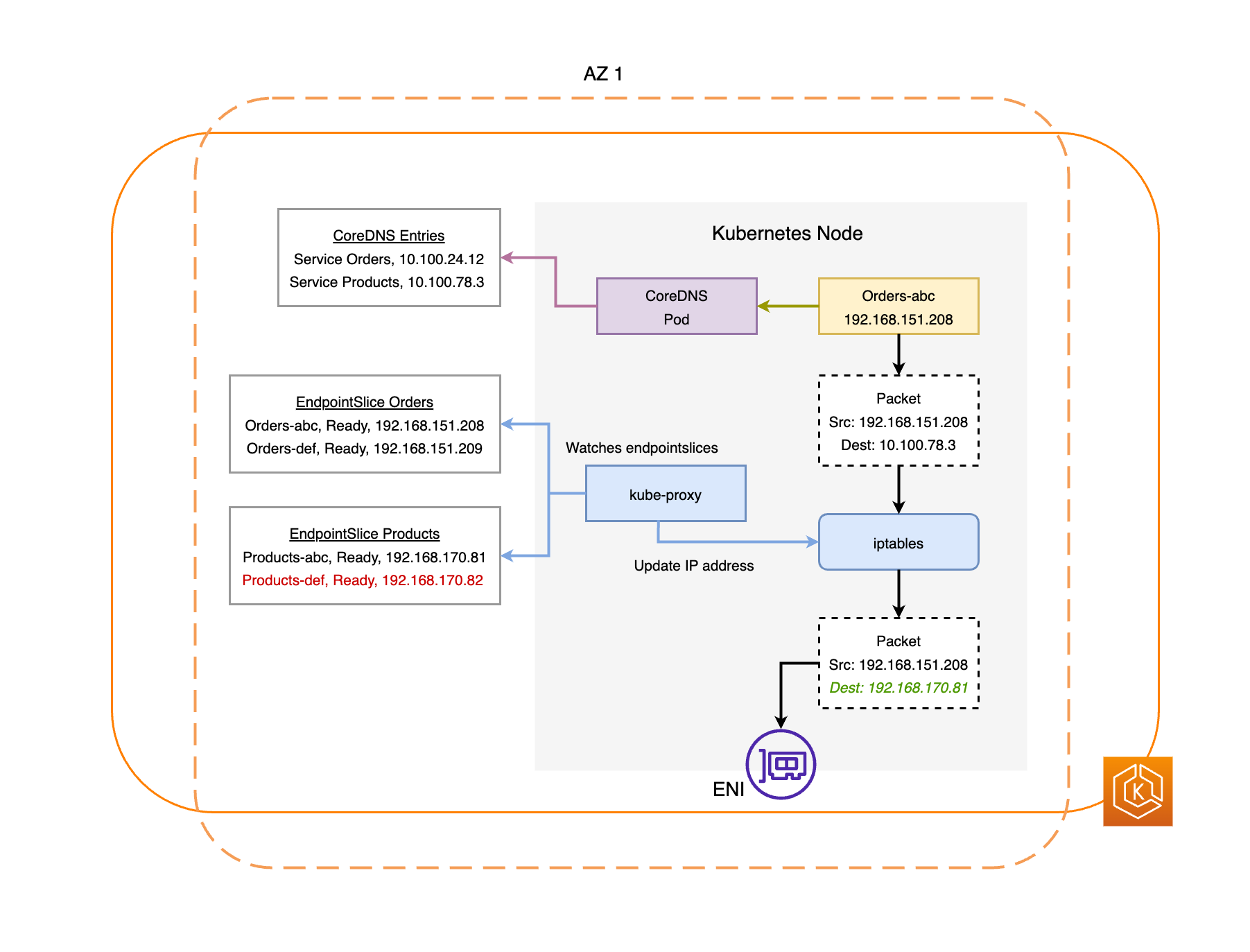
EndpointSlice 컨트롤러는 장애가 발생한 AZ에서 모든 포드 엔드포인트를 찾아 관련 EndpointSlices에서 제거합니다. 이렇게 하면 정상 가용 영역에 있는 포드 엔드포인트만 네트워크 트래픽을 수신하도록 타겟팅됩니다. 영역 전환이 취소되거나 만료되면, EndpointSlice 컨트롤러는 복원된 가용 영역에 엔드포인트를 포함하도록 EndpointSlices를 업데이트합니다.
아래 다이어그램에서는 EKS 영역 전환이 클러스터 환경에서 정상 상태의 포드 엔드포인트만 대상으로 지정하도록 하는 방법에 대한 대략적인 개요를 보여줍니다.
EKS 영역 전환 요구 사항
EKS에서 영역 전환이 성공적으로 작동하려면 AZ 장애에 탄력적으로 대응할 수 있도록 클러스터 환경을 미리 설정해야 합니다. 다음은 복원력을 보장하는 데 도움이 되는 구성 옵션 목록입니다.
-
여러 AZ에 걸쳐 클러스터의 워커 노드 프로비저닝하기
-
단일 AZ 제거 상황을 수용할 수 있도록 충분한 컴퓨팅 용량 프로비저닝
-
모든 AZ에서 포드(CoreDNS 포함) 사전 조정
-
모든 AZ에 걸쳐 여러 포드 복제본을 분산하여 단일 AZ에서 다른 위치로 전환해도 계속 충분한 용량을 확보할 수 있도록 하세요.
-
동일한 AZ에 상호 의존적이거나 관련된 포드의 콜로케이션
-
수동으로 AZ에서 다른 위치로 영역 전환을 시작하여 단일 AZ 손실 상황에서 클러스터 환경이 예상대로 작동하는지 테스트합니다. 또는 영역 자동 전환을 활성화하고 자동 전환 사례 실행에 의존할 수 있습니다. 영역 전환이 EKS에서 작동하려면 수동 또는 연습 영역 전환을 사용한 테스트가 필요하지 않아도 강력히 권장됩니다.
여러 AZ에 걸쳐 EKS 워커 노드 프로비저닝
AWS 리전에는 가용 영역(AZ)이라고 하는 물리적 데이터 센터가 있는 여러 개별 위치가 있습니다. AZ는 리전 전체에 영향을 미칠 수 있는 동시 영향을 피하기 위해 서로 물리적으로 격리되도록 설계되었습니다. EKS 클러스터를 프로비저닝할 때 리전 내 여러 AZ에서 워커 노드를 배포하는 것이 좋습니다. 그러면 클러스터 환경이 단일 AZ의 장애에 더 탄력적으로 대응하고 다른 AZ에서 실행 중인 애플리케이션의 고가용성(HA)을 유지할 수 있습니다. 영향을 받는 AZ로부터 영역 전환을 시작하면 정상 AZ만 사용하도록 EKS 환경의 클러스터 내 네트워크가 자동으로 업데이트되어 클러스터의 고가용성 유지에 도움이 됩니다.
EKS 환경에 대해 다중 AZ를 설정하면 시스템의 전반적인 신뢰성을 향상시킬 수 있습니다. 그러나 다중 AZ 환경은 애플리케이션 데이터가 전송 및 처리되는 방식에 중요한 영향을 주며, 결국 환경의 네트워크 요금에도 영향을 줄 수 있습니다. 특히 잦은 송신 교차 영역 트래픽(AZ 사이에서 분산되는 트래픽)은 네트워크 관련 비용에 큰 영향을 줄 수 있습니다. 다양한 전략을 적용하여 EKS 클러스터의 포드 간 영역 간 트래픽 양을 제어하고 관련 비용을 절감할 수 있습니다. 고가용성 EKS 환경을 실행할 때 네트워크 비용을 최적화하는 방법에 대한 자세한 내용은 이 모범 사례 가이드
다음 다이어그램에서는 3개의 정상 AZ가 있는 고가용성 EKS 환경을 보여줍니다.
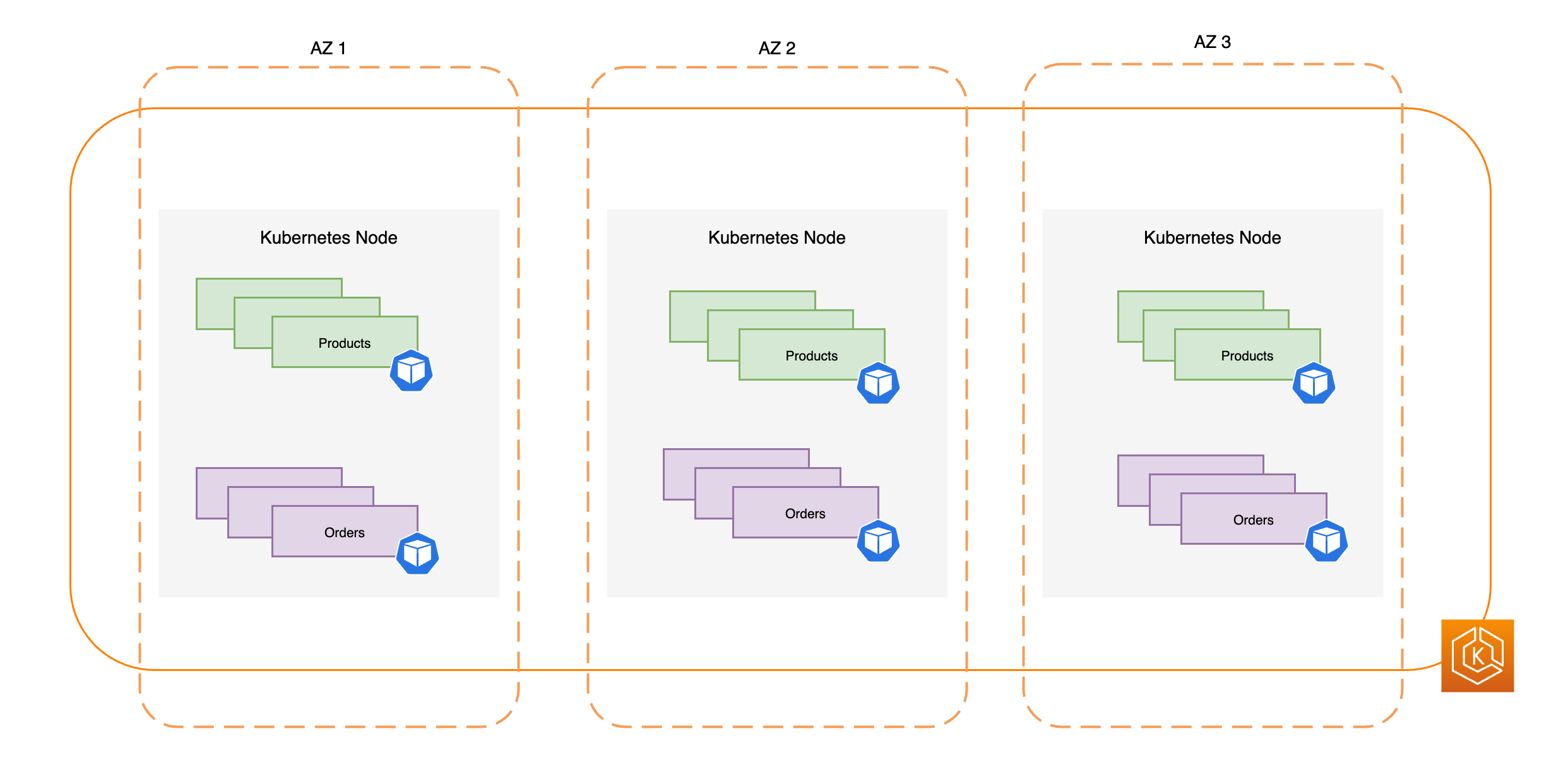
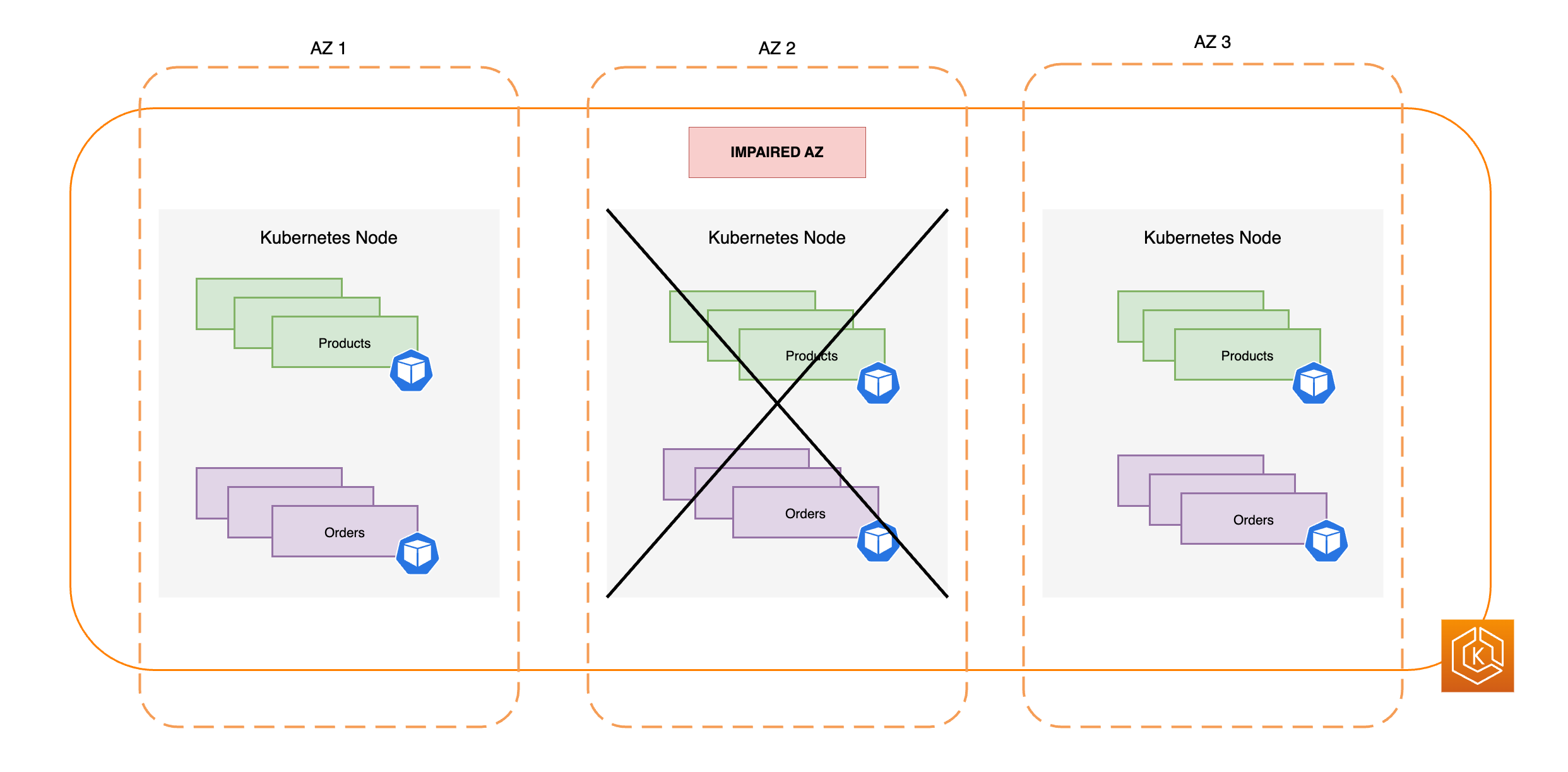
아래 다이어그램에서는 3개의 AZ가 있는 EKS 환경이 AZ 장애에 탄력적으로 대응하고 남아 있는 2개의 정상 AZ를 통해 높은 가용성을 유지하는 방법을 보여줍니다.
단일 AZ 제거 상황을 견딜 수 있도록 충분한 컴퓨팅 용량 프로비저닝
EKS 데이터 플레인에서 컴퓨팅 인프라의 리소스 사용률과 비용을 최적화하려면 워크로드 요구 사항에 따라 컴퓨팅 용량을 조정하는 것이 모범 사례입니다. 그러나 모든 워커 노드가 최대 용량에 도달하는 경우 새 포드를 예약하기 전에 새 워커 노드를 EKS 데이터 플레인에 추가하는 방식에 의존하고 있습니다. 중요한 워크로드를 실행할 때는 갑작스러운 로드 증가, 노드 상태 문제 등과 같은 시나리오에 대처하기 위해 온라인에서 여분의 용량을 확보하고 실행하는 것이 보통 바람직한 사례입니다. 영역 전환을 사용하려는 경우 장애가 발생하면 용량의 전체 AZ를 제거하려고 합니다. 즉, AZ 중 하나가 오프라인 상태인 경우에도 충분히 로드를 처리할 수 있도록 중복 컴퓨팅 용량을 조정해야 합니다.
컴퓨팅 리소스를 조정할 때 EKS 데이터 플레인에 새 노드를 추가하는 프로세스는 다소 시간이 걸립니다. 특히 영역 장애가 발생한 경우 애플리케이션의 실시간 성능과 가용성에 영향을 미칠 수 있습니다. 최종 사용자나 클라이언트의 경험에서 성능 저하를 방지하기 위해 EKS 환경은 하나의 AZ 손실로 인한 로드를 흡수할 수 있어야 합니다. 즉, 새 포드가 필요한 시점과 워커 노드에서 실제로 예약된 시점 사이의 지연을 최소화하거나 없애야 합니다.
또한 영역 장애가 발생하는 경우 컴퓨팅 용량 제약으로 인해 새로 필요한 노드를 정상 AZ의 EKS 데이터 플레인에 추가하지 못하게 되는 위험을 완화할 것을 목표로 해야 합니다.
이러한 잠재적인 부정적 영향의 위험을 줄이려면 각 AZ의 일부 워커 노드에서 컴퓨팅 용량을 과다 프로비저닝하는 것이 좋습니다. 그러면 Kubernetes 스케줄러는 새 포드 배치에 사용할 수 있는 기존 용량을 확보합니다. 이는 환경에서 AZ 중 하나를 손실할 때 특히 중요합니다.
여러 가용 영역에서 Pod 복제본 실행 및 분산
Kubernetes를 사용하면 단일 애플리케이션의 여러 인스턴스(포드 복제본)를 실행하여 워크로드를 사전 확장할 수 있습니다. 애플리케이션에 대해 여러 포드 복제본을 실행하면 단일 장애 지점을 없애고 단일 복제본의 리소스 부담을 줄임으로써 전반적인 성능을 높일 수 있습니다. 그러나 애플리케이션의 고가용성과 내결함성을 모두 지원하려면 애플리케이션의 여러 복제본을 실행하고 여러 장애 도메인(이 경우 토폴로지 도메인이라고도 함)에 분산시켜야 합니다. 이 시나리오에서 장애 도메인은 가용 영역입니다. 토폴로지 분산 제약 조건
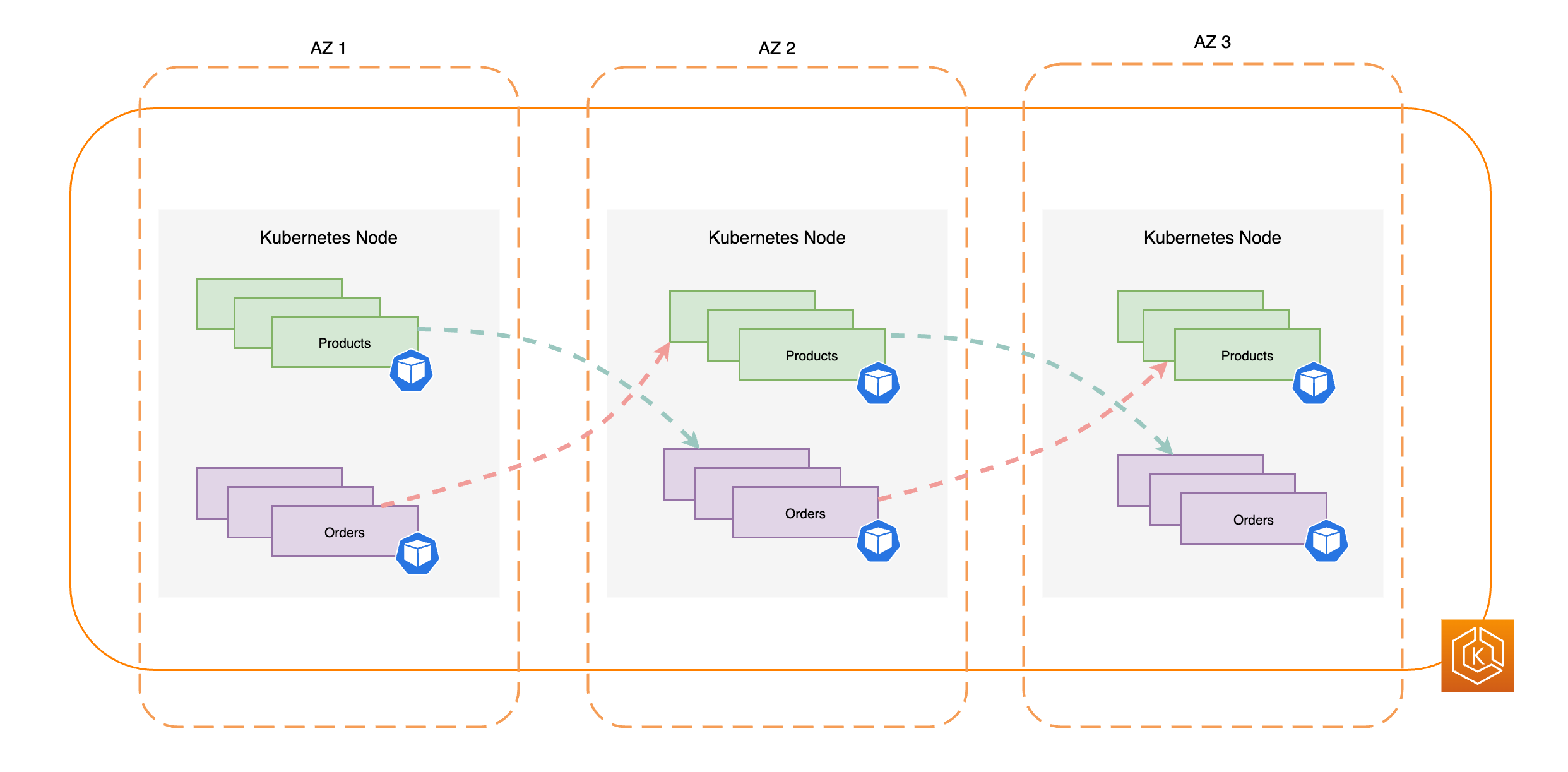
아래 다이어그램에서는 모든 AZ가 정상일 때 동서 방향 트래픽 흐름이 있는 EKS 환경을 보여줍니다.
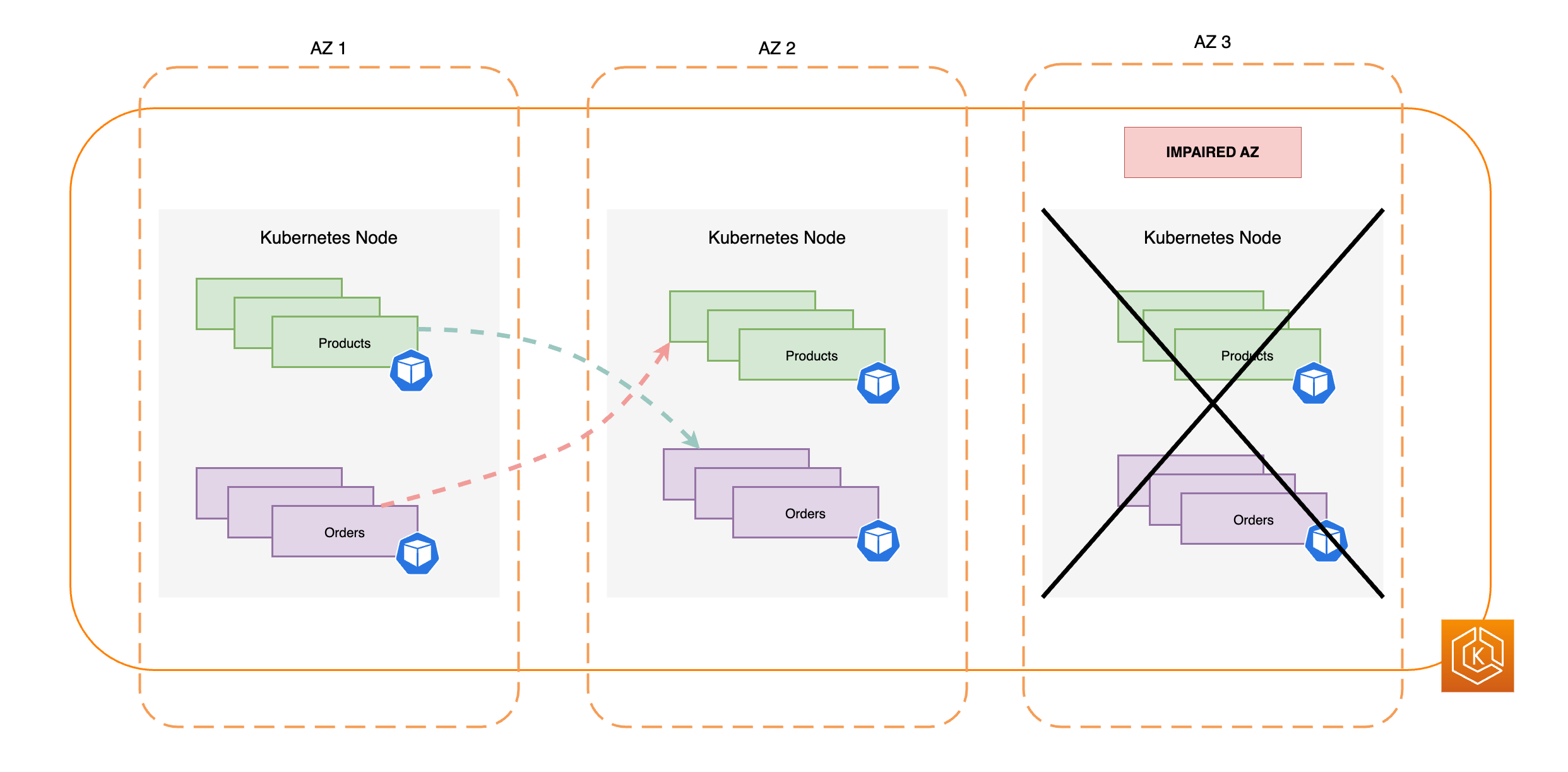
다음 다이어그램에서는 단일 AZ에서 장애가 발생하고 영역 전환을 시작한, 동서 트래픽 흐름이 있는 EKS 환경을 보여줍니다.
다음 코드 조각은 Kubernetes에서 여러 복제본을 사용하여 워크로드를 설정하는 방법에 대한 예입니다.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
가장 중요한 점은 DNS 서버 소프트웨어(CoreDNS/kube-dns)의 여러 복제본을 실행하고, 기본적으로 구성되지 않은 경우 유사한 토폴로지 분산 제약 조건을 적용해야 한다는 것입니다. 그러면 단일 AZ 장애가 발생하는 경우 클러스터에서 통신하는 다른 포드에 대한 서비스 검색 요청을 계속 처리할 수 있도록 정상 AZ에 충분한 DNS 포드를 확보할 수 있습니다. CoreDNS EKS 추가 기능에는 AZ에 사용 가능한 노드가 여러 개 있는 경우 클러스터의 가용 영역에 분산되도록 보장하는 CoreDNS 포드의 기본 설정이 있습니다. 원하면 이러한 기본 설정을 사용자 지정 구성으로 바꿀 수 있습니다.
헬름을 통해 CoreDNSreplicaCount를 업데이트하여 각 AZ에 충분한 수의 복제본이 있는지 확인할 수 있습니다. 또한 이러한 복제본이 클러스터 환경의 여러 AZ에 분산되도록 하려면 동일한 values.yaml 파일에서 topologySpreadConstraints 속성을 업데이트해야 합니다. 다음 코드 조각에서는 이 작업을 수행하도록 CoreDNS를 구성하는 방법을 보여줍니다.
CoreDNS Helm values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
AZ 장애가 발생하는 경우 CoreDNS에 대한 오토 스케일링 시스템을 사용하여 CoreDNS 포드에서 늘어난 로드를 흡수할 수 있습니다. 필요한 DNS 인스턴스 수는 클러스터에서 실행 중인 워크로드 수에 따라 달라집니다. CoreDNS는 Horizontal Pod Autoscaler(HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
또는 EKS는 CoreDNS의 EKS 추가 기능 버전에서 CoreDNS 배포의 오토 스케일링을 관리할 수 있습니다. 이 CoreDNS 오토스케일러는 노드 수와 CPU 코어 수를 포함하여 클러스터 상태를 지속적으로 모니터링합니다. 해당 정보를 기반으로 컨트롤러는 EKS 클러스터에서 CoreDNS 배포의 복제본 수를 동적으로 조정합니다.
CoreDNS EKS 추가 기능에서 오토 스케일링 구성을 활성화하려면 다음과 같은 구성 설정을 사용합니다.
{ "autoScaling": { "enabled": true } }
NodeLocal DNS
동일한 가용 영역에 상호 의존적인 포드의 콜로케이션
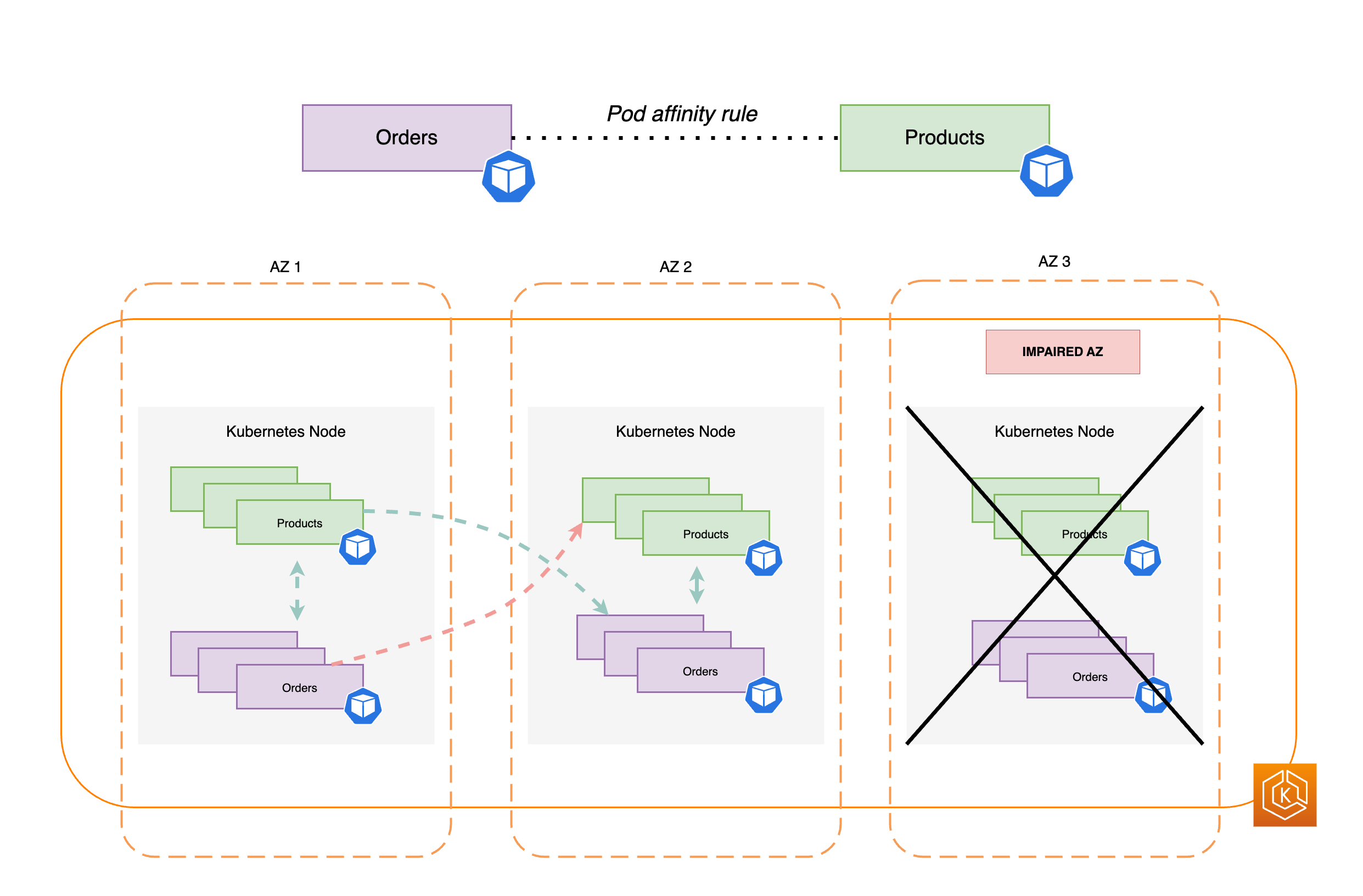
일반적으로 애플리케이션에는 포괄적인 프로세스를 성공적으로 완료하기 위해 서로 통신해야 하는 개별 워크로드가 있습니다. 이러한 개별 애플리케이션이 서로 다른 AZ에 분산되어 있고 동일한 AZ에 콜로케이션되지 않은 경우 단일 AZ 장애가 포괄적인 프로세스에 영향을 미칠 수 있습니다. 예를 들어 애플리케이션 A에는 AZ 1과 AZ 2에 복제본이 여러 개 있지만 애플리케이션 B에는 AZ 3에 모든 복제본이 있는 경우 AZ 3 손실이 발생하면 애플리케이션 A와 애플리케이션 B라는 두 워크로드 사이의 포괄적인 프로세스에 영향을 미칩니다. 토폴로지 분산 제약 조건을 포드 선호도와 결합하면 모든 AZ에 포드를 분산하여 애플리케이션의 복원력을 개선할 수 있습니다. 또한 포드가 콜로케이션되도록 특정 포드 간 관계를 구성합니다.
포드 선호도 규칙
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
다음 다이어그램에서는 포드 선호도 규칙을 사용하여 동일한 노드에 콜로케이션된 여러 포드를 보여줍니다.
클러스터 환경이 AZ 손실을 처리할 수 있는지 테스트
이전 섹션에서 설명된 요구 사항을 완료한 후 다음 단계는 AZ 손실을 처리하기 위해 충분한 컴퓨팅 및 워크로드 용량을 보유하고 있는지 테스트하는 것입니다. EKS에서 영역 전환을 수동으로 시작하여 이를 수행할 수 있습니다. 또는 영역 자동 전환을 활성화하고 연습 실행을 구성할 수 있습니다. 이를 통해 클러스터 환경에서 AZ가 하나 손실된 상태에서 애플리케이션이 예상대로 작동하는지도 테스트할 수 있습니다.
자주 묻는 질문(FAQ)
왜 이 기능을 사용해야 하나요?
EKS 클러스터에서 ARC 구역 이동 또는 구역 자동 이동을 사용하면 클러스터 내 네트워크 트래픽을 손상된 AZ에서 멀리 이동시키는 빠른 복구 프로세스를 자동화하여 Kubernetes 애플리케이션 가용성을 더 잘 유지할 수 있습니다. ARC를 사용하면 AZ에서 장애 이벤트가 발생한 동안 복구 기간이 늘어날 수 있는 길고 복잡한 단계를 피할 수 있습니다.
이 기능은 다른 AWS 서비스에서 어떻게 작동하나요?
EKS는 ARC와 통합됩니다. ARC는 AWS에서 복구 작업을 수행할 수 있는 기본 인터페이스를 제공합니다. 클러스터 내 트래픽이 장애가 발생한 AZ에서 다른 위치로 적절히 라우팅되도록 하기 위해 EKS는 Kubernetes 데이터 플레인에서 실행되는 포드의 네트워크 엔드포인트 목록을 수정합니다. 외부 트래픽을 클러스터로 라우팅하기 위해 탄력적 로드 밸런싱을 사용하는 경우 로드 밸런서를 ARC에 등록하고 여기에서 영역 전환을 시작하여 성능이 저하된 AZ로 트래픽이 유입되지 않도록 할 수 있습니다. 영역 전환은 EKS 관리형 노드 그룹에 의해 생성된 Amazon EC2 Auto Scaling 그룹에서도 작동합니다. 장애가 발생한 AZ가 새로운 Kubernetes 포드 또는 노드 실행에 사용되지 않도록 하기 위해 EKS는 장애가 발생한 AZ를 Auto Scaling 그룹에서 제거합니다.
이 기능은 기본 Kubernetes 보호와 어떻게 다른가요?
이 기능은 고객 애플리케이션의 복원력에 도움이 되는 여러 Kubernetes 기본 제공 보호 기능과 함께 작동합니다. 포드가 트래픽을 수신해야 하는 시기를 결정하는 포드 준비 상태 및 활성 프로브를 구성할 수 있습니다. 이러한 프로브에 실패하면 Kubernetes는 이러한 포드를 서비스의 대상으로 제거하고 트래픽은 더 이상 포드로 전송되지 않습니다. 이 기능은 유용하지만, AZ 성능이 저하될 때 실패하도록 고객이 이러한 상태 확인을 구성하는 것은 간단하지 않습니다. ARC 영역 전환 기능은 Kubernetes의 기본 보호 기능으로 충분하지 않은 경우 성능 저하된 AZ를 완전히 격리하는 데 도움이 되는 추가적인 안전망을 제공합니다. 또한 영역 전환은 아키텍처의 운영 준비 상태와 복원력을 쉽게 테스트할 수 있는 방법을 제공하기도 합니다.
AWS가 사용자 대신 영역 전환을 트리거할 수 있나요?
예, ARC 구역 전환를 완전히 자동화된 방식으로 사용하려면 ARC 구역 자동 전환를 사용하도록 설정할 수 있습니다. 영역 자동 전환을 사용하면 AWS를 통해 EKS 클러스터의 AZ 상태를 모니터링하고 AZ 장애가 감지될 때 자동으로 영역 전환을 트리거할 수 있습니다.
이 기능을 사용하는데 워커 노드와 워크로드가 사전 확장되지 않은 경우 어떻게 되나요?
사전에 조정하지 않고 영역 전환 중에 추가 노드 또는 포드 프로비저닝에 의존하는 경우 복구가 지연될 위험이 있습니다. Kubernetes 데이터 플레인에 새 노드를 추가하는 프로세스는 시간이 다소 걸리며, 이는 특히 영역 장애가 발생하는 경우 애플리케이션의 실시간 성능과 가용성에 영향을 미칠 수 있습니다. 또한 영역 장애가 발생하면 잠재적인 컴퓨팅 용량 제약이 발생하여 새로 필요한 노드를 정상 AZ에 추가하지 못할 수도 있습니다.
워크로드가 사전 조정되지 않고 클러스터의 모든 AZ에 분산되어 있는 경우, 영역 장애는 영향을 받는 AZ의 워커 노드에서만 실행되는 애플리케이션의 가용성에 영향을 미칠 수 있습니다. 애플리케이션의 완전한 가용성 중단 위험을 완화하기 위해 EKS는 워크로드의 모든 엔드포인트가 비정상적인 AZ에 있는 경우 트래픽이 손상된 영역의 포드 엔드포인트로 전송되지 않도록 하는 장애 세이프 기능을 제공합니다. 그러나 영역에서 문제 발생 시 가용성을 유지하기 위해 애플리케이션을 사전 조정하고 모든 AZ에 분산하는 것이 좋습니다.
상태 저장 애플리케이션을 실행하는 경우 어떻게 작동하나요?
상태 저장 애플리케이션을 실행하는 경우 사용 사례와 아키텍처에 따라 내결함성을 평가해야 합니다. 액티브/대기 아키텍처 또는 패턴이 있는 경우 액티브가 손상된 AZ에 있을 수 있습니다. 애플리케이션 수준에서 대기 모드가 활성화되어 있지 않으면 애플리케이션에 문제가 발생할 수 있습니다. 정상 AZ에서 새 Kubernetes 포드가 시작되면 장애가 발생한 AZ에 바인드된 영구 볼륨에 연결할 수 없으므로 문제가 발생할 수도 있습니다.
이 기능은 Karpenter와 함께 작동하나요?
Karpenter 지원은 Karpenter 버전 1.12 이상
이 기능은 EKS Fargate에서 작동하나요?
이 기능은 EKS Fargate에서 작동하지 않습니다. 기본적으로 EKS Fargate가 영역 상태 이벤트를 인식하면 포드는 다른 AZ에서 실행되는 것을 선호합니다.
EKS 관리형 Kubernetes 컨트롤 플레인이 영향을 받나요?
아니요, 기본적으로 Amazon EKS는 고가용성을 보장하기 위해 여러 AZ에서 Kubernetes 컨트롤 플레인을 실행하고 확장합니다. ARC 영역 전환 및 영역 자동 전환은 Kubernetes 데이터 플레인에서만 작동합니다.
이 새로운 기능과 관련된 비용이 있습니까?
EKS 클러스터에서 추가 비용 없이 ARC 구역 교대근무 및 구역 자동 교대근무를 사용할 수 있습니다. 그러나 프로비저닝된 인스턴스에 대한 비용은 계속 지불해야 하며, 이 기능을 사용하기 전에 Kubernetes 데이터 플레인을 사전 조정하는 것이 좋습니다. 비용과 애플리케이션 가용성 사이에서 균형을 고려해야 합니다.
추가 리소스
