이 페이지 개선에 도움 주기
이 사용자 가이드에 기여하려면 모든 페이지의 오른쪽 창에 있는 GitHub에서 이 페이지 편집 링크를 선택합니다.
빠른 시작: Amazon EKS에서 vLLM을 사용하는 높은 처리량의 LLM 추론
소개
이 빠른 시작 가이드에서는 텍스트 기반 실시간 추론 애플리케이션에 대해 LLM 및 GPU를 사용하여 Amazon EKS에 대규모 언어 모델(LLM)을 배포하는 과정을 안내합니다.
이 솔루션은 컨테이너 오케스트레이션을 위해 Amazon EKS를 활용하고 효율적인 모델 제공을 위해 vLLM을 활용하므로 GPU 가속화 및 높은 처리량의 추론 제공을 통해 확장 가능한 AI 애플리케이션을 빌드할 수 있습니다. Llama 3.1 8B Instruct 모델은 데모용으로 사용되지만 vLLM에서 지원하는 다른 LLM을 배포할 수 있습니다(지원되는 모델 목록은 vLLM 설명서
EKS의 vLLM 아키텍처

이 절차를 완료하면 처리량과 짧은 지연 시간에 최적화된 vLLM 추론 엔드포인트를 보유하고, 채팅 프론트엔드 애플리케이션을 통해 Llama 모델과 상호 작용하여 챗봇 어시스턴트 및 기타 LLM 기반 애플리케이션의 일반적인 사용 사례를 보여줄 수 있습니다.
추가 지침 및 고급 배포 리소스는 AI/ML 워크로드에 대한 EKS 추론 모범 사례 가이드 및 프로덕션에 적합한 AI on EKS inference charts
시작하기 전 준비 사항
시작하기 전에 다음이 있어야 합니다.
-
다음과 같은 주요 구성 요소가 있는 Amazon EKS 클러스터: G5 또는 G6 EC2 인스턴스 패밀리가 있는 Karpenter 노드 풀, GPU 지원 워커 노드에 설치된 NVIDIA 디바이스 플러그인, 설치된 S3 Mountpoint CSI 드라이버. 이 기준 설정을 생성하려면 Amazon EKS에서의 실시간 추론 모범 사례 클러스터 설정 가이드의 단계를 따라 4단계까지 완료합니다.
-
Hugging Face 계정. 가입하려면 https://huggingface.co/login을 참조하세요.
Amazon S3를 사용하여 모델 스토리지 설정
대용량 LLM 파일을 Amazon S3에 효율적으로 저장하여 컴퓨팅 리소스와 스토리지를 분리합니다. 이 접근 방식은 모델 업데이트를 간소화하고 비용을 절감하며 프로덕션 설정의 관리를 단순화합니다. S3는 대량 파일을 안정적으로 처리하지만면, Mountpoint CSI 드라이버를 통해 Kubernetes와 통합하면 시작 중에 시간이 오래 걸리는 다운로드를 수행하지 않고도 포드에서 로컬 스토리지와 같은 모델에 액세스할 수 있습니다. 다음 단계에 따라 S3 버킷을 생성하고 LLM을 업로드하며 추론 제공 컨테이너에 볼륨으로 탑재합니다.
EFS 및 FSx for Lustre와 같은 다른 스토리지 솔루션은 모델 캐싱을 위해 EKS에서도 사용할 수 있습니다. 자세한 내용은 EKS 모범 사례를 참조하세요.
환경 변수 설정
이 가이드의 뒷부분에서 생성할 새 Amazon S3 버킷의 고유한 이름을 생성합니다. 생성되면 모든 단계에서 동일한 이 버킷 이름을 사용합니다. 예제:
MY_BUCKET_NAME=model-store-$(date +%s)
환경 변수를 정의하고 파일에 저장합니다.
cat << EOF > .env-quickstart-vllm export BUCKET_NAME=${MY_BUCKET_NAME} export AWS_REGION=us-east-1 export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) EOF
쉘 환경에서 환경 변수를 로드합니다. 현재 쉘 환경을 닫고 새 환경을 여는 경우 동일한 명령을 사용하여 환경 변수를 다시 소싱해야 합니다.
source .env-quickstart-vllm
모델 파일을 저장할 S3 버킷 생성
모델 파일을 저장할 S3 버킷을 생성합니다.
aws s3 mb s3://${BUCKET_NAME} --region ${AWS_REGION}
Hugging Face에서 모델 다운로드
Hugging Face는 LLM 모델에 액세스하기 위한 기본 모델 허브 중 하나입니다. Llama 모델을 다운로드하려면 모델 라이선스를 수락하고 토큰 인증을 설정해야 합니다.
-
https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct에서 Llama 3.1 8B Instruct 모델 라이선스를 수락합니다.
-
액세스 토큰을 생성합니다(프로파일 > 설정 > 액세스 토큰으로 이동한 다음 읽기 토큰 유형을 사용하여 새 토큰을 생성함).
Hugging Face 토큰을 사용하여 환경 변수를 설정합니다.
export HF_TOKEN=your_token_here
환경에 pip3 패키지가 아직 설치되지 않은 경우 이를 설치합니다. Amazon Linux 2023의 명령 예제:
sudo dnf install -y python3-pip
Hugging Face CLI
pip install huggingface-hub
--exclude 플래그를 사용하여 Hugging Face(~15GB)에서 Llama-3.1-8B-Instruct 모델을 다운로드하여 레거시 PyTorch 형식을 건너뛰고 최적화된 Safetensors 형식 파일만 다운로드합니다. 그러면 많이 사용되는 추론 엔진과의 완전한 호환성을 유지하면서 다운로드 크기를 줄일 수 있습니다.
huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct \ --exclude "original/*" \ --local-dir ./llama-3.1-8b-instruct \ --token $HF_TOKEN
다운로드한 파일을 확인합니다.
$ ls llama-3.1-8b-instruct
예상되는 출력은 다음과 같아야 합니다.
LICENSE config.json model-00002-of-00004.safetensors model.safetensors.index.json tokenizer_config.json README.md generation_config.json model-00003-of-00004.safetensors special_tokens_map.json USE_POLICY.md model-00001-of-00004.safetensors model-00004-of-00004.safetensors tokenizer.json
모델 파일 업로드
S3 전송 성능을 개선하기 위해 AWS 공통 런타임(CRT)을 활성화합니다. CRT 기반 전송 클라이언트는 대규모 파일 작업에 맞는 향상된 처리량과 신뢰성을 제공합니다.
aws configure set s3.preferred_transfer_client crt
모델을 업로드합니다.
aws s3 cp ./llama-3.1-8b-instruct s3://$BUCKET_NAME/llama-3.1-8b-instruct \ --recursive
예상되는 출력은 다음과 같아야 합니다.
... upload: llama-3.1-8b-instruct/tokenizer.json to s3://model-store-1753EXAMPLE/llama-3.1-8b-instruct/tokenizer.json upload: llama-3.1-8b-instruct/model-00004-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00004-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00002-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00002-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00003-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00003-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00001-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00001-of-00004.safetensors
S3 Mountpoint CSI 권한 설정
S3 Mountpoint CSI 드라이버를 사용하면 Kubernetes 및 S3 간 네이티브 통합이 가능하므로 포드가 로컬 스토리지인 것처럼 모델 파일에 직접 액세스할 수 있어 컨테이너 시작 중에 로컬 복사본이 필요하지 않습니다.
S3 탑재 지점을 S3 버킷에서 읽을 수 있도록 IAM 정책을 생성합니다.
aws iam create-policy \ --policy-name S3BucketAccess-${BUCKET_NAME} \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:GetObjectVersion\", \"s3:ListBucket\", \"s3:GetBucketLocation\"], \"Resource\": [\"arn:aws:s3:::${BUCKET_NAME}\", \"arn:aws:s3:::${BUCKET_NAME}/*\"]}]}"
S3 CSI 드라이버 서비스 계정 주석을 확인하여 S3 Mountpoint CSI 드라이버에서 사용하는 IAM 역할 이름을 찾습니다.
ROLE_NAME=$(kubectl get serviceaccount s3-csi-driver-sa -n kube-system -o jsonpath='{.metadata.annotations.eks\.amazonaws\.com/role-arn}' | cut -d'/' -f2)
IAM 정책을 S3 Mountpoint CSI 역할에 연결합니다.
aws iam attach-role-policy \ --role-name ${ROLE_NAME} \ --policy-arn arn:aws:iam::${AWS_ACCOUNT_ID}:policy/S3BucketAccess-${BUCKET_NAME}
클러스터에 S3 Mountpoint CSI가 설치되지 않은 경우 Amazon EKS에서의 실시간 추론 모범 사례 클러스터 설정 가이드의 배포 단계를 따릅니다.
S3 버킷을 Kubernetes 볼륨으로 탑재
영구 볼륨(PV) 및 영구 볼륨 클레임(PVC)을 생성하여 여러 추론 포드에서 S3 버킷에 대한 읽기 전용 액세스를 제공합니다. ReadOnlyMany 액세스 모드에서는 모델 파일에 대한 동시 액세스를 보장하는 반면, CSI 드라이버는 S3 버킷 탑재를 처리합니다.
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: model-store spec: storageClassName: "" capacity: storage: 100Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain mountOptions: - region ${AWS_REGION} csi: driver: s3.csi.aws.com volumeHandle: model-store volumeAttributes: bucketName: ${BUCKET_NAME} --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-store spec: storageClassName: "" volumeName: model-store accessModes: - ReadOnlyMany resources: requests: storage: 100Gi EOF
GPU 인프라 설정
클러스터 노드
Amazon EKS에서의 실시간 추론 모범 사례 클러스터 설정 가이드에서 생성된 EKS 클러스터를 사용하고 있습니다. 이 클러스터에는 vLLM 컨테이너 이미지를 다운로드하기에 충분한 노드 스토리지를 포함하는 GPU 지원 노드를 프로비저닝할 수 있는 Karpenter 노드 풀이 포함되어 있습니다. 사용자 지정 EKS 클러스터를 사용하는 경우 GPU 지원 노드를 시작할 수 있는지 확인합니다.
인스턴스 선택
LLM 추론에 대해 적절한 인스턴스를 선택하려면 사용 가능한 GPU 메모리가 모델 가중치를 로드하기에 충분한지 확인해야 합니다. Llama 3.1 8B Instruct의 모델 가중치는 약 16GB(모델 파일 .safetensor의 크기)이므로 모델을 로드하려면 vllm 프로세스에 이 크기 이상의 메모리를 제공해야 합니다.
A10G GPU가 있는 Amazon G5 EC2 인스턴스
NVIDIA 디바이스 드라이버
NVIDIA 드라이버는 컨테이너가 GPU 리소스에 효율적으로 액세스하는 데 필요한 런타임 환경을 제공합니다. 이를 통해 Kubernetes 내에서 GPU 리소스 할당 및 관리를 활성화하여 GPU를 예약 가능한 리소스로 사용할 수 있습니다.
클러스터는 모든 GPU 지원 노드에서 필요한 모든 NVIDIA 디바이스 드라이버와 플러그인이 포함된 EKS Bottlerocket AMI를 사용하므로 추가 설정 없이도 컨테이너화된 워크로드에 대한 즉각적인 GPU 액세스를 보장합니다. 다른 유형의 EKS 노드를 사용하는 경우 필요한 모든 드라이버와 플러그인이 설치되어 있는지 확인해야 합니다.
GPU 인프라 테스트
포드가 NVIDIA GPU 리소스에 액세스하고 GPU 지원 노드에서 올바르게 예약할 수 있도록 아래 단계를 실행하여 클러스터의 GPU 기능을 테스트합니다.
Nvidia SMI 테스트 포드를 배포합니다.
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: gpu-nvidia-smi-test spec: restartPolicy: OnFailure tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker # Matches GPU NodePool's label containers: - name: cuda-container image: nvidia/cuda:12.9.1-base-ubuntu20.04 command: ["nvidia-smi"] resources: requests: memory: "24Gi" limits: nvidia.com/gpu: 1 EOF
포드 로그를 검토하여 아래 출력과 유사한 GPU 세부 정보가 나열되어 있는지 확인합니다(동일한 GPU 모델일 필요는 없음).
$ kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/gpu-nvidia-smi-test $ kubectl logs gpu-nvidia-smi-test
Wed Jul 30 15:39:58 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 | | 0% 30C P8 9W / 300W | 0MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
이 출력에서는 포드가 GPU 리소스에 성공적으로 액세스할 수 있음을 보여줍니다.
중요: 이 포드는 Amazon EKS에서의 실시간 추론 모범 사례 클러스터 설정 가이드의 Karpenter 노드 풀과 일치하는 nodeSelector 구성을 사용합니다. 다른 노드 풀을 사용하는 경우 포드가 적절히 nodeSelector 및 Tolerations와 일치하는지 확인합니다.
추론 컨테이너 배포
서비스 스택은 추론 인프라의 성능과 확장성 기능을 모두 결정합니다. vLLM은 프로덕션 배포의 선도적인 솔루션으로 부상했습니다. vLLM의 아키텍처에서는 동적 요청 처리를 위한 지속적인 배치 처리, 더 빠른 추론을 위한 커널 최적화, PagedAttention을 통한 효율적인 GPU 메모리 관리를 제공합니다. 이러한 기능은 프로덕션 지원 REST API 및 널리 사용되는 모델 형식에 대한 지원과 결합되어 고성능 추론 배포에 적합합니다.
AWS 딥 러닝 컨테이너 이미지 선택
AWS 딥 러닝 컨테이너
이 배포에서는 vLLM 0.9용 AWS DLC를 사용합니다. 여기에는 Nvidia 라이브러리 및 AWS GPU 인스턴스에서 트랜스포머 모델 추론을 위해 특별히 조정된 최적화된 GPU 성능 구성이 포함됩니다.
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2
vLLM Kubernetes 매니페스트 적용
EKS에 vLLM을 배포하는 여러 방법이 있습니다. 이 가이드에서는 Kubernetes 배포를 사용하는 vLLM 배포를 보여줍니다. 이 배포는 Kubernetes 네이티브 방식이며 쉽게 시작할 수 있습니다. 고급 배포 옵션은 vLLM 문서
Kubernetes 매니페스트를 통해 배포 파라미터를 정의하여 리소스 할당, 노드 배치, 상태 프로브, 서비스 공개 등을 제어합니다. vLLM에 대한 AWS 딥 러닝 컨테이너 이미지를 사용하여 GPU 지원 포드를 실행하도록 배포를 구성합니다. LLM 추론에 최적화된 파라미터를 설정하고 AWS 로드 밸런서 서비스를 통해 vLLM OpenAPI 호환 엔드포인트를 공개합니다.
cat <<EOF | envsubst | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker containers: - name: vllm-inference image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2 ports: - containerPort: 8000 env: - name: MODEL_PATH value: "/mnt/models/llama-3.1-8b-instruct" args: - "--model=/mnt/models/llama-3.1-8b-instruct" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" readinessProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 resources: limits: nvidia.com/gpu: 1 requests: memory: "24Gi" cpu: "4" ephemeral-storage: "25Gi" # Ensure enough node storage for vLLM container image volumeMounts: - name: models mountPath: /mnt/models readOnly: true volumes: - name: models persistentVolumeClaim: claimName: model-store --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: type: LoadBalancer ports: - port: 80 targetPort: 8000 protocol: TCP selector: app: vllm-inference-app EOF
vLLM 포드가 Ready 1/1 상태인지 확인합니다.
kubectl get pod -l app=vllm-inference-app -w
예상 결과:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
컨테이너 이미지를 가져오고 vLLM이 모델 파일을 GPU 메모리에 로드하는 데 몇 분 정도 걸릴 수 있습니다. 포드가 준비 및 사용 가능 상태인 경우에만 진행합니다.
서비스 공개
로컬 개발 및 테스트를 위해 Kubernetes 포트 전달을 사용하여 로컬에서 추론 엔드포인트를 공개합니다. 이 명령은 별도의 터미널 창에서 실행되는 상태로 둡니다.
export POD_NAME=$(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') kubectl port-forward pod/$POD_NAME 8000:8000
AWS 로드 밸런서 컨트롤러는 vLLM 서비스 엔드포인트를 외부에 노출하는 Network Load Balancer를 자동으로 생성합니다. 다음을 실행하여 NLB 엔드포인트를 가져옵니다.
NLB=$(kubectl get service vllm-inference-svc -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
AWS 로드 밸런서 컨트롤러를 설치해야 하나요? AWS 로드 밸런서 컨트롤러를 통해 인터넷 트래픽 라우팅의 배포 단계를 따릅니다.
추론 실행
추론 포드 검증
전달된 포트를 통해 로컬에서 추론 컨테이너 기능을 검증합니다. 연결 요청을 전송하고 응답에 HTTP 코드 200이 포함되어 있는지 확인합니다.
$ curl -IX GET "http://localhost:8000/v1/models"
HTTP/1.1 200 OK date: Mon, 13 Oct 2025 23:24:57 GMT server: uvicorn content-length: 516 content-type: application/json
NLB 엔드포인트를 통해 LLM에 완료 요청을 전송하여 추론 기능을 테스트하고 외부 연결을 검증합니다.
curl -X POST "http://$NLB:80/v1/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/models/llama-3.1-8b-instruct", "prompt": "Explain artificial intelligence:", "max_tokens": 512, "temperature": 0.7 }'
이 엔드포인트는 OpenAI API 형식을 따르므로 기존 애플리케이션과 호환되는 동시에 출력 다양성을 제어하고자 응답 길이 및 온도와 같은 구성 가능한 생성 파라미터를 제공합니다.
챗봇 앱 실행
데모를 위해 이 가이드에서는 프로젝트 nextjs-vllm-ui
포트 3000을 localhost에 매핑하고 vLLM NLB 엔드포인트에 연결하는 Docker 컨테이너로 챗봇 UI를 실행합니다.
docker run --rm \ -p 3000:3000 \ -e VLLM_URL="http://${NLB}:80" \ --name nextjs-vllm-ui-demo \ ghcr.io/yoziru/nextjs-vllm-ui:latest
브라우저를 열고 https://localhost:3000으로 이동합니다.
Llama 모델과 상호 작용할 수 있는 채팅 인터페이스가 표시됩니다.
채팅 UI 인터페이스

추론 성능 최적화
vLLM과 같은 특수 추론 엔진은 지속적인 배치 처리, 효율적인 KV 캐싱, 최적화된 메모리 관심 메커니즘 등 추론 성능을 크게 높이는 고급 기능을 제공합니다. vLLM 구성 파라미터를 조정하여 추론 성능을 개선하는 동시에 특정 사용 사례 요구 사항 및 워크로드 패턴을 충족할 수 있습니다. GPU 포화를 달성하려면 적절한 구성이 필수적입니다. 높은 처리량, 짧은 지연 시간 및 비용 효율적인 작업을 제공하면서 비용이 많이 드는 GPU 리소스에서 최대 가치를 추출해야 합니다. 다음 최적화는 EKS에서 vLLM 배포의 성능을 극대화하는 데 도움이 됩니다.
vLLM 구성 벤치마크
사용 사례에 맞게 vLLM 구성 파라미터를 조정하려면 GuideLLM
기본 vLLM 구성
다음은 vLLM을 실행하는 데 사용된 기준 구성입니다.
| vLLM 파라미터 | 설명 |
|---|---|
|
tensor_parallel_size: 1 |
1개의 GPU에 모델 배포 |
|
gpu_memory_utilization: 0.90 |
시스템 오버헤드에 대해 10% GPU 메모리 예약 |
|
max_sequence_length: 8,192 |
최대 총 시퀀스 길이(입력 + 출력) |
|
max_num_seqs: 1 |
GPU당 최대 동시 요청 수(배치 처리) |
이 기준 설정으로 GuideLLM을 실행하여 성능 기준을 수립합니다. 이 테스트에서 GuideLLM은 256개의 토큰 요청과 128개의 토큰 응답으로 초당 1개의 요청을 생성하도록 구성됩니다.
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
예상 결과:
기준 벤치마크 결과

조정된 vLLM 구성
GPU 리소스 및 병렬화를 더 잘 활용하도록 vLLM 파라미터를 조정합니다.
| vLLM 파라미터 | 설명 |
|---|---|
|
tensor_parallel_size: 1 |
GPU를 1개로 유지합니다. 텐서 병렬화는 vLLM에서 사용할 GPU 수와 일치해야 합니다. |
|
gpu_memory_utilization: 0.92 |
가능하면 오버헤드 GPU 메모리를 줄이는 동시에 vLLM이 오류 없이 계속 실행되도록 보장 |
|
max_sequence_length: 4,096 |
사용 사례 요구 사항에 따라 최대 시퀀스 조정, 최대 시퀀스가 낮을수록 병렬화 향상에 사용할 수 있는 리소스가 확보됨 |
|
max_num_seqs: 8 |
최대 시퀀스를 늘리면 처리량이 증가하지만 지연 시간도 늘어납니다. 사용 사례 요구 사항 내에서 지연 시간을 유지하면서 처리량을 극대화하려면 이 값을 늘립니다. |
kubectl 패치 명령을 사용하여 실행 중인 배포에 이러한 변경 사항을 적용합니다.
kubectl patch deployment vllm-inference-app --type='json' -p='[ {"op": "replace", "path": "/spec/template/spec/containers/0/args/4", "value": "--gpu-memory-utilization=0.92"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/5", "value": "--max-model-len=4096"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/6", "value": "--max-num-seqs=8"} ]'
vLLM 포드가 Ready 1/1 상태인지 확인합니다.
kubectl get pod -l app=vllm-inference-app -w
예상 결과:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
그런 다음 이전과 동일한 벤치마킹 값을 사용하여 GuideLLM을 다시 실행합니다.
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
예상 결과:
최적화된 벤치마크 결과
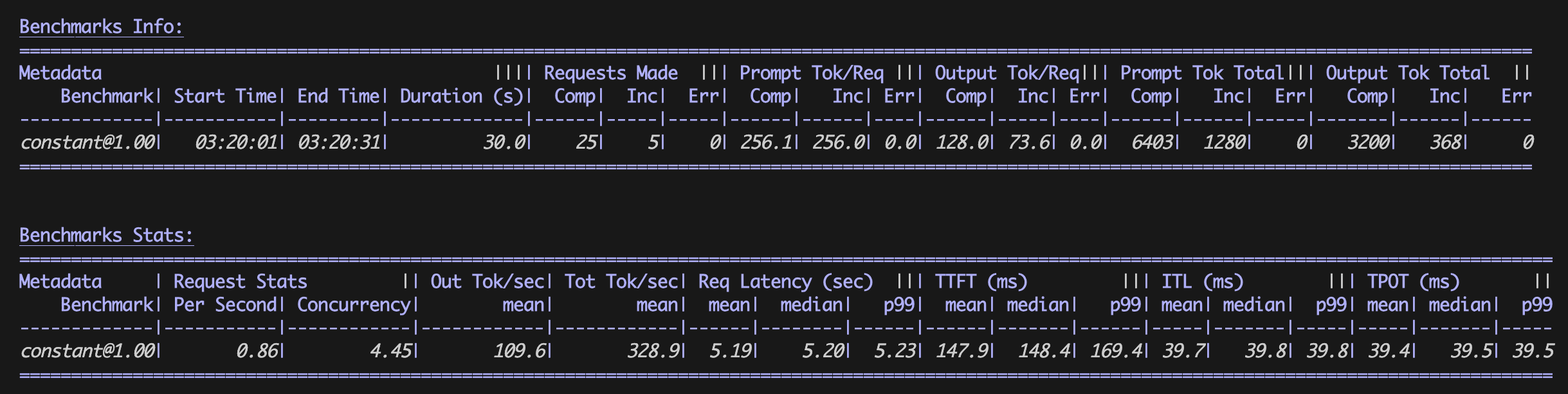
벤치마킹 결과
컴퓨팅 벤치마킹은 기준 및 최적화된 vLLM 구성 모두에 대한 테이블을 생성합니다.
| 평균값 | 기준 구성 | 최적화된 구성 |
|---|---|---|
|
RPS |
0.23개 요청/초 |
0.86개 요청/초 |
|
E2E |
12.99초 |
5.19초 |
|
TTFT |
8637.2 ms |
147.9 ms |
|
TPOT |
34.0 ms |
39.5 ms |
최적화된 vLLM 구성에서는 출력 토큰당 시간(TPOT)을 매우 작은 시간(밀리초 단위)만 증가시키면서 추론 처리량(RPS)을 크게 개선하고 지연 시간(E2E, TTFT)을 줄였습니다. 이러한 결과는 vLLM이 추론 성능을 크게 개선하여 각 컨테이너가 비용 효율적인 작업을 위해 더 적은 시간에 더 많은 요청을 처리할 수 있도록 하는 방법을 보여줍니다.
