기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Couchbase Server에서 마이그레이션
소개
이 가이드에서는 Couchbase Server에서 Amazon DocumentDB로 마이그레이션할 때 고려해야 할 주요 사항을 제공합니다. 마이그레이션의 검색, 계획, 실행 및 검증 단계에 대한 고려 사항을 설명합니다. 또한 오프라인 및 온라인 마이그레이션을 수행하는 방법도 설명합니다.
Amazon DocumentDB와 비교
| 카우치베이스 서버 | Amazon DocumentDB | |
|---|---|---|
| 데이터 조직 | 버전 7.0 이상에서는 데이터가 버킷, 범위 및 컬렉션으로 구성됩니다. 이전 버전에서는 데이터가 버킷으로 구성됩니다. | 데이터는 데이터베이스와 컬렉션으로 구성됩니다. |
| 호환성 | 각 서비스(예: 데이터, 인덱스, 검색 등)에는 별도의 APIs가 있습니다. 보조 조회는 ANSI 표준 SQL을 기반으로 하는 쿼리 언어인 SQL++(이전에는 N1QL이라고 함)를 사용하므로 많은 개발자에게 친숙합니다. | Amazon DocumentDB는 MongoDB API와 호환됩니다. |
| 아키텍처 | 스토리지는 각 클러스터 인스턴스에 연결됩니다. 스토리지와 독립적으로 컴퓨팅을 확장할 수 없습니다. | Amazon DocumentDB는 클라우드용으로 설계되었으며 기존 데이터베이스 아키텍처의 제한을 방지합니다. 컴퓨팅 계층과 스토리지 계층은 Amazon DocumentDB에서 분리되며 컴퓨팅 계층은 스토리지와 독립적으로 확장할 수 있습니다. Amazon DocumentDB |
| 온디맨드 읽기 용량 추가 | 인스턴스를 추가하여 클러스터를 확장할 수 있습니다. 스토리지는 서비스가 실행되는 인스턴스에 연결되므로 확장하는 데 걸리는 시간은 새 인스턴스로 이동하거나 재조정해야 하는 데이터의 양에 따라 달라집니다. | 클러스터에 최대 15개의 Amazon DocumentDB 복제본을 생성하여 Amazon DocumentDB 클러스터에 대한 읽기 조정을 수행할 수 있습니다. Amazon DocumentDB 스토리지 계층에는 영향이 없습니다. |
| 노드 장애로부터 빠르게 복구 | 클러스터에는 자동 장애 조치 기능이 있지만 클러스터를 최대 강도로 되돌리는 데 걸리는 시간은 새 인스턴스로 이동해야 하는 데이터의 양에 따라 달라집니다. | Amazon DocumentDB는 일반적으로 30초 이내에 기본를 장애 조치하고 클러스터의 데이터 양에 관계없이 8~10분 내에 클러스터를 최대 강도로 복원할 수 있습니다. |
| 데이터 증가에 따라 스토리지 확장 | 자체 관리형 클러스터의 경우 스토리지 및 IOs 자동으로 확장되지 않습니다. | Amazon DocumentDB 스토리지 및 IOs 자동으로 확장됩니다. |
| 성능에 영향을 주지 않고 데이터 백업 | 백업은 백업 서비스에서 수행되며 기본적으로 활성화되지 않습니다. 스토리지와 컴퓨팅은 분리되지 않으므로 성능에 영향을 미칠 수 있습니다. | Amazon DocumentDB 백업은 기본적으로 활성화되어 있으며 끌 수 없습니다. 백업은 스토리지 계층에서 처리되므로 컴퓨팅 계층에 영향을 미치지 않습니다. Amazon DocumentDB는 클러스터 스냅샷에서 복원하고 특정 시점으로 복원할 수 있도록 지원합니다. |
| 데이터 내구성 | 클러스터에는 최대 3개의 데이터 복제본 복사본이 있을 수 있으며, 총 4개의 복사본이 있을 수 있습니다. 데이터 서비스가 실행 중인 각 인스턴스에는 활성 및 1, 2 또는 3개의 데이터 복제본 사본이 있습니다. | Amazon DocumentDB는 쓰기 쿼럼이 4인 컴퓨팅 인스턴스의 수에 관계없이 6개의 데이터 복사본을 유지하며 true를 유지합니다. 클라이언트는 스토리지 계층이 4개의 데이터 복사본을 유지한 후 승인을 받습니다. |
| 일관성 | K/V 작업에 대한 즉각적인 일관성이 지원됩니다. Couchbase SDK는 데이터의 활성 사본이 포함된 특정 인스턴스로 K/V 요청을 라우팅하므로 업데이트가 승인되면 클라이언트가 해당 업데이트를 읽도록 보장됩니다. 다른 서비스(인덱스, 검색, 분석, 이벤트)에 대한 업데이트 복제는 최종적으로 일관됩니다. | Amazon DocumentDB 복제본은 최종적으로 일관됩니다. 즉각적인 일관성 읽기가 필요한 경우 클라이언트는 기본 인스턴스에서 읽을 수 있습니다. |
| 복제 | Cross-Data Center Replication(XDCR)은 많은 토폴로지에서 필터링된 액티브-패시브/액티브-액티브 데이터 복제를 제공합니다. | Amazon DocumentDB 글로벌 클러스터는 1:many(최대 10개) 토폴로지에서 액티브-패시브 복제를 제공합니다. |
Discovery
Amazon DocumentDB로 마이그레이션하려면 기존 데이터베이스 워크로드를 철저히 이해해야 합니다. 워크로드 검색은 Couchbase 클러스터 구성 및 운영 특성, 즉 데이터 세트, 인덱스 및 워크로드를 분석하여 중단을 최소화하면서 원활한 전환을 보장하는 프로세스입니다.
클러스터 구성
카우치베이스는 각 기능이 서비스에 해당하는 서비스 중심 아키텍처를 사용합니다. Couchbase 클러스터에 대해 다음 명령을 실행하여 사용 중인 서비스를 확인합니다(노드에 대한 정보 가져오기
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
샘플 출력:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
카우치베이스 서비스에는 다음이 포함됩니다.
데이터 서비스(kv)
데이터 서비스는 메모리 및 디스크의 데이터에 대한 읽기/쓰기 액세스를 제공합니다.
Amazon DocumentDB는 MongoDB API를 통해 JSON 데이터에 대한 K/V 작업을 지원합니다.
쿼리 서비스(n1ql)
쿼리 서비스는 SQL++를 통한 JSON 데이터 쿼리를 지원합니다.
Amazon DocumentDB는 MongoDB API를 통한 JSON 데이터 쿼리를 지원합니다.
인덱스 서비스(인덱스)
인덱스 서비스는 데이터에 대한 인덱스를 생성하고 유지 관리하므로 쿼리 속도가 빨라집니다.
Amazon DocumentDB는 MongoDB API를 통해 기본 기본 인덱스와 JSON 데이터에 대한 보조 인덱스 생성을 지원합니다.
검색 서비스(ft)
검색 서비스는 전체 텍스트 검색을 위한 인덱스 생성을 지원합니다.
Amazon DocumentDB의 기본 전체 텍스트 검색 기능을 사용하면 MongoDB API를 통해 특수 목적 텍스트 인덱스를 사용하여 대규모 텍스트 데이터 세트에서 텍스트 검색을 수행할 수 있습니다. 고급 검색 사용 사례의 경우 Amazon DocumentDB와 Amazon OpenSearch Service의 제로 ETL 통합
분석 서비스(cbas)
분석 서비스는 거의 실시간으로 JSON 데이터 분석을 지원합니다.
Amazon DocumentDB는 MongoDB API를 통해 JSON 데이터에 대한 임시 쿼리를 지원합니다. Amazon EMR에서 실행되는 Apache Spark를 사용하여 Amazon DocumentDB의 JSON 데이터에 대해 복잡한 쿼리를 실행할 수도 있습니다
이벤트 서비스(이벤팅)
이벤트 서비스는 데이터 변경에 대한 응답으로 사용자 정의 비즈니스 로직을 실행합니다.
Amazon DocumentDB는 Amazon DocumentDB 클러스터에서 데이터가 변경될 때마다 AWS Lambda 함수를 호출하여 이벤트 기반 워크로드를 자동화합니다.
백업 서비스(백업)
백업 서비스는 전체 및 증분 데이터 백업을 예약하고 이전 데이터 백업을 병합합니다.
Amazon DocumentDB는 보존 기간이 1~35일인 Amazon S3에 데이터를 지속적으로 백업하므로 백업 보존 기간 내의 어느 시점으로든 빠르게 복원할 수 있습니다. 또한 Amazon DocumentDB는 이러한 연속 백업 프로세스의 일환으로 데이터의 스냅샷을 자동으로 생성합니다. 를 사용하여 Amazon DocumentDB의 백업 및 복원을 관리할 수도 있습니다 AWS Backup.
운영 특성
카우치베이스용 검색 도구를
데이터 세트
도구는 다음 버킷, 범위 및 컬렉션 정보를 검색합니다.
버킷 이름
버킷 유형
범위 이름
컬렉션 이름
총 크기(바이트)
총 항목 수
항목 크기(바이트)
인덱스
도구는 모든 버킷에 대해 다음과 같은 인덱스 통계와 모든 인덱스 정의를 검색합니다. Amazon DocumentDB는 각 컬렉션에 대한 기본 인덱스를 자동으로 생성하기 때문에 기본 인덱스는 제외됩니다.
버킷 이름
범위 이름
컬렉션 이름
인덱스 이름
인덱스 크기(바이트)
워크로드
도구는 K/V 및 N1QL 쿼리 지표를 검색합니다. K/V 지표 값은 버킷 수준에서 수집되고 SQL++ 지표는 클러스터 수준에서 수집됩니다.
도구 명령줄 옵션은 다음과 같습니다.
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
다음은 명령 예제입니다.
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
K/V 지표 값은 지난 주 동안 10분마다 샘플을 기반으로 합니다(HTTP 메서드 및 URI
collection-stats.csv – 버킷, 범위 및 수집 정보
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv – 인덱스 이름 및 크기
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv - 모든 버킷에 대한 지표 가져오기, 설정 및 삭제
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv – SQL++ 클러스터에 대한 지표 선택, 삭제 및 삽입
selects,deletes,inserts 0,132,87
indexs-<bucket-name>.txt - 버킷에 있는 모든 인덱스의 인덱스 정의입니다. Amazon DocumentDB는 각 컬렉션에 대한 기본 인덱스를 자동으로 생성하기 때문에 기본 인덱스는 제외됩니다.
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
계획
계획 단계에서는 Amazon DocumentDB 클러스터 요구 사항을 결정하고 Couchbase 버킷, 범위 및 컬렉션을 Amazon DocumentDB 데이터베이스 및 컬렉션에 매핑합니다.
Amazon DocumentDB 클러스터 요구 사항
검색 단계에서 수집된 데이터를 사용하여 Amazon DocumentDB 클러스터의 크기를 조정합니다. Amazon DocumentDB 클러스터 크기 조정에 대한 자세한 내용은 인스턴스 크기 조정을 참조하세요.
버킷, 범위 및 컬렉션을 데이터베이스 및 컬렉션에 매핑
Amazon DocumentDB 클러스터(들)에 존재할 데이터베이스와 컬렉션을 결정합니다. Couchbase 클러스터에서 데이터가 구성되는 방식에 따라 다음 옵션을 고려하세요. 이는 유일한 옵션은 아니지만 고려해야 할 시작점을 제공합니다.
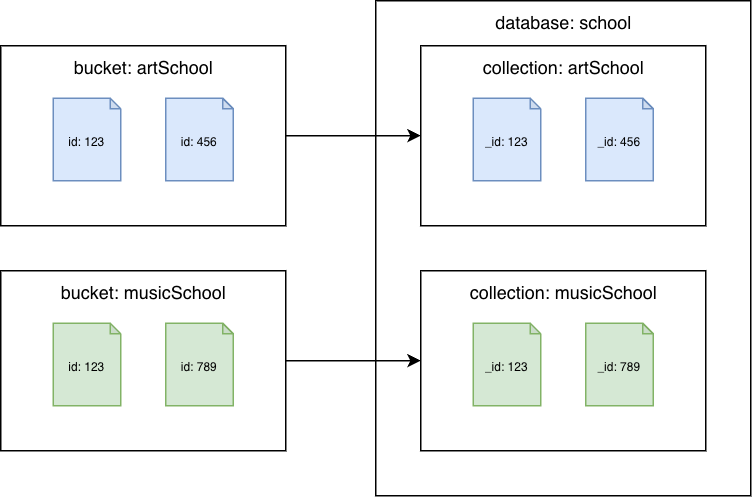
Couchbase Server 6.x 이하
카우치베이스 버킷에서 Amazon DocumentDB 컬렉션으로
각 버킷을 다른 Amazon DocumentDB 컬렉션으로 마이그레이션합니다. 이 시나리오에서는 Couchbase 문서 id 값이 Amazon DocumentDB _id 값으로 사용됩니다.
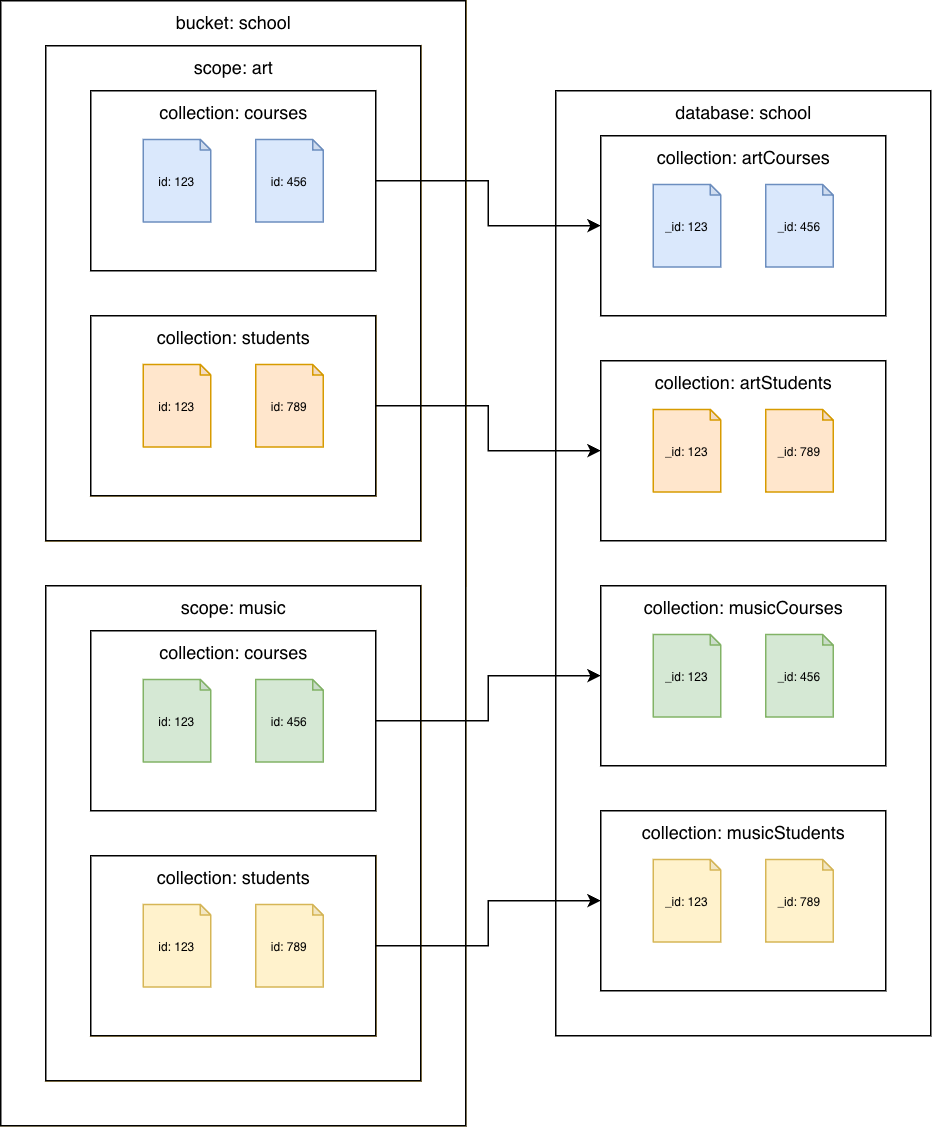
Couchbase Server 7.0 이상
카우치베이스 컬렉션에서 Amazon DocumentDB 컬렉션으로
각 컬렉션을 다른 Amazon DocumentDB 컬렉션으로 마이그레이션합니다. 이 시나리오에서는 Couchbase 문서 id 값이 Amazon DocumentDB _id 값으로 사용됩니다.
마이그레이션
인덱스 마이그레이션
Amazon DocumentDB로 마이그레이션하려면 데이터뿐만 아니라 인덱스를 전송하여 쿼리 성능을 유지하고 데이터베이스 작업을 최적화해야 합니다. 이 섹션에서는 호환성과 효율성을 보장하면서 인덱스를 Amazon DocumentDB로 마이그레이션하기 위한 step-by-step 프로세스를 간략하게 설명합니다.
Amazon Q를 사용하여 SQL++ CREATE INDEX 문을 Amazon DocumentDB createIndex() 명령으로 변환합니다.
Couchbase용 검색 도구에서 생성한 indexes-<bucket name>.txt 파일(들)을 업로드합니다.
다음 프롬프트를 입력합니다.
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q는 동등한 Amazon DocumentDB createIndex() 명령을 생성합니다. Couchbase 버킷, 범위 및 컬렉션을 Amazon DocumentDB 컬렉션에 매핑한 방법에 따라 컬렉션 이름을 업데이트해야 할 수 있습니다.
예제:
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Amazon Q 출력 예제(발췌):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Amazon Q가 변환할 수 없는 인덱스에 대한 자세한 내용은 Amazon DocumentDB 인덱스 및 인덱스 및 인덱스 속성 관리를 참조하세요. mongo-apis.html#mongo-apis-index
MongoDB APIs를 사용하기 위한 코드 리팩터링
클라이언트는 Couchbase SDKs를 사용하여 Couchbase Server에 연결합니다. Amazon DocumentDB 클라이언트는 MongoDB 드라이버를 사용하여 Amazon DocumentDB에 연결합니다. Couchbase SDKs에서 지원하는 모든 언어는 MongoDB 드라이버에서도 지원됩니다. 해당 언어의 드라이버에 대한 자세한 내용은 MongoDB
APIs는 Couchbase Server와 Amazon DocumentDB 간에 다르므로 적절한 MongoDB APIs. Amazon Q를 사용하여 K/V API 호출 및 SQL++ 쿼리를 동등한 MongoDB APIs.
소스 코드 파일(들)을 업로드합니다.
다음 프롬프트를 입력합니다.
Convert the Couchbase API code to Amazon DocumentDB API code
Hello Couchbase
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Python, Node.js, PHP, Go, Java, C#/에서 Amazon DocumentDB에 연결하는 예제는 Amazon DocumentDB에 프로그래밍 방식으로 연결을 참조하세요. Amazon DocumentDB NET, R 및 Ruby.
마이그레이션 접근 방식 선택
Amazon DocumentDB로 데이터를 마이그레이션할 때 다음 두 가지 옵션이 있습니다.
오프라인 마이그레이션
다음과 같은 경우 오프라인 마이그레이션을 고려하세요.
가동 중지 허용: 오프라인 마이그레이션에는 소스 데이터베이스에 대한 쓰기 작업 중지, 데이터 내보내기, Amazon DocumentDB로 가져오기가 포함됩니다. 이 프로세스는 애플리케이션에 가동 중지 시간을 발생시킵니다. 애플리케이션 또는 워크로드가이 기간 동안 사용할 수 없는 경우 오프라인 마이그레이션이 실행 가능한 옵션입니다.
소규모 데이터 세트 마이그레이션 또는 개념 증명 수행: 소규모 데이터 세트의 경우 내보내기 및 가져오기 프로세스에 필요한 시간이 비교적 짧기 때문에 오프라인 마이그레이션이 빠르고 간단한 방법입니다. 가동 중지 시간이 덜 중요한 개발, 테스트 및 proof-of-concept 환경에도 적합합니다.
단순성이 우선 순위입니다. cbexport 및 mongoimport를 사용하는 오프라인 방법은 일반적으로 데이터를 마이그레이션하는 가장 간단한 접근 방식입니다. 온라인 마이그레이션 방법과 관련된 변경 데이터 캡처(CDC)의 복잡성을 방지합니다.
지속적인 변경 사항을 복제할 필요가 없음: 마이그레이션 중에 소스 데이터베이스가 변경 사항을 적극적으로 수신하지 않거나 마이그레이션 프로세스 중에 이러한 변경 사항을 캡처하여 대상에 적용하는 것이 중요하지 않은 경우 오프라인 접근 방식이 적합합니다.
Couchbase Server 6.x 이하
카우치베이스 버킷에서 Amazon DocumentDB 컬렉션으로
cbexport json--format 옵션의 경우 lines 또는를 사용할 수 있습니다list.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
적절한 옵션과 함께 mongoimport를 사용하여 Amazon DocumentDB 컬렉션으로 데이터를 가져와 줄 또는 목록을 가져옵니다.
줄:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
목록:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 이상
오프라인 마이그레이션을 수행하려면 cbexport 및 mongoimport 도구를 사용합니다.
기본 범위 및 기본 컬렉션이 있는 카우치베이스 버킷
cbexport json--format 옵션의 경우 lines 또는를 사용할 수 있습니다list.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
적절한 옵션과 함께 mongoimport를 사용하여 Amazon DocumentDB 컬렉션으로 데이터를 가져와 줄 또는 목록을 가져옵니다.
줄:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
목록:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
카우치베이스 컬렉션에서 Amazon DocumentDB 컬렉션으로
cbexport json--include-data 옵션을 사용하여 각 컬렉션을 내보냅니다. --format 옵션의 경우 lines 또는를 사용할 수 있습니다list. --scope-field 및 --collection-field 옵션을 사용하여 범위 및 모음의 이름을 각 JSON 문서의 지정된 필드에 저장합니다.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
cbexport는 내보낸 모든 문서에 _scope 및 _collection 필드를 추가했으므로 검색 및 교체, sed또는 원하는 방법을 통해 내보내기 파일의 모든 문서에서 제거할 수 있습니다.
줄 또는 목록을 가져오는 적절한 옵션과 함께 mongoimport를 사용하여 각 컬렉션의 데이터를 Amazon DocumentDB 컬렉션으로 가져옵니다.
줄:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
목록:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
온라인 마이그레이션
가동 중지 시간을 최소화해야 하고 지속적인 변경 사항을 거의 실시간으로 Amazon DocumentDB에 복제해야 하는 경우 온라인 마이그레이션을 고려하세요.
Amazon DocumentDB로 라이브 마이그레이션을 수행하는 방법을 알아보려면 Couchbase에서
Couchbase Server 6.x 이하
카우치베이스 버킷에서 Amazon DocumentDB 컬렉션으로
Couchbase용 마이그레이션 유틸리티document.id.strategy 파라미터는 메시지 키 값을 _id 필드 값으로 사용하도록 구성됩니다(싱크 커넥터 ID 전략 속성
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 이상
기본 범위 및 기본 컬렉션이 있는 카우치베이스 버킷
Couchbase용 마이그레이션 유틸리티document.id.strategy 파라미터는 메시지 키 값을 _id 필드 값으로 사용하도록 구성됩니다(싱크 커넥터 ID 전략 속성
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
카우치베이스 컬렉션에서 Amazon DocumentDB 컬렉션으로
각 범위의 각 Couchbase 컬렉션을 별도의 주제로 스트리밍하도록 소스 커넥터를
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
각 주제에서 별도의 Amazon DocumentDB 컬렉션으로 스트리밍하도록 싱크 커넥터를
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
검증
이 섹션에서는 Amazon DocumentDB로 마이그레이션한 후 데이터 일관성과 무결성을 확인하는 자세한 검증 프로세스를 제공합니다. 검증 단계는 마이그레이션 방법에 관계없이 적용됩니다.
모든 컬렉션이 대상에 존재하는지 확인
카우치베이스 소스
옵션 1: 워크벤치 쿼리
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
옵션 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Amazon DocumentDB 대상
mongosh(Amazon DocumentDB 클러스터에 연결 참조):
db.getSiblingDB('<database>') db.getCollectionNames()
Souce 클러스터와 대상 클러스터 간의 문서 수 확인
카우치베이스 소스
Couchbase Server 6.x 이하
옵션 1: 워크벤치 쿼리
SELECT COUNT(*) FROM `<bucket>`
옵션 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 이상
옵션 1: 워크벤치 쿼리
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
옵션 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB 대상
mongosh(Amazon DocumentDB 클러스터에 연결 참조):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
소스 클러스터와 대상 클러스터 간의 문서 비교
카우치베이스 소스
Couchbase Server 6.x 이하
옵션 1: 워크벤치 쿼리
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
옵션 2: cbq
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 이상
옵션 1: 워크벤치 쿼리
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
옵션 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB 대상
mongosh(Amazon DocumentDB 클러스터에 연결 참조):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
