AWS Data Pipeline 는 더 이상 신규 고객이 사용할 수 없습니다. 의 기존 고객은 평소와 같이 서비스를 계속 사용할 AWS Data Pipeline 수 있습니다. 자세히 알아보기
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
명령줄을 사용하여 클러스터 시작
Amazon EMR 클러스터를 정기적으로 실행하여 웹 로그를 분석하거나 과학 데이터 분석을 수행하는 경우 AWS Data Pipeline 를 사용하여 Amazon EMR 클러스터를 관리할 수 있습니다. 를 사용하면 클러스터가 시작되기 전에 충족해야 하는 사전 조건을 지정할 AWS Data Pipeline수 있습니다(예: 오늘의 데이터가 Amazon S3에 업로드되었는지 확인). 이 자습서는 단순한 Amazon EMR 기반 파이프라인의 모델이 될 수 있는 클러스터 또는 좀 더 관련된 파이프라인의 일부로 클러스터를 시작하는 방법을 설명합니다.
사전 조건
CLI를 사용하려면 다음 단계를 완료해야 합니다.
-
명령줄 인터페이스(CLI)를 설치하고 구성합니다. 자세한 내용은 액세스 AWS Data Pipeline 단원을 참조하십시오.
-
DataPipelineDefaultRole 및 DataPipelineDefaultResourceRole이라는 이름의 IAM 역할이 존재하는지 확인하십시오. AWS Data Pipeline 콘솔은 이러한 역할을 자동으로 생성합니다. AWS Data Pipeline 콘솔을 한 번 이상 사용하지 않은 경우 이러한 역할을 수동으로 생성해야 합니다. 자세한 내용은 에 대한 IAM 역할 AWS Data Pipeline 단원을 참조하십시오.
파이프라인 정의 파일 생성
다음 코드는 Amazon EMR이 제공한 기존 Hadoop 스트리밍 작업을 실행하는 단순한 Amazon EMR 클러스터의 파이프라인 정의 파일입니다. 이 샘플 애플리케이션은 이름이 WordCount이며, Amazon EMR 콘솔을 사용하여 실행할 수도 있습니다.
이 코드를 텍스트 파일로 복사하고 MyEmrPipelineDefinition.json으로 저장합니다. Amazon S3 버킷 위치를 사용자가 소유한 Amazon S3 버킷 이름으로 바꿔야 합니다. 시작 및 종료 날짜도 바꿔야 합니다. 클러스터startDateTime를 즉시 시작하려면를 과거 1일, 미래 endDateTime 1일로 설정합니다. AWS Data Pipeline 그런 다음는 작업 백로그로 인식되는 것을 해결하기 위해 "지난 기한" 클러스터를 즉시 시작하기 시작합니다. 이 채우기는 첫 번째 클러스터가 AWS Data Pipeline 시작되기까지 한 시간 정도 기다릴 필요가 없음을 의미합니다.
{ "objects": [ { "id": "Hourly", "type": "Schedule", "startDateTime": "2012-11-19T07:48:00", "endDateTime": "2012-11-21T07:48:00", "period": "1 hours" }, { "id": "MyCluster", "type": "EmrCluster", "masterInstanceType": "m1.small", "schedule": { "ref": "Hourly" } }, { "id": "MyEmrActivity", "type": "EmrActivity", "schedule": { "ref": "Hourly" }, "runsOn": { "ref": "MyCluster" }, "step": "/home/hadoop/contrib/streaming/hadoop-streaming.jar,-input,s3n://elasticmapreduce/samples/wordcount/input,-output,s3://myawsbucket/wordcount/output/#{@scheduledStartTime},-mapper,s3n://elasticmapreduce/samples/wordcount/wordSplitter.py,-reducer,aggregate" } ] }
이 파이프라인은 다음 3개의 객체가 있습니다.
-
Hourly: 작업 일정을 나타냅니다. 활동에서 필드 하나로 일정을 설정할 수 있습니다. 그러면 활동이 해당 일정(이 경우는 매시간)에 따라 실행됩니다. -
MyCluster, 이는 클러스터를 실행할 때 사용한 Amazon EC2 인스턴스의 세트를 나타냅니다. 클러스터로 실행할 EC2 인스턴스의 크기와 수를 지정할 수 있습니다. 인스턴스 수를 지정하지 않으면 클러스터가 마스터 노드와 작업 노드 2개로 시작됩니다. 클러스터를 시작할 서브넷을 지정할 수 있습니다. Amazon EMR이 제공하는 AMI에 추가 소프트웨어를 로드할 부트스트랩 작업 같이 클러스터에 구성을 더 추가할 수 있습니다. -
MyEmrActivity, 이는 클러스터에서 처리할 계산을 나타냅니다. Amazon EMR은 스트리밍, 캐스케이딩 및 Scripted Hive를 비롯한 여러 유형의 클러스터를 지원합니다.runsOn필드는 클러스터의 기본 사양으로 사용하는 MyCluster를 다시 참조합니다.
파이프라인 정의 업로드 및 활성화
파이프라인 정의를 업로드하고 파이프라인을 활성화해야 합니다. 다음 예제 명령에서 pipeline_name을 파이프라인의 레이블로 대체하고, pipeline_file을 파이프라인 정의 .json 파일의 정규화된 경로로 대체하십시오.
AWS CLI
파이프라인 정의를 생성하고 파이프라인을 활성화하려면 다음 create-pipeline 명령을 사용하십시오. 대부분의 CLI 명령에서 이 값을 사용하므로 파이프라인 ID를 기록하십시오.
aws datapipeline create-pipeline --name{ "pipelineId": "df-00627471SOVYZEXAMPLE" }pipeline_name--unique-idtoken
파이프라인 정의를 업로드하려면 다음 put-pipeline-definition 명령을 사용하십시오.
aws datapipeline put-pipeline-definition --pipeline-id df-00627471SOVYZEXAMPLE --pipeline-definition file://MyEmrPipelineDefinition.json
파이프라인 유효성 검사에 성공하면 validationErrors 필드가 비게 됩니다. 경고가 있으면 검토해야 합니다.
파이프라인을 활성화하려면 다음 activate-pipeline 명령을 사용하십시오.
aws datapipeline activate-pipeline --pipeline-id df-00627471SOVYZEXAMPLE
다음 list-pipelines 명령을 사용하면 파이프라인 목록에 파이프라인이 표시되는지 확인할 수 있습니다.
aws datapipeline list-pipelines
파이프라인 실행 모니터링
Amazon EMR 콘솔을 AWS Data Pipeline 사용하여 시작된 클러스터를 볼 수 있으며 Amazon S3 콘솔을 사용하여 출력 폴더를 볼 수 있습니다.
에서 시작한 클러스터의 진행 상황을 확인하려면 AWS Data Pipeline
-
Amazon EMR 콘솔을 엽니다.
-
에서 생성된 클러스터의 이름은
<pipeline-identifier>_@<emr-cluster-name>_<launch-time>형식 AWS Data Pipeline 입니다.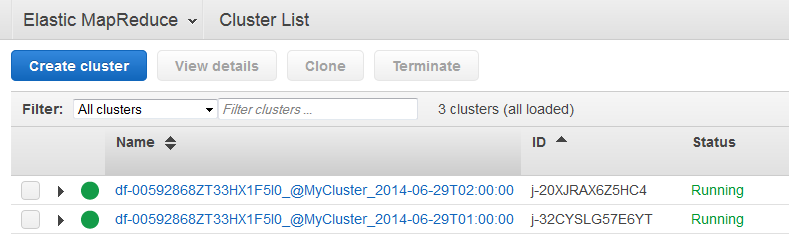
-
실행 중 하나가 완료되면, Amazon S3 콘솔을 열고 타임스탬프가 지정된 출력 폴더가 존재하는지 그리고 그 안에 클러스터의 예상 결과가 포함되는지 확인합니다.

