AWS Data Pipeline 는 더 이상 신규 고객이 사용할 수 없습니다. 의 기존 고객은 평소와 같이 서비스를 계속 사용할 AWS Data Pipeline 수 있습니다. 자세히 알아보기
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Task Runner AWS Data Pipeline관리형 리소스
에서 리소스를 시작하고 관리하면 AWS Data Pipeline웹 서비스는 파이프라인에서 작업을 처리하기 위해 해당 리소스에 Task Runner를 자동으로 설치합니다. 활동 객체의 runsOn필드용 전산 리소스(Amazon EC2 인스턴스 또는 Amazon EMR 클러스터)를 지정합니다. AWS Data Pipeline
가 이 리소스를 시작할 때 해당 리소스에 Task Runner를 설치하고 runsOn 필드가 이 리소스로 설정된 모든 활동 객체를 처리하도록 구성합니다. 가 리소스를 AWS Data Pipeline 종료하면 Task Runner 로그가 종료되기 전에 Amazon S3 위치에 게시됩니다.
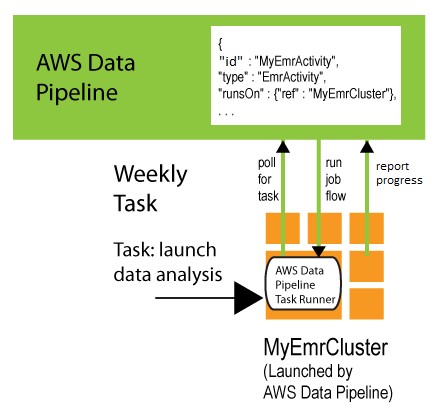
예를 들어, 파이프라인에서 EmrActivity를 사용할 경우 runsOn 필드에서 EmrCluster 리소스를 지정합니다. 는 해당 활동을 AWS Data Pipeline 처리할 때 Amazon EMR 클러스터를 시작하고 마스터 노드에 Task Runner를 설치합니다. 그러면 이 Task Runner는 runsOn 필드가 EmrCluster 객체로 설정된 활동의 작업을 처리합니다. 다음 파이프라인 정의 발췌 부분은 두 객체 사이의 이 관계를 설명합니다.
{ "id" : "MyEmrActivity", "name" : "Work to perform on my data", "type" : "EmrActivity", "runsOn" : {"ref" : "MyEmrCluster"}, "preStepCommand" : "scp remoteFiles localFiles", "step" : "s3://amzn-s3-demo-bucket/myPath/myStep.jar,firstArg,secondArg", "step" : "s3://amzn-s3-demo-bucket/myPath/myOtherStep.jar,anotherArg", "postStepCommand" : "scp localFiles remoteFiles", "input" : {"ref" : "MyS3Input"}, "output" : {"ref" : "MyS3Output"} }, { "id" : "MyEmrCluster", "name" : "EMR cluster to perform the work", "type" : "EmrCluster", "hadoopVersion" : "0.20", "keypair" : "myKeyPair", "masterInstanceType" : "m1.xlarge", "coreInstanceType" : "m1.small", "coreInstanceCount" : "10", "taskInstanceType" : "m1.small", "taskInstanceCount": "10", "bootstrapAction" : "s3://elasticmapreduce/libs/ba/configure-hadoop,arg1,arg2,arg3", "bootstrapAction" : "s3://elasticmapreduce/libs/ba/configure-other-stuff,arg1,arg2" }
이 활동 실행에 대한 정보와 예제는 EmrActivity 단원을 참조하세요.
파이프라인에 여러 AWS Data Pipeline관리형 리소스가 있는 경우 Task Runner가 각 리소스에 설치되고 모두 처리할 작업에 AWS Data Pipeline 대해 폴링됩니다.
