Amazon S3 Files 작업
주제
S3 Files이란 무엇인가요?
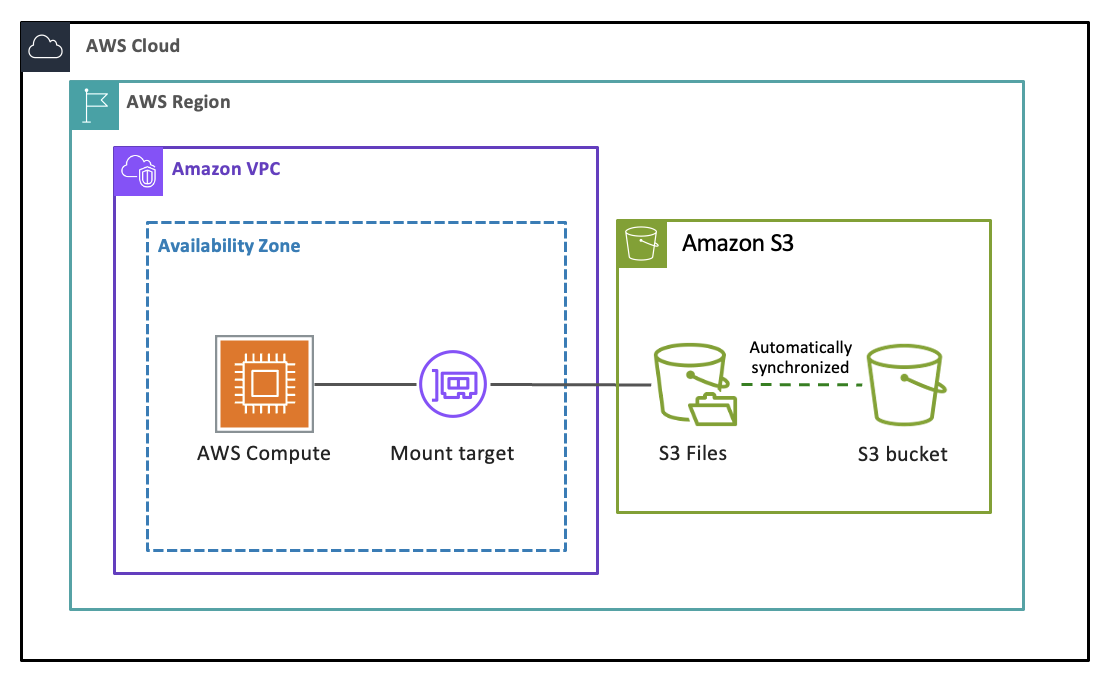
S3 Files는 모든 AWS 컴퓨팅 리소스를 Amazon S3의 데이터와 직접 연결하는 공유 파일 시스템입니다. 데이터가 S3를 벗어나지 않고도 전체 파일 시스템 의미 체계와 지연 시간이 짧은 성능을 갖춘 파일로 모든 S3 데이터에 빠르고 직접 액세스할 수 있습니다. 모든 파일 기반 애플리케이션, 에이전트 및 팀은 이미 의존하는 도구를 사용하여 파일 시스템으로 S3 데이터에 액세스하고 작업할 수 있습니다. Amazon EFS를 사용하여 구축된 S3 Files는 S3의 확장성, 내구성 및 비용 효율성을 갖춘 파일 시스템의 성능과 단순성을 제공합니다. 파일 및 디렉터리 작업을 사용하여 데이터를 읽고 쓰고 구성할 수 있으며 S3 Files는 버킷과 파일 시스템 간의 변경 사항 동기화를 관리합니다.
S3 Files는 어떻게 작동하나요?
S3 버킷 또는 버킷 내의 접두사에 연결된 S3 파일 시스템을 생성하고 EC2 인스턴스 또는 Lambda 함수와 같은 컴퓨팅 리소스에 탑재하면 S3 Files는 먼저 버킷 객체의 순회 보기를 파일로 표시합니다. 디렉터리와 열린 파일을 탐색하면 연결된 메타데이터와 콘텐츠가 파일 시스템의 고성능 스토리지에 배치됩니다. 파일을 읽을 때 S3 Files는 전체 데이터세트를 복제하지 않고 온디맨드로 고성능 스토리지에 파일 콘텐츠를 로드합니다. 데이터를 쓰면 쓰기가 고성능 스토리지로 이동하고 S3 버킷에 다시 동기화됩니다. S3 Files는 파일 시스템 작업을 사용자를 대신하여 효율적인 S3 요청으로 지능적으로 변환합니다. 많은 읽기 작업은 S3에서 직접 제공되는 데이터를 사용하여 파일 시스템을 완전히 우회합니다.
지연 시간은 작은 파일에 가장 중요하므로 고성능 스토리지(기본값 128KiB 미만)에 로드되는 항목에 대한 파일 크기 임계값을 구성할 수 있습니다. S3 Files는 두 가지 경우에 S3 버킷에서 파일을 직접 읽어 스트리밍합니다. 파일 데이터가 파일 시스템의 고성능 스토리지에 저장되어 있지 않은 경우와 데이터가 파일 시스템의 고성능 스토리지에 있더라도 1MiB 이상의 대용량 읽기인 경우가 그것입니다. S3 버킷은 높은 처리량에 최적화되어 있고, 파일 시스템의 고성능 스토리지 계층은 지연 시간이 짧은 액세스에 최적화되어 있습니다. S3 Files는 작은 파일(기본적으로 128KiB 미만)의 데이터를 비동기적으로 파일 시스템의 고성능 스토리지로 가져와 후속 읽기에서 짧은 지연 시간으로 액세스할 수 있도록 합니다. S3와 아직 동기화되지 않은 최근 수정 데이터는 항상 파일 시스템에서 제공됩니다. 자세한 내용은 S3 Files에 대한 동기화 사용자 지정 섹션을 참조하세요.
구성 가능한 기간(1~365일, 기본값 30) 내에 읽지 않은 데이터는 고성능 스토리지에서 자동으로 만료됩니다. 신뢰할 수 있는 데이터는 항상 S3에 유지되며 백그라운드 동기화는 파일 시스템과 버킷을 양방향으로 일관되게 유지합니다. 자세한 내용은 동기화 작동 방식 이해 섹션을 참조하세요.
S3 파일 시스템을 탑재하는 데 지원되는 컴퓨팅 서비스는 Amazon EC2, AWS Lambda, Amazon EKS 및 Amazon ECS입니다. 자세한 내용은 컴퓨팅 리소스에 S3 버킷 탑재 섹션을 참조하세요.
S3 Files를 처음 사용하나요?
S3 Files를 처음 사용하는 경우 자습서: S3 Files 시작하기에 따라 S3 콘솔 또는 AWS CLI를 사용하여 첫 번째 S3 파일 시스템을 생성합니다.
주요 개념
S3 Files 설명서 전체에서 다음 용어가 사용됩니다.
- 파일 시스템:
S3 버킷에 연결된 공유 파일 시스템입니다.
- 고성능 스토리지
파일 시스템 내에서 활성 파일 데이터 및 메타데이터가 상주하는 지연 시간이 짧은 스토리지 계층입니다. S3 Files는 이 스토리지를 자동으로 관리하여 파일에 액세스할 때 데이터를 복사하고 구성 가능한 만료 기간 내에 읽지 않은 데이터를 제거합니다. 고성능 스토리지에 있는 데이터에 대해 스토리지 요금을 지불합니다.
- 동기화
S3 Files가 활성 작업 데이터세트와 변경 사항을 파일 시스템과 S3 버킷 간에 일관되게 유지하는 프로세스입니다. 가져오면 S3 버킷의 데이터가 파일 시스템으로 복사됩니다. 내보내면 파일 시스템을 통해 변경한 내용이 S3 버킷으로 복사됩니다. S3 Files는 양방향으로 동기화를 자동으로 수행합니다.
- 탑재 대상
탑재 대상은 VPC의 단일 가용 영역 내에서 파일 시스템에 대한 네트워크 액세스를 제공합니다. 컴퓨팅 리소스에서 파일 시스템에 액세스하려면 하나 이상의 탑재 대상이 필요하며 가용 영역당 최대 하나의 탑재 대상을 생성할 수 있습니다.
- 액세스 포인트
액세스 포인트는 공유 데이터세트에 대한 대규모 데이터 액세스 관리를 간소화하는 파일 시스템에 대한 애플리케이션별 진입점입니다. 액세스 포인트를 사용하면 해당 액세스 포인트를 통해 이루어지는 모든 파일 시스템 요청에 대해 사용자 ID와 권한을 적용할 수 있습니다. AWS Management Console을 사용하여 파일 시스템을 생성하면 S3 Files는 파일 시스템에 대해 하나의 액세스 포인트를 자동으로 생성합니다.
특성
- 전체 데이터 복제가 필요 없는 고성능
S3 Files는 전체 데이터세트가 아닌 파일 시스템의 고성능 스토리지에 활성 작업 세트만 복사하여 지연 시간이 짧은 파일 액세스를 제공합니다. 자주 액세스하는 작은 파일은 고성능 스토리지에서 밀리초 미만에서 10밀리초 미만의 지연 시간으로 제공됩니다. 대용량 읽기는 집계 처리량의 초당 최대 테라바이트로 S3에서 직접 스트리밍됩니다. 즉, 사용하지 않거나 지연 시간이 짧은 데이터를 저장하거나 가져오는 데 드는 비용을 지불하지 않고도 대화형 워크로드의 파일 시스템 성능과 스트리밍 워크로드의 S3 처리량을 얻을 수 있습니다. 자세한 내용은 성능 사양 섹션을 참조하세요.
- 지능형 읽기 라우팅
S3 Files는 읽기 요청을 가장 적합한 스토리지 계층(S3 파일 시스템 또는 S3 버킷)으로 자동 라우팅하는 동시에 일관성, 잠금 및 POSIX 권한을 포함한 전체 파일 시스템 의미 체계를 유지합니다. 지연 시간을 줄이기 위해 고성능 스토리지에서 능동적으로 사용되는 파일의 작은 임의 읽기가 제공됩니다. 파일 시스템에 없는 데이터의 대규모 순차 읽기 및 읽기는 파일 시스템 데이터 요금 없이 높은 처리량을 위해 S3 버킷에서 직접 제공됩니다.
- 자동 동기화
S3 Files는 파일 시스템과 S3 버킷을 양방향으로 자동으로 일관되게 유지합니다. 파일 시스템을 통해 변경한 내용은 S3 버킷에 다시 복사되고 S3 버킷에 직접 적용된 변경 사항은 파일 시스템 보기에 반영됩니다. 가져온 데이터와 파일 시스템에 남아 있는 기간을 포함하여 동기화 동작을 사용자 지정할 수 있습니다. 자세한 내용은 동기화 작동 방식 이해 섹션을 참조하세요.
- 확장 가능한 성능
S3 Files는 워크로드 활동에 맞게 처리량과 IOPS를 자동으로 조정합니다. 성능 용량을 프로비저닝하거나 관리할 필요가 없으며 사용한 만큼만 비용을 지불하면 됩니다.
- 리전 내구성
고성능 스토리지 계층에 기록된 데이터는 Amazon S3와 동일한 내구성을 갖습니다. 동일한 AWS 리전 내에서 지리적으로 분리된 여러 가용 영역에 데이터를 중복 저장하여 데이터에 높은 내구성과 가용성을 제공합니다.
- 암호화:
S3 Files는 TLS를 사용하여 모든 전송 중 데이터와 AWS KMS 키를 사용하여 모든 저장 데이터를 암호화합니다. AWS 소유 키(기본값) 또는 자체 고객 관리형 키를 사용할 수 있습니다. 자세한 내용은 암호화 섹션을 참조하세요.
- 파일 시스템 의미 체계
S3 Files는 NFS 버전 4.2 및 4.1 프로토콜을 지원합니다. 쓰기 후 읽기 데이터 일관성, 파일 잠금 및 POSIX 권한과 같은 파일 file-system-access 의미 체계를 제공합니다.
S3 Files에 대한 요금은 어떻게 청구되나요?
고성능 스토리지에 상주하는 활성 데이터의 일부에 대해 스토리지 요금을 지불하고 파일 시스템의 고성능 스토리지에서 읽고 쓸 때 파일 시스템 액세스 요금을 지불합니다. S3 Files는 두 가지 경우에 S3 버킷에서 파일을 직접 읽어 스트리밍합니다. 파일 데이터가 파일 시스템의 고성능 스토리지에 저장되어 있지 않은 경우와 데이터가 파일 시스템의 고성능 스토리지에 있더라도 1MiB 이상의 대용량 읽기인 경우가 그것입니다. S3 버킷은 높은 처리량에 최적화되어 있고, 파일 시스템의 고성능 스토리지 계층은 지연 시간이 짧은 액세스에 최적화되어 있습니다. S3 Files는 작은 파일(기본적으로 128KiB 미만)의 데이터를 비동기적으로 파일 시스템의 고성능 스토리지로 가져와 후속 읽기에서 짧은 지연 시간으로 액세스할 수 있도록 합니다. 이러한 읽기에는 파일 시스템 액세스 요금 없이 표준 S3 GET 요청 비용만 발생합니다. 파일 시스템 액세스 요금은 동기화 작업에 적용됩니다. 데이터를 파일 시스템으로 가져오면 쓰기 요금이 발생하고 변경 사항을 S3로 다시 내보내면 읽기 요금이 발생합니다. 자세한 내용은 S3 Files 측정 방법 섹션을 참조하세요. 현재 요금은 S3 Files 요금 페이지
