Amazon RDS 제로 ETL 통합의 데이터 필터링
Amazon RDS 제로 ETL 통합은 데이터 필터링을 지원하므로 사용자는 소스 Amazon RDS 데이터베이스에서 대상 데이터 웨어하우스로 어떤 데이터가 복제될지 제어할 수 있습니다. 전체 데이터베이스를 복제하는 대신 하나 이상의 필터를 적용하여 특정 테이블을 선택적으로 포함하거나 제외할 수 있습니다. 이렇게 하면 관련 데이터만 전송되도록 하여 스토리지 및 쿼리 성능을 최적화할 수 있습니다. 현재 필터링 기능은 데이터베이스 및 테이블 수준으로 제한됩니다. 열 수준 및 행 수준 필터링은 지원되지 않습니다.
데이터 필터링은 다음과 같은 경우에 유용할 수 있습니다.
-
서로 다른 2개 이상의 소스 데이터베이스의 특정 테이블을 조인하며 데이터베이스 중의 전체 데이터가 필요하지 않은 경우
-
전체 데이터베이스 플릿 대신 테이블의 하위 집합만 사용해 분석을 수행하여 비용을 절감하려는 경우
-
특정 테이블에서 전화번호, 주소 또는 신용카드 세부 정보와 같은 민감한 정보를 필터링하는 경우
AWS Management Console, AWS Command Line Interface(AWS CLI) 또는 Amazon RDS API를 사용하여 제로 ETL 통합에 데이터 필터를 추가할 수 있습니다.
통합에서 프로비저닝된 클러스터를 대상으로 하는 경우 클러스터가 패치 180 이상이어야 데이터 필터링을 사용할 수 있습니다.
주제
데이터 필터의 형식
단일 통합에 대해 여러 필터를 정의할 수 있습니다. 각 필터는 필터 표현식의 패턴 중 하나와 일치하는 기존 및 미래 데이터베이스 테이블을 포함하거나 제외합니다. Amazon RDS 제로 ETL 통합은 데이터 필터링에 Maxwell 필터 구문
각 필터에는 다음 요소가 포함됩니다.
| 요소 | 설명 |
|---|---|
| 필터 유형 |
|
| 필터 표현식 |
쉼표로 구분된 패턴 목록. 표현식은 Maxwell 필터 구문 |
| 패턴 |
참고RDS for MySQL의 경우 데이터베이스와 테이블 이름 모두에서 정규 표현식이 지원됩니다. RDS for PostgreSQL의 경우 정규 표현식은 데이터베이스 이름이 아닌 스키마 및 테이블 이름에서만 지원됩니다. 열 수준 필터 또는 거부 목록은 포함할 수 없습니다. 단일 통합은 총 99개까지 패턴을 보유할 수 있습니다. 콘솔에서는 단일 필터 표현식 내에 패턴을 입력하거나 여러 표현식에 패턴을 분산시킬 수 있습니다. 단일 패턴은 길이가 256자를 초과할 수 없습니다. |
중요
RDS for PostgreSQL 소스 데이터베이스를 선택하는 경우 데이터 필터 패턴을 하나 이상 지정해야 합니다. 대상 데이터 웨어하우스로 복제하려면 패턴에 최소한 하나의 데이터베이스(database-name.*.*
다음 이미지는 콘솔의 RDS for MySQL 데이터 필터 구조를 보여줍니다.
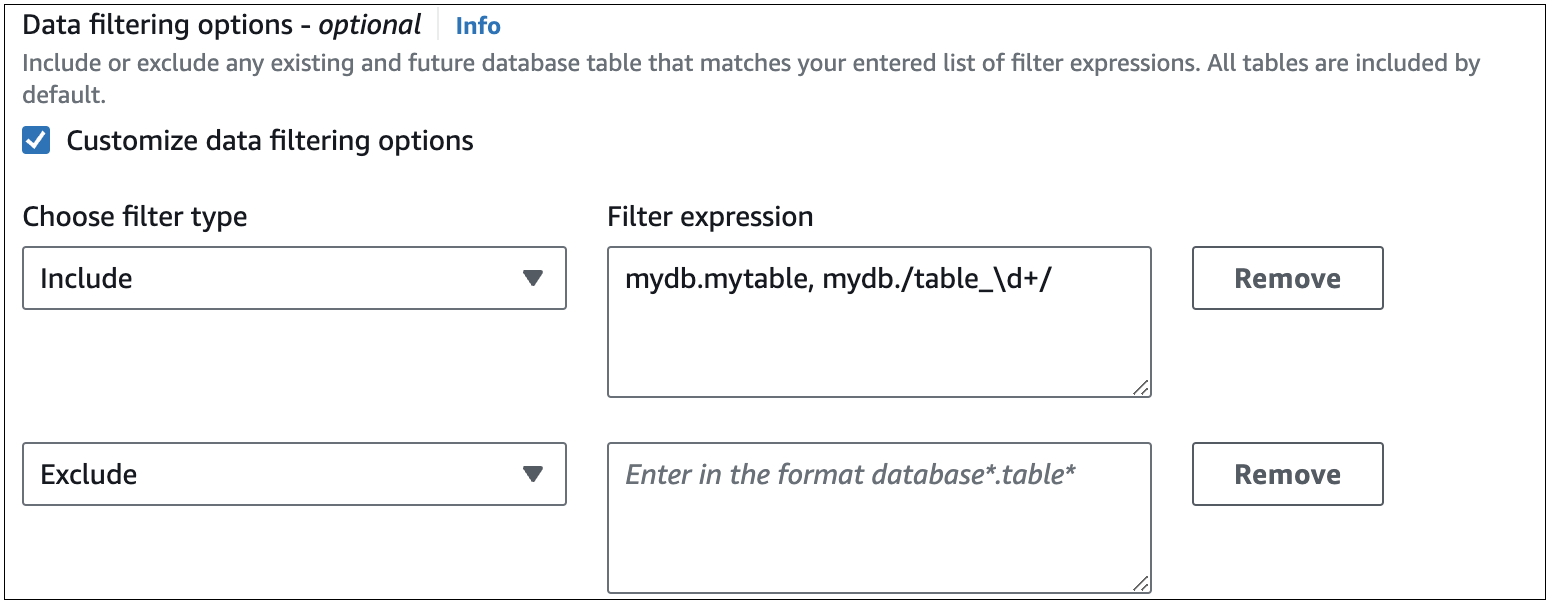
중요
개인 식별 정보, 기밀 정보 또는 민감한 정보를 필터 패턴에 포함하지 마세요.
AWS CLI의 데이터 필터
AWS CLI를 사용하여 데이터 필터를 추가하는 경우 콘솔의 구문과는 약간 다릅니다. 필터 유형(Include 또는 Exclude)을 각 패턴에 개별적으로 할당해야 하나의 필터 유형으로 여러 패턴을 그룹화할 수 있습니다.
예를 들어 콘솔에서는 쉼표로 구분된 다음과 같은 패턴을 단일 Include 스테이트먼트 내에 그룹화할 수 있습니다.
RDS for MySQL
mydb.mytable,mydb./table_\d+/
RDS for PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
하지만 AWS CLI를 사용할 때는 동일한 데이터 필터가 다음 형식이어야 합니다.
RDS for MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS for PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
"필터 로직"
통합에서 데이터 필터를 지정하지 않는 경우 Amazon RDS는 기본 필터(include:*.*)를 가정하고 모든 테이블을 대상 데이터 웨어하우스에 복제합니다. 그러나 최소 하나 이상의 필터를 추가하면 기본 로직이 exclude:*.*로 전환되어 기본적으로 모든 테이블이 제외됩니다. 이를 통해 복제에 포함할 데이터베이스와 테이블을 명시적으로 정의할 수 있습니다.
예를 들어 다음을 필터를 정의하는 경우:
'include: db.table1, include: db.table2'
Amazon RDS는 다음과 같이 필터를 평가합니다.
'exclude:*.*, include: db.table1, include: db.table2'
따라서 Amazon RDS는 db라는 데이터베이스의 table1 및 table2만 대상 데이터 웨어하우스에 복제합니다.
필터 우선순위
Amazon RDS는 지정된 순서대로 데이터 필터를 평가합니다. AWS Management Console에서는 필터 표현식을 왼쪽에서 오른쪽으로, 위에서 아래로 처리합니다. 두 번째 필터 또는 첫 번째 뒤에 오는 개별 패턴은 이를 재정의할 수 있습니다.
예를 들어 첫 번째 필터가 Include books.stephenking인 경우 books 데이터베이스의 stephenking 테이블만 포함됩니다. 하지만 두 번째 필터(Exclude books.*)를 추가하면 첫 번째 필터가 재정의됩니다. 이렇게 하면 books 인덱스의 테이블이 대상 데이터 웨어하우스로 복제되지 않습니다.
최소 1개의 필터를 지정하는 경우 로직은 가정된 exclude:*.*로 시작되며, 이는 모든 테이블이 복제에서 자동으로 제외된다는 의미입니다. 가장 광범위한 필터부터 가장 구체적인 필터 순으로 정의하는 것이 좋습니다. 하나 이상의 Include 스테이트먼트로 시작하여 복제할 데이터를 지정한 다음 Exclude 필터를 추가하여 특정 테이블을 선택적으로 제거합니다.
AWS CLI를 사용하여 정의하는 필터에도 동일한 원칙이 적용됩니다. Amazon RDS는 이러한 필터 패턴을 지정된 순서대로 평가하므로 앞서 지정된 패턴을 재정의할 수 있습니다.
RDS for MySQL 예제
다음 예제에서는 RDS for MySQL 예제 제로 ETL 통합에서 데이터 필터링이 작동하는 방식을 보여줍니다.
-
모든 데이터베이스와 모든 테이블 포함:
'include: *.*' -
books데이터베이스 내의 모든 테이블 포함:'include: books.*' -
이름이
mystery인 모든 테이블 제외:'include: *.*, exclude: *.mystery' -
books데이터베이스 내에서 두 개의 특정 테이블 포함:'include: books.stephen_king, include: books.carolyn_keene' -
mystery하위 문자열이 포함된 테이블을 제외한 모든 테이블을books데이터베이스에 포함:'include: books.*, exclude: books./.*mystery.*/' -
mystery로 시작하는 테이블을 제외한 모든 테이블을books데이터베이스에 포함:'include: books.*, exclude: books./mystery.*/' -
mystery로 끝나는 테이블을 제외한 모든 테이블을books데이터베이스에 포함:'include: books.*, exclude: books./.*mystery/' -
books데이터베이스 내에서table_stephen_king을 제외하고 이름이table_로 시작하는 모든 테이블 포함: 예를 들어table_movies또는table_books는 복제되지만table_stephen_king은 복제되지 않습니다.'include: books./table_.*/, exclude: books.table_stephen_king'
RDS for PostgreSQL 예제
다음 예제에서는 RDS for PostgreSQL 제로 ETL 통합에서 데이터 필터링이 작동하는 방식을 보여줍니다.
-
books데이터베이스 내의 모든 테이블 포함:'include: books.*.*' -
books데이터베이스에mystery이름이 지정된 테이블 제외:'include: books.*.*, exclude: books.*.mystery' -
mystery스키마의books데이터베이스 내에 테이블 1개와finance스키마의employee데이터베이스 내에 테이블 1개를 포함합니다.'include: books.mystery.stephen_king, include: employee.finance.benefits' -
king하위 문자열이 포함된 테이블을 제외한 모든 테이블을books데이터베이스 및science_fiction스키마에 포함:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
스키마 이름이
sci로 시작하는 테이블을 제외한 모든 테이블을books데이터베이스에 포함:'include: books.*.*, exclude: books./sci.*/.*' -
king으로 끝나는mystery스키마의 테이블을 제외한 모든 테이블을books데이터베이스에 포함:'include: books.*.*, exclude: books.mystery./.*king/' -
books데이터베이스 내에서table_stephen_king을 제외하고 이름이table_로 시작하는 모든 테이블 포함: 예를 들어fiction스키마의table_movies및mystery스키마의table_books는 복제되지만 두 스키마table_stephen_king은 복제되지 않습니다.'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
RDS for Oracle 예제
다음 예제에서는 RDS for Oracle 제로 ETL 통합에서 데이터 필터링이 작동하는 방식을 보여줍니다.
-
도서 데이터베이스 내의 모든 테이블 포함:
'include: books.*.*' -
books 데이터베이스에 mystery 이름이 지정된 테이블 제외:
'include: books.*.*, exclude: books.*.mystery' -
mystery 스키마의 books 데이터베이스 내에 테이블 1개와 finance 스키마의 employee 데이터베이스 내에 테이블 1개를 포함합니다.
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
books 데이터베이스 내의 mystery 스키마에 모든 테이블을 포함합니다.
'include: books.mystery.*'
대/소문자 구분 고려 사항
Oracle Database와 Amazon Redshift는 객체 이름 대소문자를 다르게 처리하여 데이터 필터 구성과 대상 쿼리 모두에 영향을 줍니다. 다음 사항에 유의하세요.
-
Oracle Database는
CREATE문에 명시적으로 인용되지 않는 한 데이터베이스, 스키마 및 객체 이름을 대문자로 저장합니다. 예를 들어mytable(따옴표 없음)을 생성하면 Oracle 데이터 사전은 테이블 이름을MYTABLE로 저장합니다. 객체 이름을 인용하면 데이터 사전이 사례를 보존합니다. -
제로 ETL 데이터 필터는 대/소문자를 구분하며 Oracle 데이터 사전에 표시된 객체 이름의 정확한 대/소문자와 일치해야 합니다.
-
Amazon Redshift 쿼리는 명시적으로 인용되지 않는 한 기본적으로 소문자 객체 이름으로 설정됩니다. 예를 들어
MYTABLE(따옴표 없음)의 쿼리는mytable을 검색합니다.
Amazon Redshift 필터를 생성하고 데이터를 쿼리할 때의 사례 차이점에 유의하세요.
대문자 통합 생성
이름을 큰따옴표로 지정하지 않고 테이블을 생성하면 Oracle 데이터베이스는 이름을 데이터 사전의 대문자로 저장합니다. 예를 들어 다음 SQL 문을 사용하여 MYTABLE을 생성할 수 있습니다.
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
앞의 문에서 테이블 이름을 인용하지 않았으므로 Oracle 데이터베이스는 객체 이름을 대문자로 MYTABLE로 저장합니다.
이 테이블을 Amazon Redshift에 복제하려면 create-integration 명령의 데이터 필터에 대문자 이름을 지정해야 합니다. 제로 ETL 필터 이름과 Oracle 데이터 사전 이름이 일치해야 합니다.
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
기본적으로 Amazon Redshift는 데이터를 소문자로 저장합니다. Amazon Redshift의 복제된 데이터베이스에서 MYTABLE을 쿼리하려면 Oracle 데이터 사전의 사례와 일치하도록 대문자 이름 MYTABLE을 인용해야 합니다.
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
다음 쿼리는 인용 메커니즘을 사용하지 않습니다. 기본 소문자 이름을 사용하는 mytable라는 Amazon Redshift 테이블을 검색하지만 테이블의 이름은 Oracle 데이터 사전에서 MYTABLE이므로 모두 오류를 반환합니다.
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
다음 쿼리는 인용 메커니즘을 사용하여 혼합 사례 이름을 지정합니다. 쿼리는 이름이 MYTABLE이 아닌 Amazon Redshift 테이블을 검색하기 때문에 모두 오류를 반환합니다.
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
소문자 통합 생성
다음 대체 예제에서는 큰따옴표를 사용하여 Oracle 데이터 사전에서 테이블 이름을 소문자로 저장합니다. 다음과 같이 mytable을 생성합니다.
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle 데이터베이스는 테이블 이름을 mytable(소문자)로 저장합니다. 이 테이블을 Amazon Redshift에 복제하려면 제로 ETL 데이터 필터에 소문자 이름 mytable을 지정해야 합니다.
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Amazon Redshift의 복제된 데이터베이스에서이 테이블을 쿼리할 때 소문자 이름 mytable을 지정할 수 있습니다. 쿼리는 Oracle 데이터 사전의 테이블 이름이 mytable인 테이블을 검색하기 때문에 성공합니다.
SELECT * FROM targetdb1."REINVENT".mytable;
Amazon Redshift는 기본적으로 소문자 객체 이름으로 설정되므로 다음 쿼리도 mytable을 찾는 데 성공합니다.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
다음 쿼리는 객체 이름에 인용 메커니즘을 사용합니다. 이름이 mytable과 다른 Amazon Redshift 테이블을 검색하기 때문에 모두 오류를 반환합니다.
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
혼합 사례 통합을 사용하여 테이블 생성
다음 예제에서는 큰따옴표를 사용하여 Oracle 데이터 사전에서 테이블 이름을 소문자로 저장합니다. 다음과 같이 MyTable을 생성합니다.
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle 데이터베이스는 이 테이블 이름을 MyTable(혼합 대/소문자)로 저장합니다. 이 테이블을 Amazon Redshift에 복제하려면 데이터 필터에 혼합 대소문자 이름을 지정해야 합니다.
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Amazon Redshift의 복제된 데이터베이스에서이 테이블을 쿼리할 때는 객체 이름을 인용하여 이름을 MyTable(혼합 대소문자)로 지정해야 합니다.
SELECT * FROM targetdb1."REINVENT"."MyTable";
Amazon Redshift는 기본적으로 소문자 객체 이름을 사용하므로 다음 쿼리는 소문자 이름 mytable을 검색하기 때문에 객체를 찾지 못합니다.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
참고
RDS for Oracle 통합에서는 데이터베이스 이름, 스키마 또는 테이블 이름에 대한 필터 값에 정규식을 사용할 수 없습니다.
통합에 데이터 필터 추가
AWS Management Console, AWS CLI 또는 Amazon RDS API를 사용하여 데이터 필터링을 구성할 수 있습니다.
중요
통합을 만든 후 필터를 추가하면 Amazon RDS가 필터가 항상 존재했던 것처럼 이를 처리합니다. 대상 데이터 웨어하우스에 있는 데이터 중 새로운 필터링 기준과 일치하지 않는 데이터를 제거하고 모든 영향받는 테이블을 재동기화합니다.
제로 ETL 통합에 데이터 필터를 추가하는 방법
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. -
탐색 창에서 제로 ETL 통합을 선택합니다. 데이터 필터를 추가할 통합을 선택한 다음 수정을 선택합니다.
-
소스에서 하나 이상의
Include및Exclude문을 추가합니다.다음 이미지는 MySQL 통합의 데이터 필터 예시를 보여줍니다.
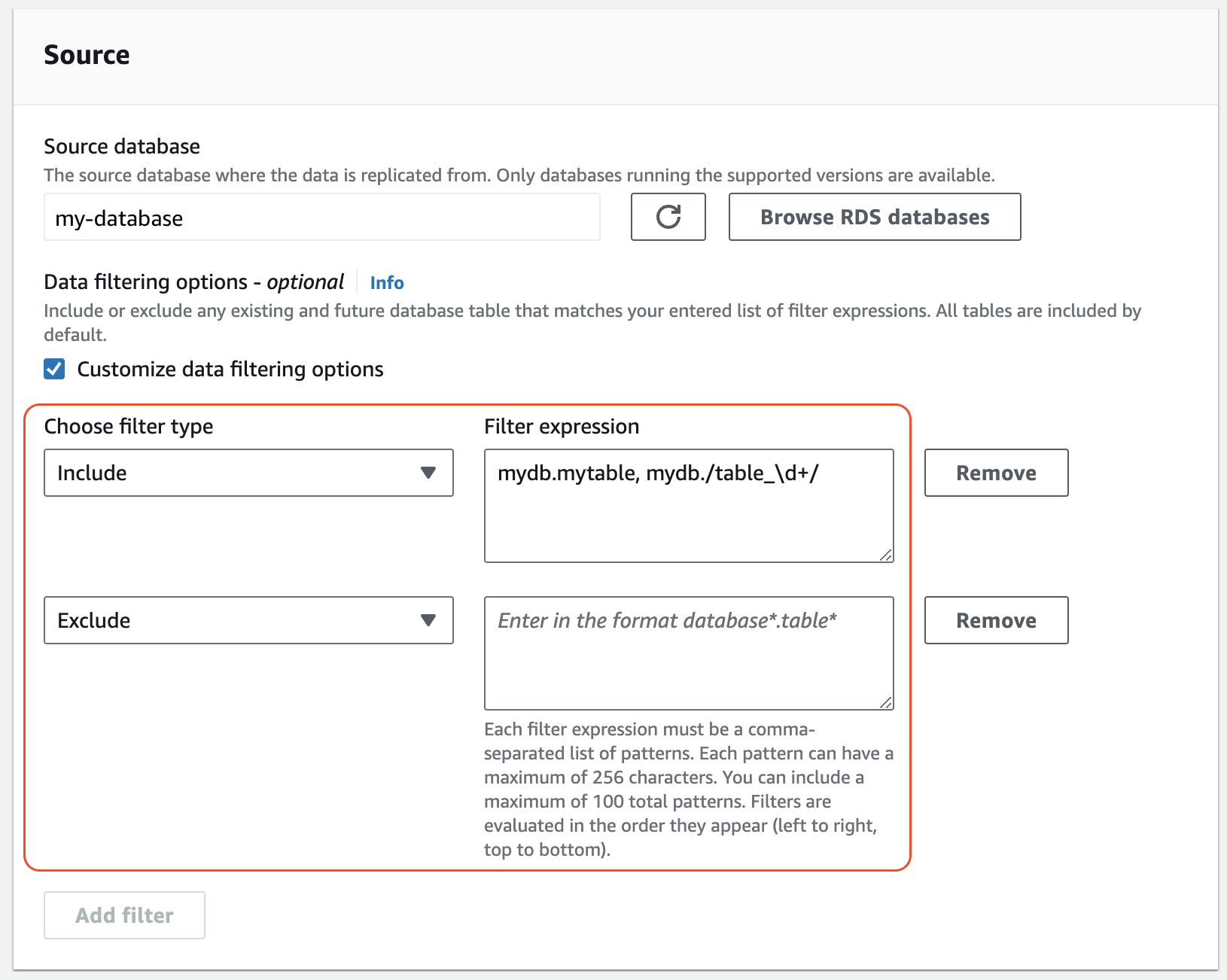
-
변경 사항에 만족하면 계속 및 변경 사항 저장을 선택합니다.
AWS CLI를 사용하여 제로 ETL 통합에 데이터 필터를 추가하려면 modify-integrationInclude 및 Exclude Maxwell 필터 목록을 사용하여 --data-filter 파라미터를 지정하세요.
예
다음 예시에서는 my-integration에 필터 패턴을 추가합니다.
대상 LinuxmacOS, 또는Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Windows의 경우:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
RDS API를 사용하여 제로 ETL 통합을 수정하려면 ModifyIntegration을 호출하세요. 통합 식별자를 지정하고 쉼표로 구분된 필터 패턴 목록을 제공하세요.
통합에서 데이터 필터 제거
통합에서 데이터 필터를 제거하면 Amazon RDS는 제거된 필터가 존재하지 않았던 것처럼 나머지 필터를 재평가합니다. 그런 다음, 이전에 제외되었지만 이제 기준을 충족하는 데이터를 대상 데이터 웨어하우스에 복제합니다. 그러면 모든 영향받는 테이블의 재동기화가 트리거됩니다.
