읽기 전용 복제본 모니터링
읽기 전용 복제본의 상태는 몇 가지 방법으로 모니터링할 수 있습니다. Amazon RDS 콘솔의 읽기 전용 복제본 세부 정보에 있는 연결 및 보안(Connectivity & security) 탭의 복제(Replication) 섹션에 읽기 전용 복제본의 상태가 표시됩니다. 읽기 전용 복제본의 세부 정보를 보려면 Amazon RDS 콘솔의 DB 인스턴스 목록에서 읽기 전용 복제본의 이름을 선택합니다.
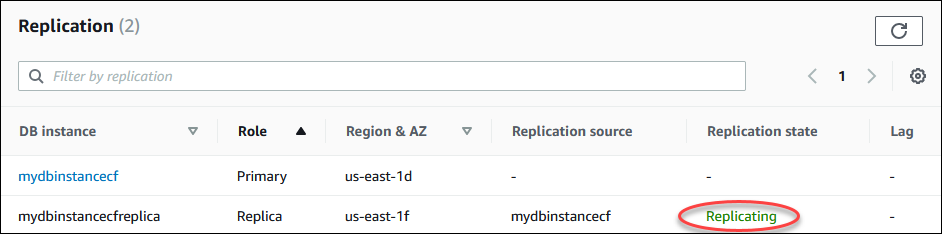
AWS CLI describe-db-instances 명령 또는 Amazon RDS API DescribeDBInstances 작업을 사용하여 읽기 전용 복제본의 상태도 볼 수 있습니다.
읽기 전용 복제본의 상태는 다음 중 한 가지가 될 수 있습니다.
-
복제 중 – 읽기 전용 복제본이 성공적으로 복제되고 있습니다.
-
복제 성능 저하됨(SQL Server 및 PostgreSQL만 해당) – 복제본이 기본 인스턴스에서 데이터를 수신하지만, 하나 이상의 데이터베이스가 업데이트를 가져오지 못할 수 있습니다. 예를 들어, 복제본이 새로 생성된 데이터베이스를 설정하는 동안 이러한 문제가 발생할 수 있습니다. 블루/그린 배포의 블루 환경에서 지원되지 않는 DDL이나 대규모 객체 변경이 이루어진 경우에도 발생할 수 있습니다.
성능이 저하된 상태에서 오류가 발생하지 않는 한 상태가
replication degraded에서error로 전환되지 않습니다. -
오류 – 복제 중에 오류가 발생했습니다. Amazon RDS 콘솔의 [Replication Error] 필드나 이벤트 로그를 검사하여 정확한 오류 원인을 찾아내야 합니다. 복제 오류의 문제 해결에 대한 자세한 내용은 MySQL 읽기 전용 복제본의 문제 해결 단원을 참조하십시오.
-
종료됨(MariaDB, MySQL 또는 PostgreSQL만 해당) – 복제가 종료됩니다. 수동으로 또는 복제 오류로 인해 연속하여 30일 이상 복제가 중지된 경우 이 오류가 발생합니다. 이 경우 Amazon RDS는 기본 DB 인스턴스와 모든 읽기 전용 복제본 간의 복제를 종료합니다. Amazon RDS는 소스 DB 인스턴스에 대한 스토리지 요건 강화 및 장애 조치 장기화를 방지하기 위해 이 작업을 수행합니다.
복제가 중단되면 대용량의 오류 메시지를 로그에 써야 하기 때문에 로그 크기와 수가 증가하면서 스토리지에 영향을 끼칠 수 있습니다. 또한 Amazon RDS가 복구 단계에서 다수의 로그를 유지 및 처리하는 데 필요한 시간 때문에 장애 복구에 영향을 끼칠 수도 있습니다.
-
종료됨(Oracle만 해당) - 복제가 종료되었습니다. 읽기 전용 복제본에 남아 있는 스토리지가 충분하지 않아 복제가 8시간 이상 중지된 경우 이 오류가 발생합니다. 이 경우 Amazon RDS는 기본 DB 인스턴스와 영향을 받는 읽기 전용 복제본 간의 복제를 종료합니다. 이 상태는 터미널 상태이며, 읽기 전용 복제본을 다시 만들어야 합니다.
-
중지됨(MariaDB 또는 MySQL만 해당) – 고객이 시작한 요청으로 복제가 중지되었습니다.
-
replication stop point set(복제 중지 지점 설정됨)(MySQL만 해당) – 고객이 시작한 중지 지점이 mysql.rds_start_replication_until 저장 프로시저를 사용하여 설정되었으며 복제가 진행 중입니다.
-
replication stop point reached(복제 중지 지점 도달됨)(MySQL만 해당) – 고객이 시작한 중지 지점이 mysql.rds_start_replication_until 저장 프로시저를 사용하여 설정되었으며 중지 지점에 도달했기 때문에 복제가 중지됩니다.
DB 인스턴스가 복제되는 위치를 확인할 수 있으며, DB 인스턴스가 복제되는 경우 복제 상태를 확인할 수 있습니다. RDS 콘솔의 [데이터베이스(Databases)] 페이지에서 [역할(Role)] 열에 [기본(Primary)]이 표시됩니다. DB 인스턴스 이름을 선택합니다. 세부 정보 페이지의 [연결 및 보안(Connectivity & security)] 탭에서 복제 상태는 [복제(Replication)] 아래에 있습니다.
복제 모니터링 지연 시간
Amazon CloudWatch에서 Amazon RDS ReplicaLag 지표를 보고 복제 지연을 모니터링할 수 있습니다.
Db2의 경우 ReplicaLag 지표는 지연된 데이터베이스의 최대 지연 시간(초)입니다. 예를 들어, 두 개의 데이터베이스가 각각 5초와 10초 지연되는 경우 ReplicaLag는 10초입니다. 사용 가능한 고가용성 재해 복구(HADR) 상태가 없는 데이터베이스는 계산에 포함되지 않습니다.
MySQL 및 MariaDB의 경우 ReplicaLag 지표가 Seconds_Behind_Master 명령의 SHOW REPLICA STATUS 필드 값을 보고합니다. 이렇게 MySQL 및 MariaDB에서 복제 지연이 발생하는 공통 원인은 다음과 같습니다.
-
네트워크 중단.
-
읽기 전용 복제본의 인덱스가 있는 테이블에 쓰기 작업 중일 때. 읽기 전용 복제본에서
read_only파라미터가 0으로 설정되어 있지 않으면 복제가 중단될 수 있습니다. -
MyISAM과 같은 비트랜잭션 스토리지 엔진 사용. 복제는 MySQL용 InnoDB 스토리지 엔진 및 MariaDB용 XtraDB 스토리지 엔진에 대해서만 지원됩니다.
참고
이전 버전의 MariaDB에는 SHOW SLAVE STATUS 대신 SHOW REPLICA STATUS가 사용되었습니다. 10.5 이하의 MariaDB 버전을 사용하는 경우 SHOW SLAVE STATUS를 사용합니다.
ReplicaLag 지표가 0에 도달하면 복제본이 기본 DB 인스턴스를 따라잡은 것입니다. ReplicaLag 지표가 -1을 반환하는 경우 복제가 현재 활성 상태가 아닙니다. ReplicaLag = -1은 Seconds_Behind_Master = NULL과 동등합니다.
Oracle의 경우, ReplicaLag 지표는 Apply
Lag 값과 현재 시간과 적용 지연의 DATUM_TIME 값 차이를 합한 값입니다. DATUM_TIME 값은 읽기 전용 복제본이 마지막으로 원본 DB 인스턴스에서 데이터를 수신한 시간입니다. 자세한 내용은 Oracle 설명서에서 V$DATAGUARD_STATS
SQL Server의 경우 ReplicaLag 지표는 지연된 데이터베이스의 최대 지연 시간(초)입니다. 예를 들어, 각각 5초와 10초가 지연되는 두 개의 데이터베이스가 각각 있는 경우 ReplicaLag는 10초입니다. ReplicaLag 지표는 다음 쿼리의 값을 반환합니다.
SELECT MAX(secondary_lag_seconds) max_lag FROM sys.dm_hadr_database_replica_states;
자세한 내용은 Microsoft 설명서의 secondary_lag_seconds
ReplicaLag는 복제본 설정 중 또는 읽기 전용 복제본이 -1 상태에 있는 경우와 같이 RDS가 지연 시간을 확인할 수 없는 경우 error을 반환합니다.
참고
새 데이터베이스는 읽기 전용 복제본에서 액세스할 수 있을 때까지 지연 시간 계산에 포함되지 않습니다.
PostgreSQL의 경우 ReplicaLag 지표는 다음 쿼리의 값을 반환합니다.
SELECT extract(epoch from now() - pg_last_xact_replay_timestamp()) AS reader_lag
PostgreSQL 버전 9.5.2 이상은 물리적인 복제 슬롯을 사용하여 원본 인스턴스에서 Write Ahead Log(WAL) 보존을 관리합니다. Amazon RDS가 리전 간 읽기 전용 복제본 인스턴스마다 물리적 복제 슬롯을 생성하여 인스턴스와 연동시킵니다. 2개의 Amazon CloudWatch 지표인 Oldest Replication Slot Lag와 Transaction
Logs Disk Usage는 수신되는 WAL 데이터와 관련하여 가장 지체된 복제본이 얼마나 오래되었는지, 그리고 현재 WAL 데이터에 얼마나 많은 스토리지가 사용되고 있는지 나타냅니다. Transaction
Logs Disk Usage 값은 리전 간 읽기 전용 복제본이 많이 지체될수록 크게 증가합니다.
CloudWatch를 통한 DB 인스턴스 모니터링에 대한 자세한 내용은 Amazon CloudWatch로 Amazon RDS 지표 모니터링 단원을 참조하세요.
