DB 클러스터 만들기
다음 프로시저에 따라 Aurora PostgreSQL Limitless Database를 사용하는 Aurora PostgreSQL DB 클러스터를 만듭니다.
AWS Management Console 또는 AWS CLI를 사용하여 Aurora PostgreSQL Limitless Database를 사용하는 DB 클러스터를 만들 수 있습니다. 기본 DB 클러스터와 DB 샤드 그룹을 만듭니다.
AWS Management Console을 사용하여 기본 DB 클러스터를 만들 때 DB 샤드 그룹도 동일한 프로시저로 만들어집니다.
콘솔을 사용하여 DB 클러스터를 만드는 방법
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. -
데이터베이스 생성을 선택합니다.
데이터베이스 생성 페이지가 표시됩니다.
-
엔진 유형에서 Aurora(PostgreSQL 호환)를 선택합니다.
-
버전에서 다음 중 하나를 선택합니다.
-
Limitless Database가 있는 Aurora PostgreSQL(PostgreSQL 16.4와 호환)
-
Limitless Database가 있는 Aurora PostgreSQL(PostgreSQL 16.6과 호환)
-
-
Aurora PostgreSQL Limitless Database의 경우:
-
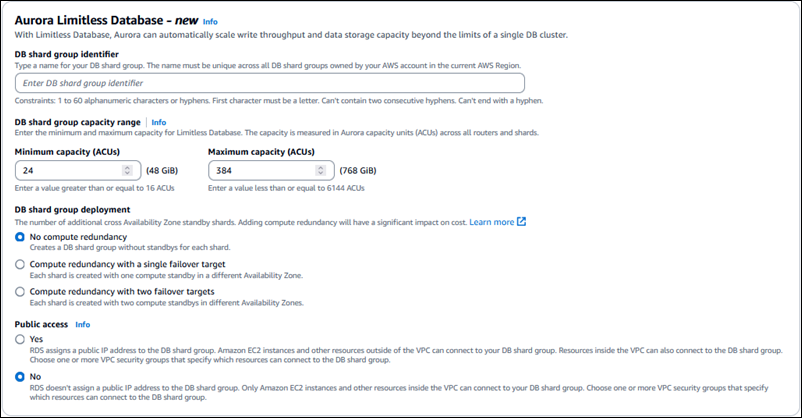
DB 샤드 그룹 식별자를 입력합니다.
중요
DB 샤드 그룹을 만든 후에는 DB 클러스터 식별자 또는 DB 샤드 그룹 식별자를 변경할 수 없습니다.
-
DB 샤드 그룹 용량 범위의 경우:
-
최소 용량(ACU)을 입력합니다. 값을 최소 16ACU로 지정합니다.
개발 환경의 경우 기본값은 16ACU입니다. 프로덕션 환경의 경우 기본값은 24ACU입니다.
-
최대 용량(ACU)을 입력합니다. 최소 16ACU 또는 최대 6,144ACU의 값을 사용합니다.
개발 환경의 경우 기본값은 64ACU입니다. 프로덕션 환경의 경우 기본값은 384ACU입니다.
자세한 내용은 DB 샤드 그룹 최대 용량과 만들어진 라우터 및 샤드 수 연결 섹션을 참조하세요.
-
-
DB 샤드 그룹 배포의 경우 DB 샤드 그룹에 대한 대기를 만들지 선택합니다.
-
컴퓨팅 중복 없음 - 각 샤드에 대해 대기 없이 DB 샤드 그룹을 만듭니다. 이것이 기본값입니다.
-
단일 장애 조치 타겟을 사용한 컴퓨팅 중복 - 다른 가용 영역(AZ)에 하나의 컴퓨팅 대기가 있는 DB 샤드 그룹을 만듭니다.
-
2개의 장애 조치 타겟을 사용한 컴퓨팅 중복 - 2개의 서로 다른 AZ에서 2개의 컴퓨팅 대기가 있는 DB 샤드 그룹을 만듭니다.
참고
컴퓨팅 중복을 0이 아닌 값으로 설정하면 DB 인스턴스의 총 샤드 수가 두 배 내지 세 배가 됩니다. 이러한 추가 DB 인스턴스는 컴퓨팅 대기 인스턴스로, 라이터 인스턴스와 동일한 용량으로 스케일 업 및 스케일 다운됩니다. 대기에 대해 용량 범위를 별도로 설정하지 않습니다. 그에 따라 ACU 사용량 및 청구 금액도 두 배, 세 배로 늘어납니다. 컴퓨팅 중복으로 인해 발생한 정확한 ACU 사용량을 알아보려면 DBShardGroup 지표의
DBShardGroupComputeRedundancyCapacity지표를 참조하세요. -
-
DB 샤드 그룹에 공개적으로 액세스할 수 있도록 할지 선택합니다.
참고
DB 샤드 그룹을 만든 후에는 이 설정을 수정할 수 없습니다.
-
-
연결의 경우:
-
(선택 사항) EC2 컴퓨팅 리소스에 연결을 선택한 다음 기존 EC2 인스턴스를 선택하거나 새 인스턴스를 만듭니다.
참고
EC2 인스턴스에 연결하는 경우 DB 샤드 그룹에 공개적으로 액세스할 수 있도록 설정할 수 없습니다.
-
네트워크 유형에서 IPv4 또는 이중 스택 모드를 선택합니다.
-
가상 프라이빗 클라우드(VPC) 및 DB 서브넷 그룹을 선택하거나 기본 설정을 사용합니다.
참고
미국 동부(버지니아 북부) 리전에서 Limitless Database DB 클러스터를 만드는 경우 DB 서브넷 그룹에
us-east-1e가용 영역(AZ)을 포함하지 마세요. 리소스 제한으로 인해us-east-1eAZ에서는 Aurora serverless가 지원되지 않고, 따라서 Limitless Database도 지원되지 않습니다. -
VPC 보안 그룹(방화벽)을 선택하거나 기본 설정을 사용합니다.
-
-
데이터베이스 인증에서 암호 인증 또는 암호 및 IAM 데이터베이스 인증을 선택합니다.
-
모니터링에서 성능 개선 도우미 켜기 및 향상된 모니터링 활성화 확인란이 선택되어 있는지 확인합니다.
성능 개선 도우미에서 보존 기간을 최소 1개월로 선택합니다.
-
페이지에서 마지막 추가 구성을 확장합니다.
-
로그 내보내기의 경우 PostgreSQL 로그 확인란이 선택되어 있는지 확인합니다.
-
필요에 따라 다른 설정을 지정합니다. 자세한 내용은 Aurora DB 클러스터 설정 섹션을 참조하세요.
-
데이터베이스 생성을 선택합니다.
기본 DB 클러스터 및 DB 샤드 그룹이 만들어지면 데이터베이스 페이지에 표시됩니다.

AWS CLI를 사용하여 Aurora PostgreSQL Limitless Database를 사용하는 DB 클러스터를 만들 때 다음 작업을 수행합니다.
기본 DB 클러스터 만들기
DB 클러스터를 만들려면 다음 파라미터가 필요합니다.
-
--db-cluster-identifier- DB 클러스터의 이름입니다. -
--engine– DB 클러스터는aurora-postgresqlDB 엔진을 사용해야 합니다. -
--engine-version– DB 클러스터는 다음과 같은 DB 엔진 버전 중 하나를 사용해야 합니다.-
16.4-limitless -
16.6-limitless
-
-
--storage-type– DB 클러스터는aurora-iopt1DB 클러스터 스토리지 구성을 사용해야 합니다. -
--cluster-scalability-type- Aurora DB 클러스터의 확장성 모드를 지정합니다.limitless로 설정하면 클러스터가 Aurora PostgreSQL Limitless Database로 작동합니다.standard(기본값)로 설정하면 클러스터가 일반 DB 인스턴스 만들기를 사용합니다.참고
DB 클러스터를 만든 후에는 이 설정을 수정할 수 없습니다.
-
--master-username- DB 클러스터의 마스터 사용자 이름입니다. -
--master-user-password- 마스터 사용자의 암호입니다. -
--enable-performance-insights– 성능 개선 도우미를 활성화해야 합니다. -
--performance-insights-retention-period– 성능 개선 도우미 보존 기간은 최소 31일이어야 합니다. -
--monitoring-interval- DB 클러스터에 대한 확장 모니터링 지표를 수집하는 시점 사이의 간격(초)입니다. 이 값은0일 수 없습니다. -
--monitoring-role-arn- RDS에서 Amazon CloudWatch Logs로 확장 모니터링 지표를 전송할 수 있도록 하는 IAM 역할의 Amazon 리소스 이름(ARN)입니다. -
--enable-cloudwatch-logs-exports-postgresql로그를 CloudWatch Logs로 내보내야 합니다.
다음 파라미터는 선택적입니다.
-
--db-subnet-group-name- DB 클러스터와 연결할 DB 서브넷 그룹입니다. 이것은 DB 클러스터와 연결된 VPC도 결정합니다.참고
미국 동부(버지니아 북부) 리전에서 Limitless Database DB 클러스터를 만드는 경우 DB 서브넷 그룹에
us-east-1e가용 영역(AZ)을 포함하지 마세요. 리소스 제한으로 인해us-east-1eAZ에서는 Aurora serverless가 지원되지 않고, 따라서 Limitless Database도 지원되지 않습니다. -
--vpc-security-group-ids- DB 클러스터와 연결할 VPC 보안 그룹의 목록입니다. -
--performance-insights-kms-key-id- 성능 개선 도우미 데이터의 암호화를 위한 AWS KMS key 식별자입니다. KMS 키를 지정하지 않으면 AWS 계정의 기본 키가 사용됩니다. -
--region- DB 클러스터를 만드는 AWS 리전입니다. Aurora PostgreSQL Limitless Database를 지원해야 합니다.
기본 VPC 및 VPC 보안 그룹을 사용하려면 --db-subnet-group-name 및 --vpc-security-group-ids 옵션을 생략합니다.
기본 DB 클러스터를 만드는 방법
-
aws rds create-db-cluster \ --db-cluster-identifiermy-limitless-cluster\ --engine aurora-postgresql \ --engine-version 16.6-limitless \ --storage-type aurora-iopt1 \ --cluster-scalability-type limitless \ --master-usernamemyuser\ --master-user-passwordmypassword\ --db-subnet-group-namemysubnetgroup\ --vpc-security-group-idssg-c7e5b0d2\ --enable-performance-insights \ --performance-insights-retention-period31\ --monitoring-interval5\ --monitoring-role-arn arn:aws:iam::123456789012:role/EMrole\ --enable-cloudwatch-logs-exports postgresql
자세한 내용은 create-db-cluster
DB 샤드 그룹 만들기
다음으로, 방금 만든 DB 클러스터에서 DB 샤드 그룹을 만듭니다. 다음 파라미터는 필수 파라미터입니다.
-
--db-shard-group-identifier- DB 샤드 그룹의 이름입니다.DB 샤드 그룹 식별자에는 다음과 같은 제약이 있습니다.
-
DB 샤드 그룹을 만드는 AWS 계정과 AWS 리전에서 고유해야 합니다.
-
1~63자의 문자, 숫자 또는 하이픈을 포함해야 합니다.
-
첫 번째 자리는 문자여야 합니다.
-
하이픈으로 끝나거나 하이픈이 2개 연속으로 이어져서는 안 됩니다.
-
중요
DB 샤드 그룹을 만든 후에는 DB 클러스터 식별자 또는 DB 샤드 그룹 식별자를 변경할 수 없습니다.
-
-
--db-cluster-identifier- DB 샤드 그룹을 만드는 DB 클러스터의 이름입니다. -
--max-acu- DB 샤드 그룹의 최대 용량입니다. ACU는 16~6,144개여야 합니다. 6,144ACU보다 높은 용량 한도는 AWS에 문의하세요.초기 라우터 및 샤드 수는 DB 샤드 그룹을 만들 때 설정한 최대 용량에 따라 결정됩니다. 최대 용량이 높을수록 DB 샤드 그룹에서 만들어지는 라우터 및 샤드가 많아집니다. 자세한 내용은 DB 샤드 그룹 최대 용량과 만들어진 라우터 및 샤드 수 연결 섹션을 참조하세요.
다음 파라미터는 선택적입니다.
-
--compute-redundancy- DB 샤드 그룹에 대한 대기를 만들지를 나타냅니다. 이 파라미터의 값은 다음과 같을 수 있습니다.-
0- 각 샤드에 대해 대기 없이 DB 샤드 그룹을 만듭니다. 이것이 기본값입니다. -
1- 다른 가용 영역(AZ)에 하나의 컴퓨팅 대기가 있는 DB 샤드 그룹을 만듭니다. -
2- 서로 다른 2개의 AZ에 2개의 컴퓨팅 대기가 있는 DB 샤드 그룹을 만듭니다.
참고
컴퓨팅 중복을 0이 아닌 값으로 설정하면 총 샤드 수가 두 배 또는 세 배가 됩니다. 이로 인해 추가 비용이 발생합니다.
컴퓨팅 대기의 노드는 라이터와 동일한 용량으로 스케일 업 및 다운됩니다. 대기에 대해 용량 범위를 별도로 설정하지 않습니다.
-
-
--min-acu– DB 샤드 그룹의 최소 용량입니다. ACU는 기본값인 16개 이상이어야 합니다. -
--publicly-accessible|--no-publicly-accessible- 공개적으로 액세스할 수 있는 IP 주소를 DB 샤드 그룹에 할당할지를 나타냅니다. DB 샤드 그룹에 대한 액세스는 클러스터에서 사용하는 보안 그룹에 의해 제어됩니다.기본값은
--no-publicly-accessible입니다.참고
DB 샤드 그룹을 만든 후에는 이 설정을 수정할 수 없습니다.
DB 샤드 그룹을 만드는 방법
-
aws rds create-db-shard-group \ --db-shard-group-identifiermy-db-shard-group\ --db-cluster-identifier my-limitless-cluster \ --max-acu1000
