예제: Application Signals를 사용하여 운영 상태 문제 해결
다음 시나리오는 Application Signals를 사용하여 서비스를 모니터링하고 서비스 품질 문제를 식별하는 방법에 대한 예제를 제공합니다. 드릴다운하여 잠재적 근본 원인을 파악하고 문제 해결을 위한 조치를 취합니다. 이 예제는 DynamoDB와 같은 AWS 서비스를 직접적으로 호출하는 여러 마이크로서비스로 구성된 반려동물 클리닉 애플리케이션에 초점을 맞추고 있습니다.
Jane은 반려동물 클리닉 애플리케이션의 운영 상태를 감독하는 DevOps 팀의 일원입니다. Jane의 팀은 애플리케이션의 가용성과 응답성을 보장하기 위해 노력하고 있습니다. 이들은 서비스 수준 목표(SLO)를 기준으로 이러한 비즈니스 약속과 비교하여 애플리케이션 성능을 측정합니다. Jane은 여러 비정상 서비스 수준 지표(SLI)에 대한 알림을 받습니다. CloudWatch 콘솔을 열고 서비스 페이지로 이동하면 비정상 상태인 여러 서비스가 표시됩니다.
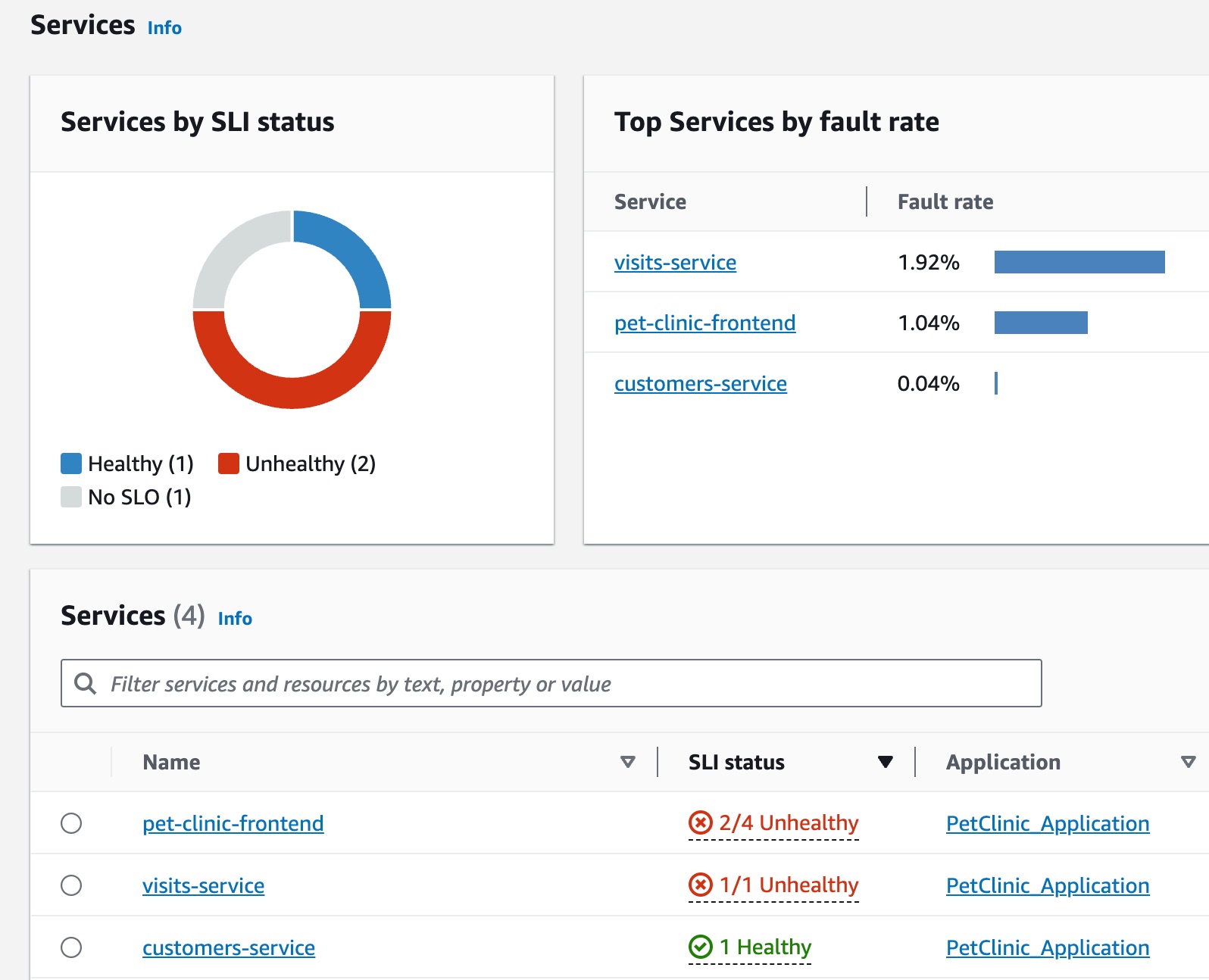
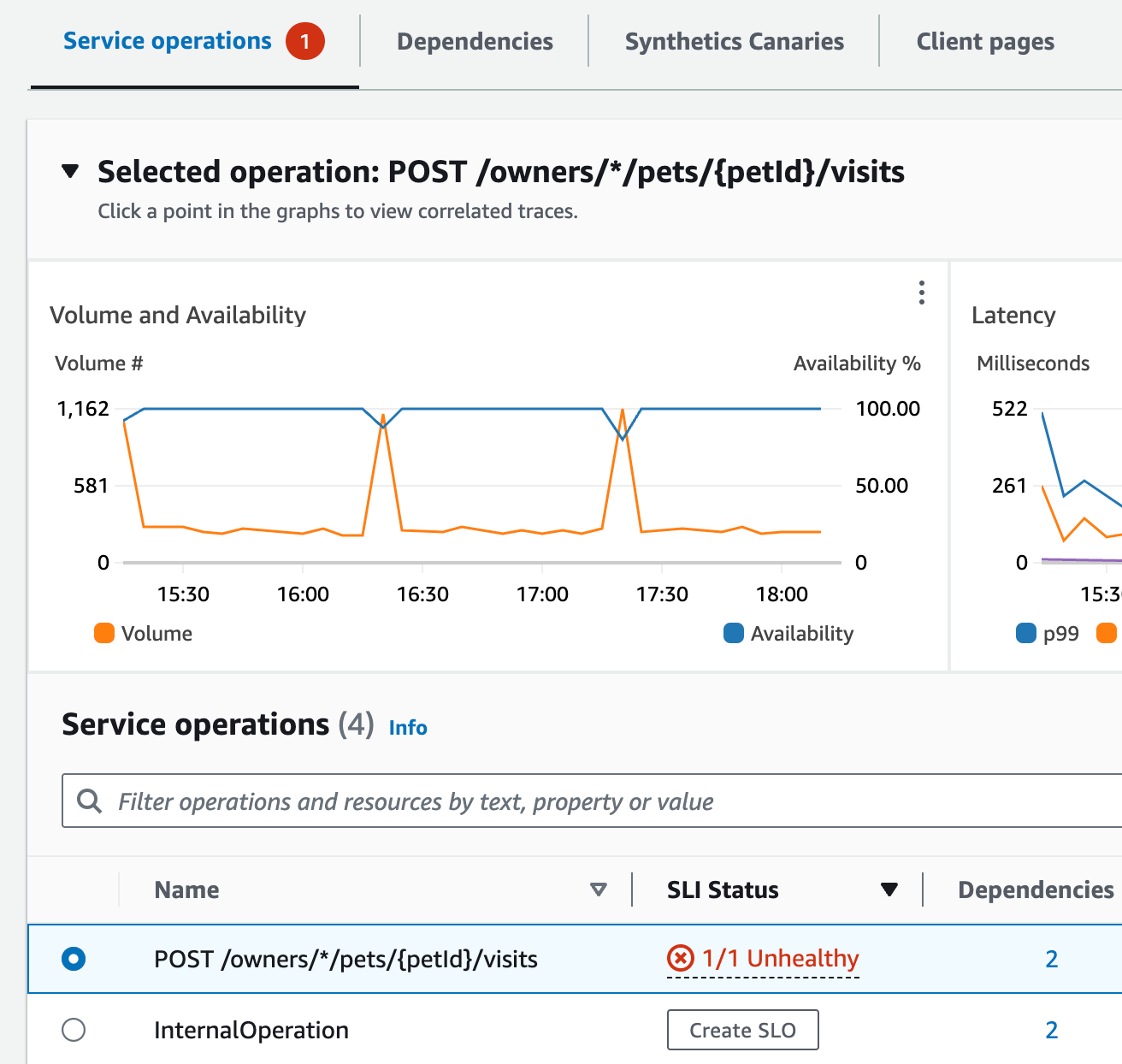
페이지 상단에서 Jane은 visits-service가 장애 발생률이 가장 높음을 확인합니다. 그래프에서 링크를 선택하면 해당 서비스의 서비스 세부 정보 페이지가 열립니다. 그녀는 서비스 작업 테이블에 비정상 작업이 있음을 확인합니다. 이 작업을 선택하면 볼륨 및 가용성 그래프에서 주기적으로 호출 볼륨이 급증하는 것을 확인할 수 있는데, 이는 가용성 저하와 상관관계가 있는 것으로 보입니다.
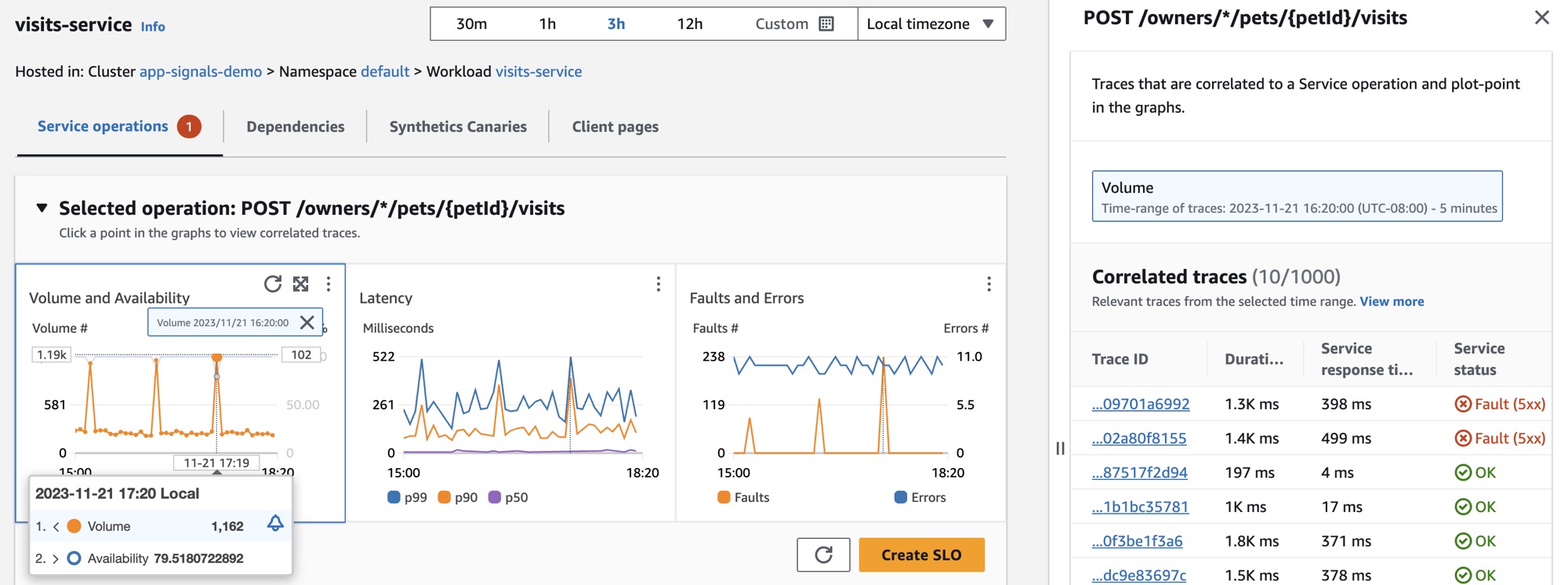
Jane은 서비스 가용성 저하를 자세히 살펴보기 위해 그래프에서 가용성 데이터 포인트 중 하나를 선택합니다. 선택한 데이터 포인트와 상관관계가 있는 X-Ray 트레이스가 표시된 드로어가 열립니다. 그녀는 장애를 포함하는 트레이스가 여러 개 있음을 확인합니다.
Jane은 장애 상태의 상관관계가 있는 트레이스 중 하나를 선택합니다. 그러면 선택한 트레이스에 대한 X-Ray 트레이스 세부 정보 페이지가 열립니다. Jane은 세그먼트 타임라인 섹션으로 스크롤하여 DynamoDB 테이블을 직접적으로 호출하면 오류가 반환되는 것을 확인할 때까지 호출 경로를 따라갑니다. DynamoDB 세그먼트를 선택하고 오른쪽 드로어의 예외 탭으로 이동합니다.
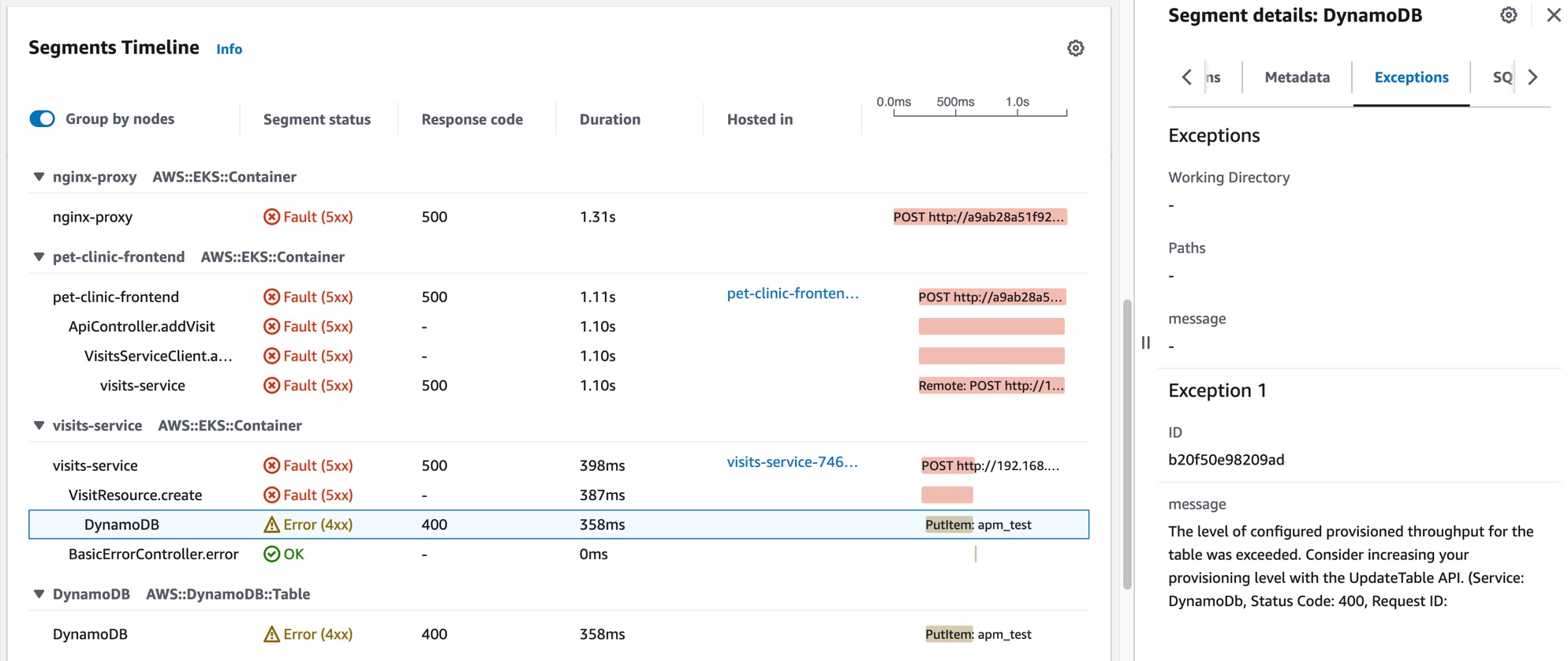
Jane은 DynamoDB 리소스가 잘못 구성되어 고객 요청이 급증하는 동안 오류가 발생하는 것을 확인했습니다. DynamoDB 테이블의 프로비저닝된 처리량 수준이 주기적으로 초과되어 서비스 가용성 문제와 비정상 SLI가 발생합니다. 이 정보를 바탕으로 그녀의 팀은 더 높은 수준의 프로비저닝 처리량을 구성하고 애플리케이션의 고가용성을 보장할 수 있습니다.
