# ストリーミングデータソリューション: 例
## シナリオ 1: 場所に基づくインターネットの提供
*InternetProvider* は、世界中のユーザーにさまざまな帯域幅オプションを備えたインターネットサービスを提供しています。ユーザーがインターネットにサインアップすると、*InternetProvider* は、ユーザーの地理的位置に基づいて異なる帯域幅オプションをユーザーに提供します。これらの要件を考慮して、*InternetProvider* は Amazon Kinesis Data Streams を実装し、ユーザーの詳細と場所を処理しました。ユーザーの詳細と場所は、さまざまな帯域幅オプションでエンリッチされてから、アプリケーションにパブリッシュして戻されます。[AWS Lambda](https://aws.amazon.com/lambda/) は、このリアルタイムエンリッチメントを可能にします。
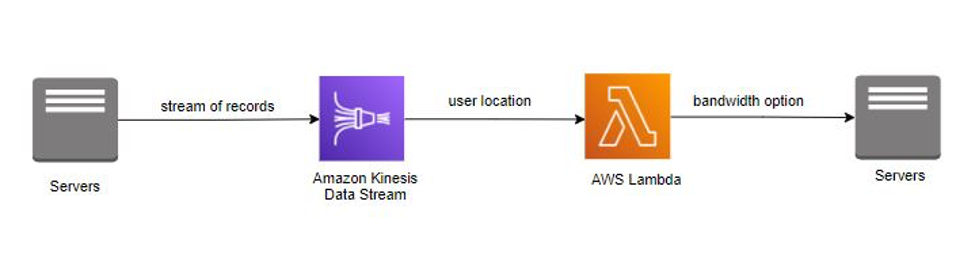
*AWS Lambda を使用してデータのストリーミングを処理する*
### Amazon Kinesis Data Streams
[Amazon Kinesis Data Streams](https://aws.amazon.com/kinesis/data-streams/) を使用すると、一般的なストリーミング処理フレームワークを使用してカスタムのリアルタイムアプリケーションを構築し、ストリーミングデータをさまざまなデータストアにロードできます。Kinesis のストリーミングは、ウェブサイトのクリックストリーム、IoT センサー、ソーシャルメディアフィード、アプリケーションログなどのソースから配信された数十万ものデータプロデューサーからのイベントを、継続的に受信するように設定できます。ミリ秒以内に、アプリケーションでデータを読み取りおよび処理できるようになります。
Kinesis Data Streams でソリューションを実装する場合、Kinesis Data Streams アプリケーションと呼ばれるカスタムデータ処理アプリケーションを作成します。一般的な Kinesis Data Streams アプリケーションは、Kinesis ストリーミングからデータをデータレコードとして読み取ります。
Kinesis Data Streams に格納されるデータは、高い可用性と伸縮自在性が確保され、ミリ秒で利用可能になります。クリックストリーム、アプリケーションログ、ソーシャルメディアなど、さまざまなタイプのデータを、何十万ものソースから Kinesis のストリーミングに継続して追加できます。ほんの数秒後には、[Kinesis アプリケーション](https://www.amazonaws.cn/en/kinesis/data-streams/faqs/#kinesisapp)で、ストリーミングからデータを読み取って処理できます。
Amazon Kinesis Data Streams はフルマネージド型のストリーミングデータサービスです。データスループットのレベルでデータをストリーミングするために必要なインフラストラクチャ、ストレージ、ネットワーク、設定を管理します。
#### Amazon Kinesis Data Streams へのデータの送信
Kinesis Data Streams にデータを送信する方法はいくつかあり、ソリューションを柔軟に設計できます。
+ 一般的な複数の言語でサポートされている [ AWS SDK](https://aws.amazon.com/tools/) の 1 つを使用してコードを記述できます。
+ Kinesis Data Streams にデータを送信するためのツールである [Amazon Kinesis Agent](https://docs.aws.amazon.com/streams/latest/dev/writing-with-agents.html) を使用できます。
[Amazon Kinesis Producer Library](https://docs.aws.amazon.com/streams/latest/dev/developing-producers-with-kpl.html) (KPL) は、プロデューサーアプリケーションの開発を簡素化し、デベロッパーが 1 つ以上の Kinesis のデータストリームへの高い書き込みスループットを実現できるようにします。
KPL は使いやすく、高度な構成が可能なライブラリで、お客様のホストにインストールできます。これは、プロデューサーアプリケーションのコードと Kinesis Streams API アクション間の仲介として機能します。KPL およびコード例を使用してイベントを同期および非同期に生成する機能の詳細については、「[KPL を使用した Kinesis Data Streams への書き込み](https://docs.aws.amazon.com/streams/latest/dev/kinesis-kpl-writing.html)」を参照してください。
Kinesis Data Streams API には、ストリームにデータを追加する 2 つの異なるオペレーション (`PutRecords` と `PutRecord`) があります。`PutRecords` オペレーションは HTTP リクエストごとに複数のレコードをストリーミングに送信し、`PutRecord` は HTTP リクエストごとに 1 つのレコードを送信します。ほとんどのアプリケーションで高いスループットを達成するには、`PutRecords` を使用します。
これらの API の詳細については、「[ストリーミングへのデータの追加](https://docs.aws.amazon.com/streams/latest/dev/developing-producers-with-sdk.html#kinesis-using-sdk-java-add-data-to-stream)」を参照してください。各 API オペレーションの詳細については、「[Amazon Kinesis Data Streams API Reference](https://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html)」を参照してください。
#### Amazon Kinesis Data Streams でのデータ処理
Kinesis のストリーミングからデータを読み取って処理するには、コンシューマーアプリケーションを作成する必要があります。Kinesis Data Streams のコンシューマーを作成するには、さまざまな方法があります。KCL を使用したストリーミングデータの分析に [Amazon Kinesis Data Analytics](https://aws.amazon.com/kinesis/data-analytics/) を使用する、[AWS Lambda](https://aws.amazon.com/lambda/) を使用する、[AWS Glue で ETL ジョブをストリーミングする](https://docs.aws.amazon.com/glue/latest/dg/add-job-streaming.html)、Kinesis Data Streams API を直接使用する、などのアプローチがあります。
Kinesis Data Streams のコンシューマーアプリケーションは、Kinesis Data Streams からのデータの消費および処理を助ける KCL を使用して開発できます。KCL は、分散コンピューティングに関連する多くの複雑なタスクを処理します。たとえば、複数のインスタンス間でのロードバランシング、インスタンスの障害に対する応答、処理済みのレコードのチェックポイント作成、リシャーディングへの対応が挙げられます。KCL によって、レコード処理のロジックの記述に集中できます。独自の KCL アプリケーションを構築する方法の詳細については、「[Kinesis クライアントライブラリの使用](https://docs.aws.amazon.com/streams/latest/dev/shared-throughput-kcl-consumers.html)」を参照してください。
Lambda 関数をサブスクライブして、Kinesis のストリーミングからレコードのバッチを自動的に読み取り、ストリーミングでレコードが検出された場合は処理できます。AWS Lambda はストリーミングを定期的 (1 秒に 1 回) にポーリングして新しいレコードを検出し、新しいレコードを検出すると Lambda 関数を呼び出して新しいレコードをパラメータとして渡します。Lambda 関数は、新しいレコードが検出された場合にのみ実行されます。Lambda 関数を共有スループットコンシューマー (標準イテレーター) にマッピングできます。
ストリーミングからデータを受信している他のコンシューマーと競合しない専用スループットが必要な場合は、[拡張ファンアウト](https://docs.aws.amazon.com/streams/latest/dev/enhanced-consumers.html)と呼ばれる機能を使用するコンシューマーを構築できます。この機能により、コンシューマーは、シャードあたり 1 秒間に最大 2 MB のデータのスループットで、ストリーミングからレコードを受け取ることができます。
ほとんどの場合、Kinesis Data Analytics、KCL、AWS Glue、または AWS Lambda を使用して、ストリーミングからのデータを処理する必要があります。ただし、Kinesis Data Streams API を使用してコンシューマーアプリケーションを最初から作成することもできます。Kinesis Data Streams API には、ストリーミングからデータを取得するための `GetShardIterator` および `GetRecords` メソッドが用意されています。
このプルモデルでは、コードはストリーミングのシャードから直接データを抽出します。API を使用して独自のコンシューマーアプリケーションを作成する方法の詳細については、「[AWS SDK for Java を使用したスループット共有カスタムコンシューマーの開発](https://docs.aws.amazon.com/streams/latest/dev/developing-consumers-with-sdk.html)」を参照してください。API に関する詳細については、「[Amazon Kinesis Data Streams API Reference](https://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html)」を参照してください。
### AWS Lambda を使用してデータのストリーミングを処理する
[AWS Lambda](https://aws.amazon.com/lambda/faqs/) によって、サーバーのプロビジョニングや管理をすることなく、コードを実行できるようになります。Lambda では、実質的にあらゆるタイプのアプリケーションやバックエンドサービスに対して、管理タスクを実行せずにコードを実行できます。コードをアップロードするだけで、コードの実行とスケールに必要な処理はすべて Lambda により自動的に実行され、高い可用性が維持されます。コードは、AWS の他のサービスから自動的にトリガーしたり、ウェブやモバイルアプリケーションから直接呼び出したりするように設定できます。
AWS Lambda は Amazon Kinesis Data Streams とネイティブに統合されます。このネイティブ統合を使用すると、ポーリング、チェックポイント、エラー処理の複雑さが抽象化されます。これにより、Lambda 関数コードはビジネスロジックの処理に集中できます。
Lambda 関数を共有スループット (標準イテレーター) にマップすることも、拡張ファンアウトを使用する専用スループットコンシューマーにマップすることもできます。標準イテレーターの場合、Lambda は HTTP プロトコルを使用して、Kinesis のストリーミングの各シャードにレコードがあるかどうかをポーリングします。レイテンシーを最小限に抑え、読み取りスループットを最大化するために、拡張ファンアウトを使用するデータストリームコンシューマーを作成できます。このアーキテクチャのストリームコンシューマーは、同じストリーミングから読み取る他のアプリケーションと競合することなく、各シャードへの専用接続を取得します。Amazon Kinesis Data Streams は HTTP/2 経由でレコードを Lambda にプッシュします。
デフォルトでは、AWS Lambda はストリーミングのレコードが利用可能になるとすぐに、関数を呼び出します。バッチシナリオでレコードをバッファするには、イベントソースで最大 5 分間のバッチウィンドウを実装できます。関数がエラーを返した場合、処理が成功するか、データの有効期限が切れるまで、Lambda はバッチを再試行します。
### 概要
*InternetProvider* 社は、Amazon Kinesis Data Streams を活用して、ユーザーの詳細と場所をストリーミングしました。レコードのストリーミングは AWS Lambda で消費され、関数のライブラリに保存された帯域幅オプションを使用して、データがエンリッチされました。エンリッチメント後、AWS Lambda は帯域幅オプションをアプリケーションにパブリッシュして戻しました。Amazon Kinesis Data Streams と AWS Lambda は、サーバーのプロビジョニングと管理を処理し、*InternetProvider* 社はビジネスアプリケーション開発により集中できるようになりました。