翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データプレーン制御の退避
データプレーンのみのアクションを使用してアベイラビリティーゾーンの退避を実行するのに実装できるソリューションはいくつかあります。このセクションでは、そのうちの 3 つと、それらのいずれかを選択する必要のあるユースケースについて説明します。
これらのソリューションのいずれかを使用する場合は、移行するアベイラビリティーゾーンの負荷を処理するのに十分なキャパシティが残りのアベイラビリティーゾーンにあることを確認する必要があります。最も回復力の高いのは、各アベイラビリティーゾーンで必要なキャパシティを事前にプロビジョニングしておくことです。3 つのアベイラビリティーゾーンを使用している場合、ピーク負荷を処理するのに必要なキャパシティの 50% を各ゾーンにデプロイできます。そのため、1 つのアベイラビリティーゾーンが失われても、コントロールプレーンに頼って追加のプロビジョニングを行うことなく、必要なキャパシティの 100% を確保できます。
さらに、EC2 Auto Scaling を使用している場合は、シフト中に Auto Scaling グループ (ASG) がスケールインしないようにします。そうすれば、シフトが終了しても、グループにはカスタマーのトラフィックを処理するのに十分なキャパシティが残ります。そのためには、ASG に必要な最小キャパシティが現在のカスタマーの負荷に対応できるようにする必要があります。また、P90 や P99 のような外れ値の多いパーセンタイルメトリクスではなく、メトリクスに平均値を使用することで、ASG が誤ってスケールインすることを防ぐこともできます。
シフト中は、トラフィックを処理しなくなったリソースの使用率は非常に低くなるはずですが、他のリソースは新しいトラフィックに合わせて使用率を高め、平均値がほぼ一定に保たれるため、スケールインアクションが防止されます。最後に、ALB および NLB に対してターゲットグループの健全性設定を使用し、DNS フェイルオーバーを正常なホストの割合または数で指定することもできます。これにより、正常なホストが十分にないアベイラビリティーゾーンにトラフィックがルーティングされるのを防ぎます。
Route 53 Application Recovery Controller (ARC) のゾーンシフト
アベイラビリティーゾーンの退避の最初のソリューションでは、Route 53 ARC のゾーンシフトを使用します。このソリューションは、NLB または ALB をカスタマートラフィックの入力ポイントとして使用するリクエスト/レスポンスワークロードに使用できます。
アベイラビリティーゾーンに障害が発生したことを検出すると、Route 53 ARC でゾーンシフトを開始できます。このオペレーションが完了し、既存のキャッシュされた DNS レスポンスの有効期限が切れると、新しいリクエストはすべて残りのアベイラビリティーゾーンのリソースにのみルーティングされます。次の図は、ゾーンシフトの仕組みを示しています。以下の図では、my-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com を指定する www.example.com の Route 53 エイリアスレコードがあります。ゾーンシフトはアベイラビリティーゾーン 3 に対して実行されます。

ゾーンシフト
この例では、プライマリデータベースインスタンスがアベイラビリティーゾーン 3 にない場合、最初の退避の成果を得るために必要なアクションはゾーンシフトの実行のみで、影響を受けているアベイラビリティーゾーンでは作業が処理されません。プライマリノードがアベイラビリティーゾーン 3 にあった場合、Amazon RDS がまだ自動的にフェイルオーバーしていなければ、ゾーンシフトと連携して (Amazon RDS コントロールプレーンに依存する) 手動で開始したフェイルオーバーを実行できます。これは、このセクションのすべてのデータプレーン制御ソリューションに当てはまります。
退避の開始に必要な依存関係を最小限に抑えるために、CLI コマンドまたは API を使用してゾーンシフトを開始する必要があります。退避プロセスが簡単であればあるほど、信頼性が向上します。特定のコマンドは、オンコールエンジニアが簡単にアクセスできるローカルランブックに保存できます。アベイラビリティーゾーンの退避には、ゾーンシフトが最も好ましく、最もシンプルなソリューションです。
Route 53 ARC
2 つ目のソリューションは、Route 53 ARC の機能を使用して特定の DNS レコードの状態を手動で指定する方法です。このソリューションには、可用性の高い Route 53 ARC クラスターデータプレーンを使用できるという利点があり、最大 2 つの異なる AWS リージョン の障害に対する耐障害性が得られます。これには追加コストがかかるというトレードオフがあり、DNS レコードの追加設定が必要になります。このパターンを実装するには、ロードバランサー (ALB または NLB) によって提供されるアベイラビリティーゾーン固有の DNS 名にエイリアスレコードを作成する必要があります。これを次の表に示します。
表 3: ロードバランサーのゾーン DNS 名に設定された Route 53 エイリアスレコード
|
ルーティングポリシー: 加重 名前: タイプ: 値: 加重: ターゲットの正常性の評価: true |
ルーティングポリシー: 加重 名前: タイプ: 値: 加重: ターゲットの正常性の評価: |
ルーティングポリシー: 加重 名前: タイプ: 値: 加重: ターゲットの正常性の評価: |
これらの DNS レコードごとに、Route 53 ARC ルーティング制御に関連付けられた Route 53 ヘルスチェックを設定します。アベイラビリティーゾーンの退避を開始するとき、ルーティング制御状態を Off に設定します。AWS では、アベイラビリティーゾーンの退避を開始するのに必要な依存関係を最小限に抑えるために、CLI または API を使用してこれを行うことをお勧めしています。ベストプラクティスとして、Route 53 ARC クラスターエンドポイントのローカルコピーを保存しておくと、退避が必要なときに ARC コントロールプレーンからそれらを取得する必要がなくなります。
この方法を使用する際のコストを最小限に抑えるために、1 つの Route 53 ARC クラスターとヘルスチェックを 1 つの AWS アカウント に作成し、組織でヘルスチェックを他の AWS アカウント と共有するus-east-1a) ではなく、アベイラビリティーゾーン ID (AZ-ID) (例えば use1-az1) を使用する必要があります。これは、AWS は、物理的なアベイラビリティーゾーンを各 AWS アカウント のアベイラビリティーゾーン名にランダムにマッピングためです。AZ-ID を使用すると、同じ物理的位置を一貫して参照できます。アベイラビリティーゾーンの退避を開始すると、例えば use1-az2 に対して、各 AWS アカウント の Route 53 レコードセットは、それらが AZ-ID マッピングを使用して、各 NLB レコードに適切なヘルスチェックを設定するようにします。
例えば、Route 53 のヘルスチェックが use1-az2 に対する Route 53 の ARC ルーティング制御に ID 0385ed2d-d65c-4f63-a19b-2412a31ef431 で関連付けられているとします。このヘルスチェックを利用したい別の AWS アカウント で、us-east-1c が use1-az2 にマップされている場合、レコード us-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com に use1-az2 のヘルスチェックを使用する必要があります。ヘルスチェック ID 0385ed2d-d65c-4f63-a19b-2412a31ef431 をそのリソースレコードセットで使用します。
セルフマネージド型 HTTP エンドポイントの使用
特定のアベイラビリティーゾーンのステータスを示す独自の HTTP エンドポイントを管理することで、このソリューションを実装することもできます。これにより、HTTP エンドポイントからのレスポンスに基づいて、アベイラビリティーゾーンに異常があるときを手動で指定できます。このソリューションは、Route 53 ARC を使用するよりもコストは低くなりますが、ゾーンシフトよりもコストがかかり、追加のインフラストラクチャを管理する必要があります。さまざまなシナリオに対してはるかに柔軟に対応できるという利点があります。
このパターンは NLB または ALB アーキテクチャと Route 53 ヘルスチェックで使用できます。また、ワーカーノードが独自のヘルスチェックを行うサービス検出システムやキュー処理システムなど、負荷分散されていないアーキテクチャでも使用できます。このようなシナリオでは、ホストはバックグラウンドスレッドを使用して、自分の AZ-ID を使用して HTTP エンドポイントに定期的にリクエストを送信し (これを見つける方法の詳細については 付録 A — アベイラビリティーゾーン ID の取得 を参照)、アベイラビリティーゾーンの状態に関するレスポンスを受け取ることができます。
アベイラビリティーゾーンに異常があると宣言された場合、対応方法には複数の選択肢があります。ELB や Route 53 などのソースからの外部ヘルスチェック、またはサービス検出アーキテクチャのカスタムヘルスチェックに失敗するように選択し、それらのサービスに対してホストに異常があるように見せることができます。また、リクエストを受け取った場合に即座にエラーで応答し、クライアントがバックオフして再試行できるようにすることもできます。イベント駆動型アーキテクチャでは、SQS メッセージを意図的にキューに返すなど、ノードでの作業の処理を意図的に失敗させることができます。中央のサービススケジュールが特定のホストで動作するワークルーターアーキテクチャでは、このパターンを使用することもできます。ルーターは、ワーカー、エンドポイント、またはセルを選択する前に、アベイラビリティーゾーンのステータスを確認できます。AWS Cloud Map を使用するサービス検出アーキテクチャでは、AZ-ID などのフィルターをリクエストで指定することでエンドポイントを検出する
次の図は、この方法を複数のタイプのワークロードにどのように使用できるかを示しています。
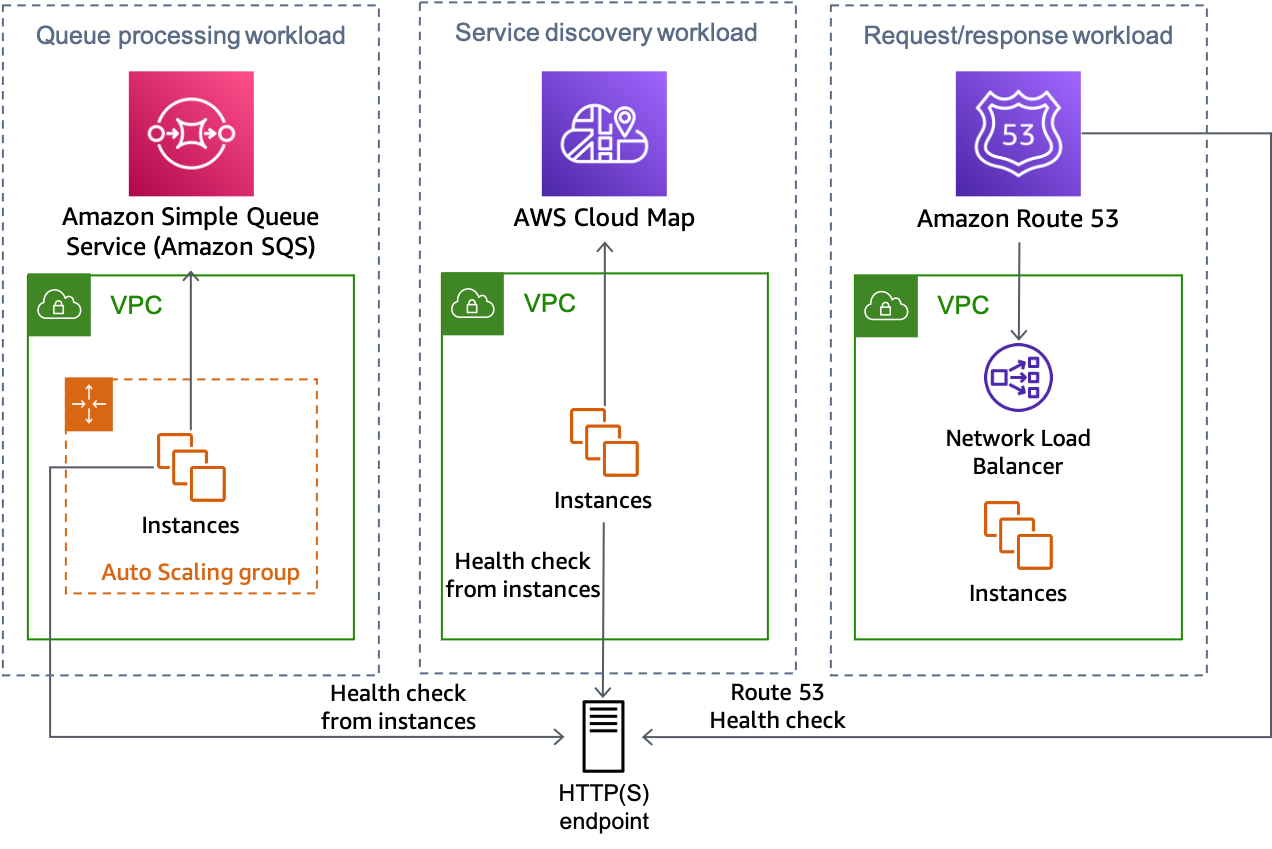
複数のワークロードのタイプすべてが HTTP エンドポイントソリューションを使用できる
HTTP エンドポイントアプローチを実装する方法は複数ありますが、次にそのうち 2 つについて概説します。
Amazon S3 の使用
このパターンは元々マルチリージョンのディザスタリカバリに関するこのブログ投稿
このシナリオでは、上記の Route 53 ARC シナリオおよび関連するヘルスチェックのように、ゾーン DNS レコードごとに Route 53 DNS リソースレコードセットを作成します。ただし、この実装では、ヘルスチェックを Route 53 ARC ルーティング制御に関連付ける代わりに、HTTP エンドポイントを使用するように設定され、Amazon S3 の障害によって誤って退避がトリガーされるのを防ぐため、反転されています。ヘルスチェックは、オブジェクトが存在しないときは健全、オブジェクトが存在するときは異常があるとみなされます。このセットアップを次の表に示します。
表 4: アベイラビリティーゾーンごとの Route 53 ヘルスチェックを使用するための DNS レコード設定
|
ヘルスチェックタイプ: エンドポイントをモニタリングする プロトコル: ID: URL: |
ヘルスチェックタイプ: エンドポイントをモニタリングする プロトコル: ID: URL: |
ヘルスチェックタイプ: エンドポイントをモニタリングする プロトコル: ID: URL: |
← | ヘルスチェック |
| ↑ | ↑ | ↑ | ||
|
ルーティングポリシー: 加重 名前: タイプ: 値: 加重: ターゲットの正常性の評価: |
ルーティングポリシー: 加重 名前: タイプ: 値: 加重: ターゲットの正常性の評価: |
ルーティングポリシー: 加重 名前: タイプ: 値: 加重: ターゲットの正常性の評価: |
← | NLB AZ 固有のエンドポイントを指定するトップレベルの均等に重み付けされたエイリアス A レコード |
アベイラビリティーゾーン us-east-1aをアベイラビリティーゾーンの退避を実行したいワークロードがあるアカウントの use1-az3 にマッピングすると仮定します。us-east-1a.load-balancer-name.elb.us-east-1.amazonaws.com に作成されたリソースレコードセットは、URL https:// をテストするヘルスチェックを関連付けます。bucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3 に対してアベイラビリティーゾーンの退避を開始したい場合、use1-az3.txt という名前のファイルを CLI または API を使用してバケットにアップロードします。ファイルにコンテンツを含める必要はありませんが、Route 53 ヘルスチェックがファイルにアクセスできるように公開する必要があります。次の図は、この実装が use1-az3 の退避に使用されていることを示しています。

Route 53 ヘルスチェックのターゲットとして Amazon S3 を使用している
API Gateway と DynamoDB を使用する
このパターンの 2 番目の実装では、Amazon API Gateway
このソリューションを NLB または ALB アーキテクチャで使用している場合は、上記の Amazon S3 の例と同じ方法で DNS レコードを設定してください。ただし、API Gateway エンドポイントを使用するようにヘルスチェックパスを変更し、URL パスに AZ-ID を提供します。例えば、API Gateway がカスタムドメイン az-status.example.com で設定されているとします。use1-az1 の完全なリクエストは https://az-status.example.com/status/use1-az1 のようになります。アベイラビリティーゾーンの退避を開始する場合、CLI または API を使用して DynamoDB アイテムを作成または更新できます。このアイテムは AZ-ID をプライマリキーとして使用し、API Gateway がどのように応答するかを示す Healthy と呼ばれる Boolean 属性があります。以下は、この判断を行うために API Gateway 設定で使用されるコード例です。
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
属性が true の場合 (または存在しない場合)、API Gateway はヘルスチェックに HTTP 200 で応答し、false の場合は HTTP 500 で応答します。この実装を次の図に示します。

Route 53 のヘルスチェックのターゲットとして API Gateway と DynamoDB を使用している
このソリューションでは、DynamoDB の前で API Gateway を使用する必要があります。これにより、エンドポイントをパブリックにアクセス可能にしたり、リクエスト URL を DynamoDB の GetItem リクエストに操作できるようになります。このソリューションでは、リクエストに追加データを含めたい場合にも柔軟に対応できます。例えば、アプリケーションごとなど、より詳細なステータスを作成したい場合は、パスまたはクエリ文字列にアプリケーション ID を指定するようにヘルスチェック URL を設定できます。これは DynamoDB アイテムとも一致します。
アベイラビリティーゾーンのステータスエンドポイントは一元的にデプロイできるため、AWS アカウント 全体にわたる複数のヘルスチェックリソースのすべてが、アベイラビリティーゾーンの状態の同じ一貫したビューを使用できるようになり (API Gateway REST API と DynamoDB テーブルが負荷を処理できるようにスケールされます)、Route 53 のヘルスチェックを共有する必要性がなくなります。
このソリューションは、Amazon DynamoDB グローバルテーブル
個別のホストが AZ の状態を判断するメカニズムとして使用するソリューションを構築する場合は、代替方法として、ヘルスチェック用のプルメカニズムを提供する代わりに、プッシュ通知を使用できます。これを行う 1 つの方法は、コンシューマーがサブスクライブしている SNS トピックを使用することです。サーキットブレーカーをトリガーする場合は、どのアベイラビリティーゾーンに障害があるかを示すメッセージを SNS トピックに発行します。このアプローチでは、前者とのトレードオフが生じます。これにより、API Gateway インフラストラクチャを作成して運用したり、容量管理を実行したりする必要がなくなります。また、アベイラビリティーゾーンの状態をより迅速に収束できる可能性もあります。ただし、アドホッククエリを実行する機能は削除されます。また、各エンドポイントに通知を確実に届けるために SNS メッセージ配信の再試行ポリシーに依存します。また、各ワークロードやサービスが SNS 通知を受信してアクションを実行する方法を構築する必要もあります。
例えば、新しい EC2 インスタンスやコンテナを起動するたびに、ブートストラップ中に HTTP エンドポイントを使用してトピックをサブスクライブする必要があります。次に、各インスタンスは、このエンドポイントに配信される通知をリッスンするソフトウェアを実装する必要があります。さらに、インスタンスは、イベントの影響を受けた場合に、プッシュ通知を受け取らずに作業を続ける可能性があります。一方、プル通知を使用すると、インスタンスはプルリクエストが失敗したかどうかを知り、それに応じてどのアクションを実行するかを選択できます。
プッシュ通知を送信する 2 番目の方法は、存続期間の長い WebSocket 接続を使用することです。Amazon API Gateway を使用すると、コンシューマーが接続できる WebSocket API を指定でき、バックエンドから送信されたメッセージを受信できます。WebSocket を使用すると、インスタンスは定期的なプルを実行して接続が正常であることを確認するとともに、低レイテンシーのプッシュ通知を受け取ることができます。
