翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# 語彙フィルターを作成する
カスタム語彙フィルターの作成には次の 2 つのオプションがあります。
1. 行で区切られた単語のリストを、UTF-8 エンコーディングのプレーンテキストファイルとして保存する。
+ このアプローチは AWS マネジメントコンソール、、 AWS CLI、または AWS SDKsで使用できます。
+ を使用する場合は AWS マネジメントコンソール、カスタム語彙ファイルのローカルパスまたは Amazon S3 URI を指定できます。
+ AWS CLI AWS SDKs を使用する場合は、カスタム語彙ファイルを Amazon S3 バケットにアップロードし、リクエストに Amazon S3 URI を含める必要があります。
1. カンマ区切りの単語のリストを API リクエストに直接含めます。
+ このアプローチは、 [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html#transcribe-CreateVocabularyFilter-request-Words](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html#transcribe-CreateVocabularyFilter-request-Words)パラメータを使用して AWS CLI または AWS SDKsで使用できます。
各方法の例については、「[カスタム語彙フィルターの作成](#vocabulary-filtering-create-examples)」を参照してください。
カスタム語彙フィルターを作成する際の注意事項
+ 単語では、大文字と小文字が区別されません。例えば、「curse」と「CURSE」は同じとみなされます。
+ 完全に一致する単語のみがフィルタリングされます。例えば、フィルターに「swear」が含まれていても、メディアに「swears」または「swearing」という単語が含まれている場合、これらはフィルタリングされません。フィルターの対象となるのは「swear」のインスタンスのみです。そのため、フィルタリングしたい単語のバリエーションをすべて含める必要があります。
+ フィルターは他の単語に含まれる単語には適用されません。例えば、カスタム語彙フィルターに「marine」が含まれていても、「submarine」が含まれていない場合、トランスクリプトでは「submarine」は変更されません。
+ 各エントリには 1 つの単語のみ入力できます (スペースなし)。
+ カスタム語彙フィルターをテキストファイルとして保存する場合は、UTF-8 エンコーディングのプレーンテキスト形式である必要があります。
+ ごとに最大 100 個のカスタム語彙フィルターを持つことができ AWS アカウント 、各語彙フィルターのサイズは最大 50 KB です。
+ 使用する言語でサポートされている文字のみを使用できます。詳細については、ご使用の言語の[文字セット](charsets.md)を参照してください。
## カスタム語彙フィルターの作成
で使用するカスタム語彙フィルターを処理するには Amazon Transcribe、次の例を参照してください。
### AWS マネジメントコンソール
続行する前に、カスタム語彙フィルターをテキスト (\*.txt) ファイルとして保存してください。オプションで、ファイルを Amazon S3 バケットにアップロードできます。
1. [AWS マネジメントコンソール](https://console.aws.amazon.com/transcribe/) にサインインします。
1. ナビゲーションペインで、[**語彙フィルタリング**] を選択します。**語彙フィルター**ページが開き、既存のカスタム語彙フィルタ―を表示したり、新しい語彙フィルターを作成したりできます。
1. [**語彙フィルターの作成**] を選択します。
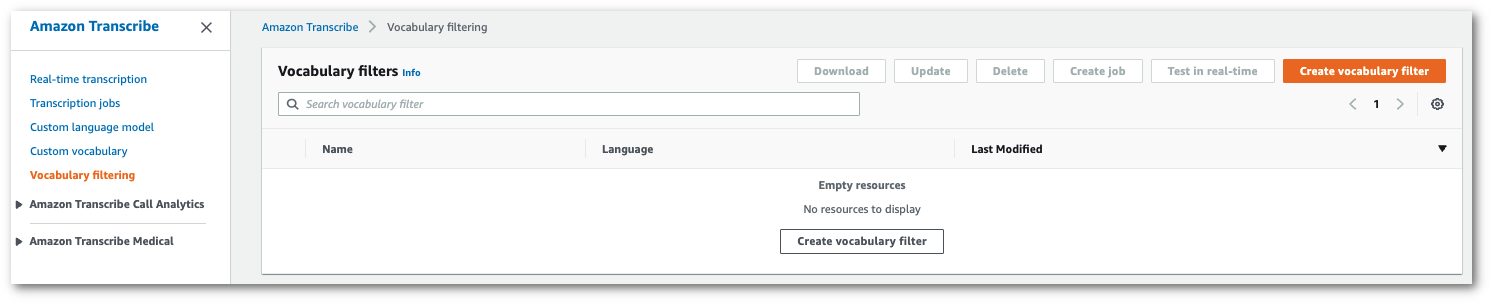
これにより「**語彙フィルターの作成**」ページに移動します。新しいカスタム語彙フィルターの名前を入力します。
[**語彙入力ソース**] で [**ファイルアップロード**] または [**S3 ロケーション**] オプションを選択します。次に、カスタム語彙ファイルの場所を指定します。
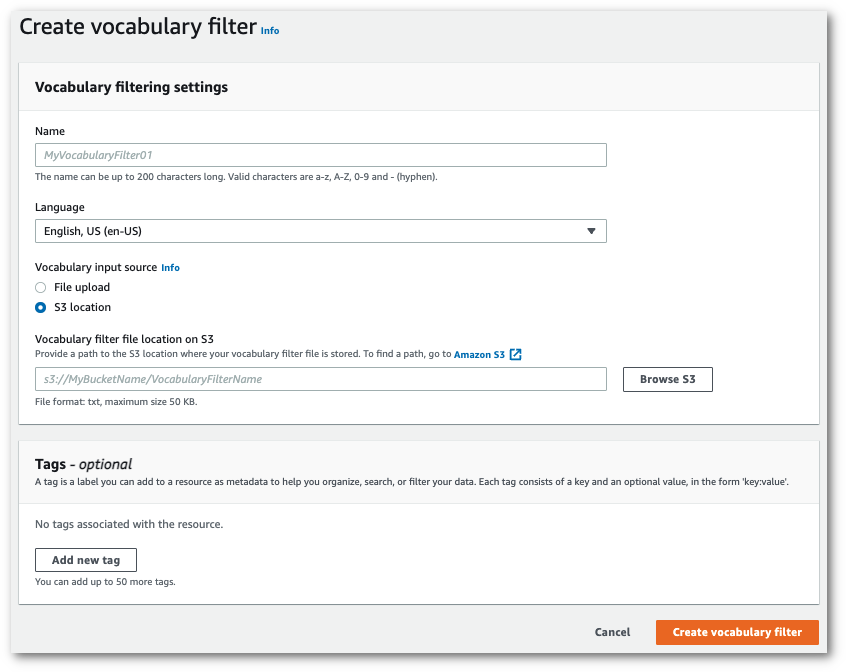
1. オプションで、カスタム語彙フィルターにタグを追加します。すべてのフィールドを入力したら、ページの一番下にある [**語彙フィルターの作成**] を選択します。ファイルの処理中にエラーがなければ、**語彙フィルター**ページに戻ります。
カスタム語彙フィルターを使用する準備ができました。
### AWS CLI
この例では、[create-vocary-filter](https://docs.aws.amazon.com/cli/latest/reference/transcribe/create-vocabulary-filter.html) コマンドを使用して、単語リストを使用可能なカスタム語彙フィルターに加工します。詳細については、「[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html)」を参照してください。
**オプション 1**: `words` パラメータを使用して単語リストをリクエストに含めることができます。
```
aws transcribe create-vocabulary-filter \
--vocabulary-filter-name {{my-first-vocabulary-filter}} \
--language-code {{en-US}} \
--words {{profane,offensive,Amazon,Transcribe}}
```
**オプション 2**: 単語リストをテキストファイルとして保存して Amazon S3 バケットにアップロードし、`vocabulary-filter-file-uri` パラメータを使用してファイルの URI をリクエストに含めることができます。
```
aws transcribe create-vocabulary-filter \
--vocabulary-filter-name {{my-first-vocabulary-filter}} \
--language-code {{en-US}} \
--vocabulary-filter-file-uri s3://{{amzn-s3-demo-bucket}}/{{my-vocabulary-filters}}/{{my-vocabulary-filter}}.txt
```
ここでは、[create-vocabulary-filter](https://docs.aws.amazon.com/cli/latest/reference/transcribe/create-vocabulary-filter.html) コマンドと、カスタム語彙フィルターを作成するリクエストボディを使用した別の例を示します。
```
aws transcribe create-vocabulary-filter \
--cli-input-json file://{{filepath}}/{{my-first-vocab-filter}}.json
```
ファイル *my-first-vocab-filter.json* には、次のリクエストボディが含まれています。
**オプション 1**: `Words` パラメータを使用して単語リストをリクエストに含めることができます。
```
{
"VocabularyFilterName": "{{my-first-vocabulary-filter}}",
"LanguageCode": "{{en-US}}",
"Words": [
"{{profane}}","{{offensive}}","{{Amazon}}","{{Transcribe}}"
]
}
```
**オプション 2**: 単語リストをテキストファイルとして保存して Amazon S3 バケットにアップロードし、`VocabularyFilterFileUri` パラメータを使用してファイルの URI をリクエストに含めることができます。
```
{
"VocabularyFilterName": "{{my-first-vocabulary-filter}}",
"LanguageCode": "{{en-US}}",
"VocabularyFilterFileUri": "s3://{{amzn-s3-demo-bucket}}/{{my-vocabulary-filters}}/{{my-vocabulary-filter}}.txt"
}
```
**注記**
`VocabularyFilterFileUri` をリクエストに含めると、`Words` は使用できません。どちらか一方を選択する必要があります。
### AWS SDK for Python (Boto3)
この例では AWS SDK for Python (Boto3) 、 を使用して create[\_vocabulary\_filter メソッドを使用してカスタム語彙フィルター](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/transcribe.html#TranscribeService.Client.create_vocabulary_filter)を作成します。詳細については、「[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html)」を参照してください。
機能固有の例、シナリオ例、クロスサービス例など、 AWS SDKs[SDK を使用した Amazon Transcribe のコード例 AWS SDKs](service_code_examples.md)「」の章を参照してください。
**オプション 1**: `Words` パラメータを使用して単語リストをリクエストに含めることができます。
```
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', '{{us-west-2}}')
vocab_name = "{{my-first-vocabulary-filter}}"
response = transcribe.create_vocabulary_filter(
LanguageCode = '{{en-US}}',
VocabularyFilterName = vocab_name,
Words = [
'{{profane}}','{{offensive}}','{{Amazon}}','{{Transcribe}}'
]
)
```
**オプション 2**: 単語リストをテキストファイルとして保存して Amazon S3 バケットにアップロードし、`VocabularyFilterFileUri` パラメータを使用してファイルの URI をリクエストに含めることができます。
```
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', '{{us-west-2}}')
vocab_name = "{{my-first-vocabulary-filter}}"
response = transcribe.create_vocabulary_filter(
LanguageCode = '{{en-US}}',
VocabularyFilterName = vocab_name,
VocabularyFilterFileUri = 's3://{{amzn-s3-demo-bucket}}/{{my-vocabulary-filters}}/{{my-vocabulary-filter}}.txt'
)
```
**注記**
`VocabularyFilterFileUri` をリクエストに含めると、`Words` は使用できません。どちらか一方を選択する必要があります。
**注記**
カスタム語彙フィルターファイル用に新しい Amazon S3 バケットを作成する場合は、[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabularyFilter.html)リクエストを行う IAM ロールにこのバケットへのアクセス許可があることを確認してください。ロールに正しいアクセス許可がない場合、リクエストは失敗します。オプションで、 `DataAccessRoleArn`パラメータを含めることで、リクエスト内で IAM ロールを指定できます。の IAM ロールとポリシーの詳細については Amazon Transcribe、「」を参照してください[Amazon Transcribe アイデンティティベースのポリシーの例](security_iam_id-based-policy-examples.md)。