翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# テーブルを使用してカスタム語彙を作成する
カスタム語彙を作成するには、テーブル形式を使用することをおすすめします。語彙テーブルは 4 つの (Phrase, SoundsLike, IPA, and DisplayAs) 列で構成されている必要があり、どの順序でも含めることができます。
| フレーズ | SoundsLike | IPA | DisplayAs |
| --- | --- | --- | --- |
| 必須。テーブルのすべての行には、この列のエントリが含まれている必要があります。
この列にはスペースを使用しないでください。
エントリに複数の単語が含まれている場合は、各単語をハイフン (-) で区切ります。例えば、**Andorra-la-Vella**、**Los-Angeles** です。
頭字語の場合は、発音する文字をすべてピリオドで区切る必要があります。末尾のピリオドも発音する必要があります。頭字語が複数形の場合は、頭字語と「s」の間にハイフンを使用する必要があります。たとえば、「CLI」は **C.L.I.** (**C.L.I** ではない) で、「ABCs」は **A.B.C.-s** (**A.B.C-s** ではない) です。
フレーズが単語と頭字語の両方で構成されている場合は、これら 2 つの要素をハイフンでつなぐ必要があります。たとえば、「DynamoDB」は **Dynamo-D.B.** です。
この列には数字を含めないでください。数字はスペルアウトする必要があります。たとえば、「VX02Q」は **V.X.-zero-two-Q.** です。 | `SoundsLike` はカスタム語彙ではサポートされなくなりました。列は空のままにしてください。この列の値はすべて無視されます。今後、この列のサポートは廃止される予定です。 | `IPA` はカスタム語彙ではサポートされなくなりました。列は空のままにしてください。この列の値はすべて無視されます。今後、この列のサポートは廃止される予定です。 | オプション。この列の行は空のままでかまいません。
この列にはスペースを使用できます。
文字起こし出力でのエントリの表示方法を定義します。たとえば、`Phrase` 列の **Andorra-la-Vella** は `DisplayAs` 列の **Andorra la Vella** にあります。
この列の行が空の場合、 は`Phrase`列の内容 Amazon Transcribe を使用して出力を決定します。
この列には数字 (`0-9`) を含めることができます。 |
テーブルを作成する際の注意事項
+ テーブルには、必ず 4 つの列ヘッダー (Phrase, SoundsLike, IPA, and DisplayAs) を含めてください。`Phrase` 列には、各行に必ずエントリを含めてください。`IPA` と `SoundsLike` による発音入力機能はサポート終了となりました。これらの列は空のままにしておいてください。これらの列の値はすべて無視されます。
+ 各列は TAB またはカンマ (,) で区切る必要があります。これはカスタム語彙ファイルのすべての行に適用されます。行に空の列がある場合でも、各列に区切り記号 (TAB またはカンマ) を含める必要があります。
+ スペースは `IPA` 列と `DisplayAs` 列のみ使用できます。列を区切るのにスペースを使用しないでください。
+ `IPA` および `SoundsLike` は、カスタム語彙ではサポートされなくなりました。列は空のままにしてください。これらの列の値はすべて無視されます。今後、この列のサポートは廃止される予定です。
+ `DisplayAs` 列は記号と特殊文字 (C\+\+ など) をサポートします。他のすべての列は、使用している言語の[文字セット](charsets.md)ページに記載されている文字をサポートします。
+ `Phrase` 列には次の書式設定ルールがあります。
+ ピリオド (`.`)、アポストロフィ ()、またはハイフン (`'`) で始めることはできません`-`。たとえば、 **-hello**と **.test**は無効です。
+ アポストロフィ (`'`) またはハイフン () で終わることはできません`-`。たとえば、 **hello-**と **world'**は無効です。
+ 繰り返しハイフン (`--`)、繰り返しピリオド (`..`)、繰り返しアポストロフィ () を含めることはできません`''`。たとえば、 **well--known**と **can''t**は無効です。
+ ピリオドは、頭字語 ( などのピリオドで区切られた 1 文字) を示すためにのみ使用できます**A.B.C.**。ピリオドは、2 つ以上の連続する非特殊文字 (例: **AB.C**が無効) の後には表示できず、3 つ以上の連続する非特殊文字 (例: **A.BCD** が無効) の後には表示できません。
+ 言語の文字[セットにリストされている文字](charsets.md)のみがサポートされています。
+ `Phrase` 列に数字を含めたい場合は、数字をスペルアウトする必要があります。数字 (`0-9`) は `DisplayAs` 列でのみサポートされています。
+ テーブルはプレーンテキスト (\*.txt) ファイルとして保存する必要があります。`LF` と の両方の`CRLF`行末がサポートされています。
+ 文字起こしリクエストに含める[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html)前に、カスタム語彙ファイルを Amazon S3 バケットにアップロードし、 を使用して処理する必要があります。手順については、「[カスタム語彙テーブルを作成する](#custom-vocabulary-create-table-examples)」を参照してください。
**注記**
頭字語など、1 文字ずつ個別に発音する単語は、ピリオド (**A.B.C.**) で区切って 1 文字で入力します。「ABC」のように複数形の頭字語を入力するには、「s」と頭字語をハイフン (**A.B.C.-s**) で区切ります。頭字語の入力には、大文字と小文字のどちらでも使用できます。頭字語はすべての言語には対応していません。「[サポートされている言語および言語固有の機能](supported-languages.md)」を参照してください。
カスタム語彙テーブル (**[TAB]** はタブ文字を表す) の例を以下に示します。
```
Phrase[TAB]SoundsLike[TAB]IPA[TAB]DisplayAs
Los-Angeles[TAB][TAB][TAB]Los Angeles
Eva-Maria[TAB][TAB][TAB]
A.B.C.-s[TAB][TAB][TAB]ABCs
Amazon-dot-com[TAB][TAB][TAB]Amazon.com
C.L.I.[TAB][TAB][TAB]CLI
Andorra-la-Vella[TAB][TAB][TAB]Andorra la Vella
Dynamo-D.B.[TAB][TAB][TAB]DynamoDB
V.X.-zero-two[TAB][TAB][TAB]VX02
V.X.-zero-two-Q.[TAB][TAB][TAB]VX02Q
```
見やすくするために、同じ表に列をそろえて示します。カスタム語彙テーブルの列間にスペースを入れ**ないでください**。前の例のようにテーブルの位置がずれて見えるはずです。
```
Phrase [TAB]SoundsLike [TAB]IPA [TAB]DisplayAs
Los-Angeles [TAB] [TAB] [TAB]Los Angeles
Eva-Maria [TAB] [TAB] [TAB]
A.B.C.-s [TAB] [TAB] [TAB]ABCs
amazon-dot-com [TAB] [TAB] [TAB]amazon.com
C.L.I. [TAB] [TAB] [TAB]CLI
Andorra-la-Vella[TAB] [TAB] [TAB]Andorra la Vella
Dynamo-D.B. [TAB] [TAB] [TAB]DynamoDB
V.X.-zero-two [TAB] [TAB] [TAB]VX02
V.X.-zero-two-Q.[TAB] [TAB] [TAB]VX02Q
```
## カスタム語彙テーブルを作成する
で使用するカスタム語彙テーブルを処理するには Amazon Transcribe、次の例を参照してください。
### AWS マネジメントコンソール
1. [AWS マネジメントコンソール](https://console.aws.amazon.com/transcribe/) にサインインします。
1. ナビゲーションペインで、[**カスタム語彙**] を選択します。**カスタム語彙**のページが開き、既存の語彙の表示したり、新しい語彙を作成したりできます。
1. [**語彙の作成**] を選択します。
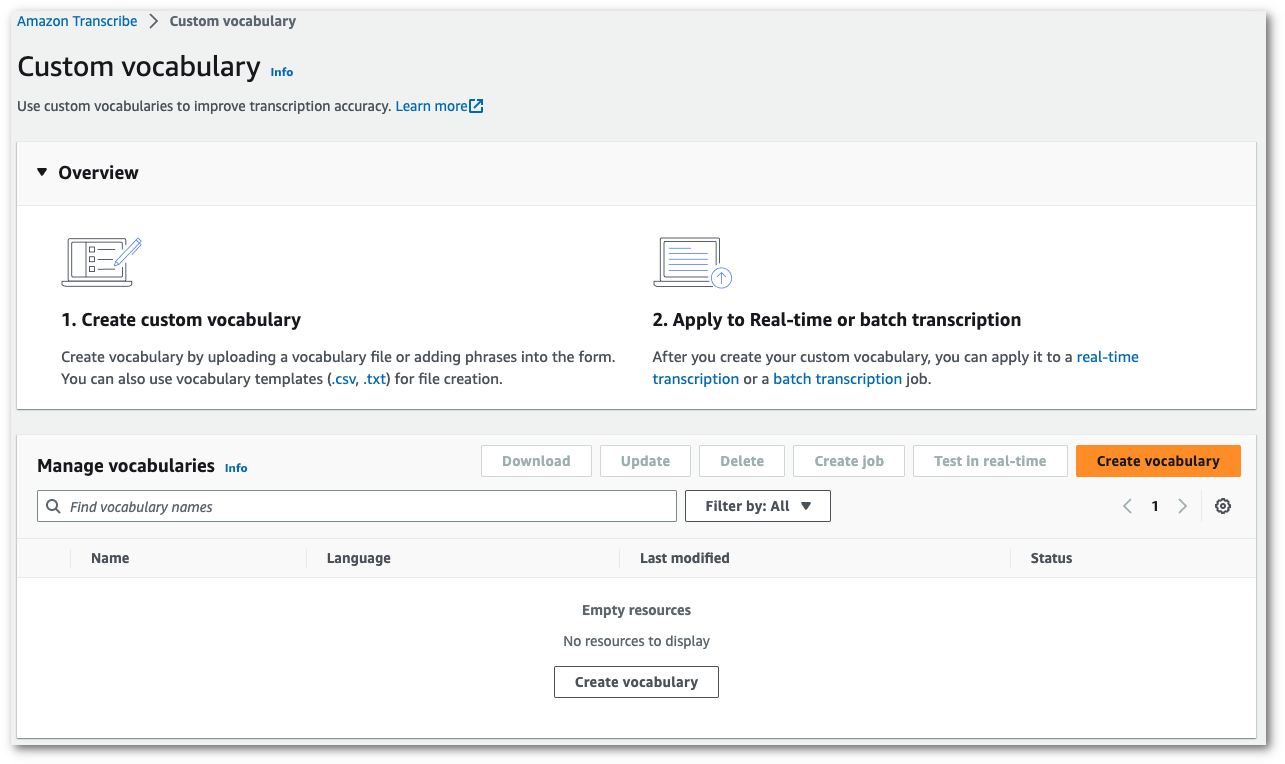
「**語彙の作成**」ページに移動します。新しいカスタム語彙の名前を入力します。
次の 3 つの選択肢があります。
1. コンピュータから txt または csv ファイルをアップロードします。
カスタム語彙を一から作成することも、テンプレートをダウンロードして始めることもできます。その後、**語彙の表示と編集**ペインに語彙が自動入力されます。
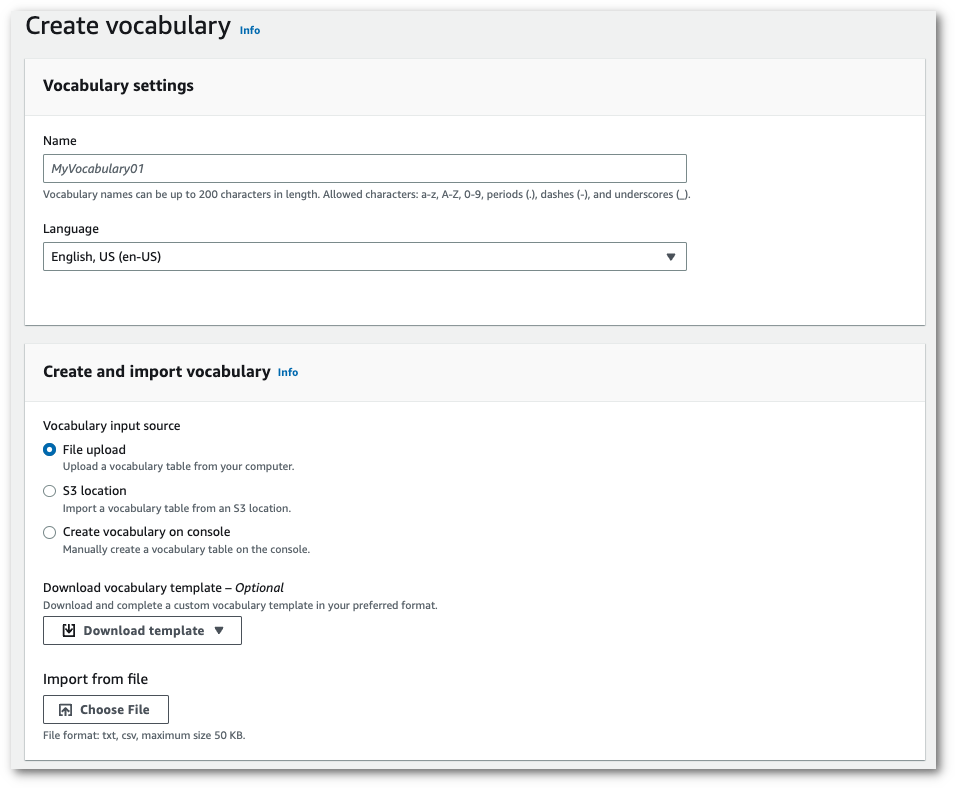
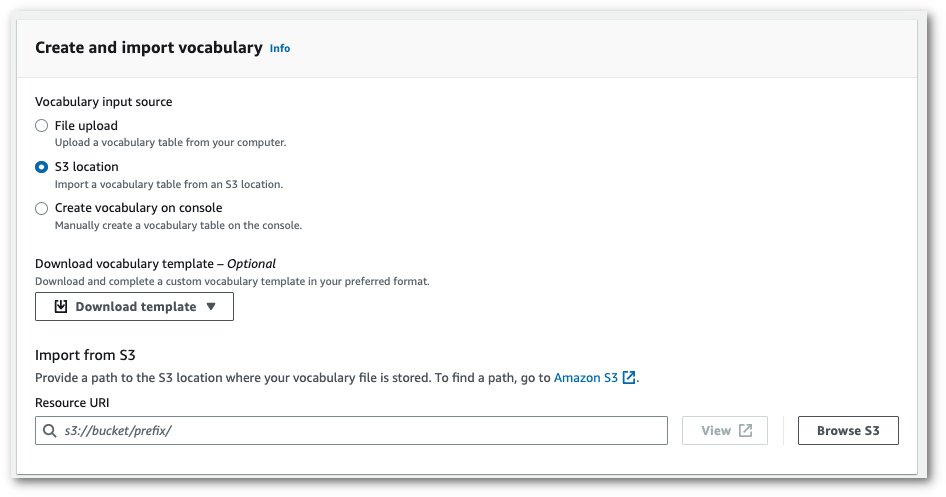
1. Amazon S3 場所から txt または csv ファイルをインポートします。
カスタム語彙を一から作成することも、テンプレートをダウンロードして始めることもできます。完成した語彙ファイルを Amazon S3 バケットにアップロードし、リクエストにその URI を指定します。その後、**語彙の表示と編集**ペインに語彙が自動入力されます。
1. コンソールで語彙を手動で作成します。
**語彙の表示と編集**ペインまでスクロールし、[**10 行追加**] を選択します。用語を手動で入力できるようになりました。
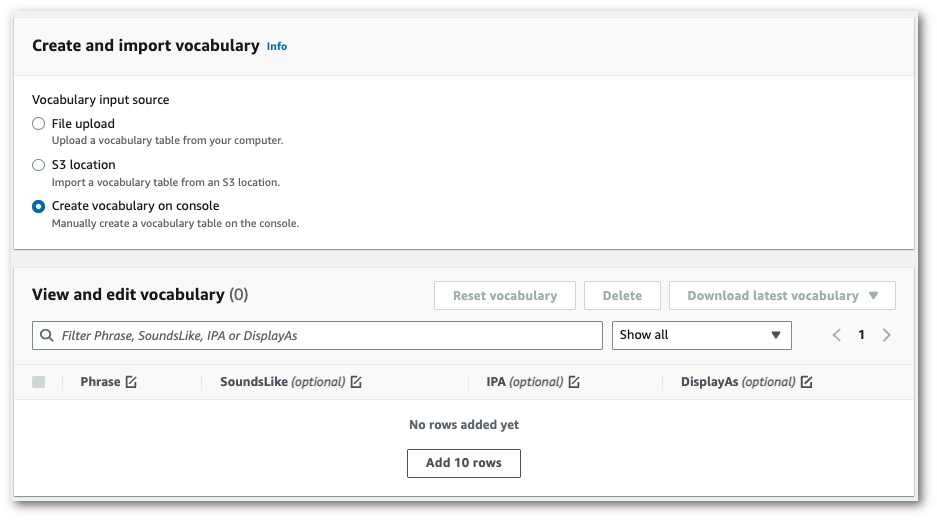
1. **語彙の表示と編集**ペインで語彙を編集できます。変更するには、変更するエントリをクリックします。
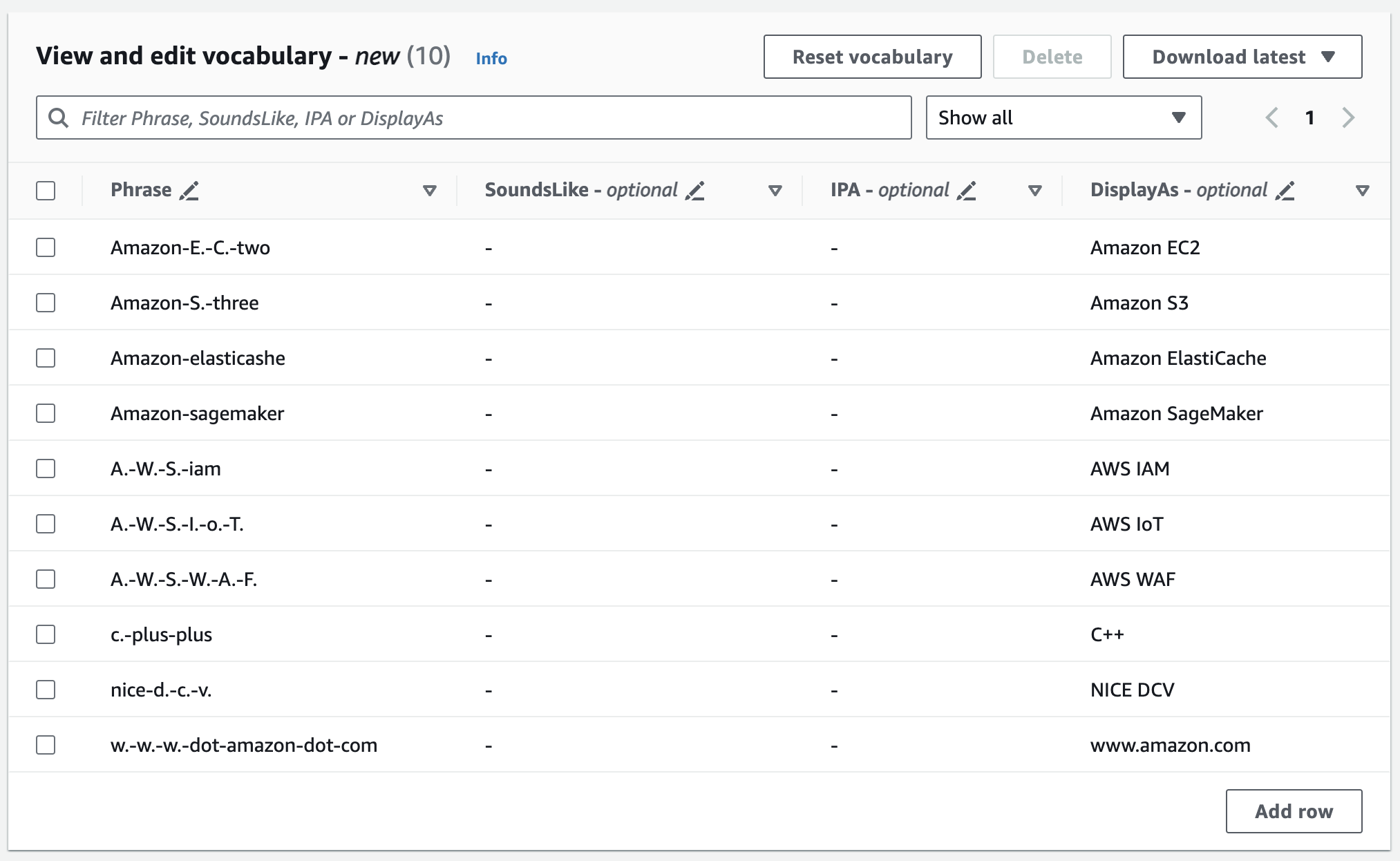
エラーがあると詳細なエラーメッセージが表示されるので、語彙を処理する前に問題を修正できます。[**語彙の作成**] を選択する前にすべてのエラーを修正しないと、語彙のリクエストは失敗するので注意してください。
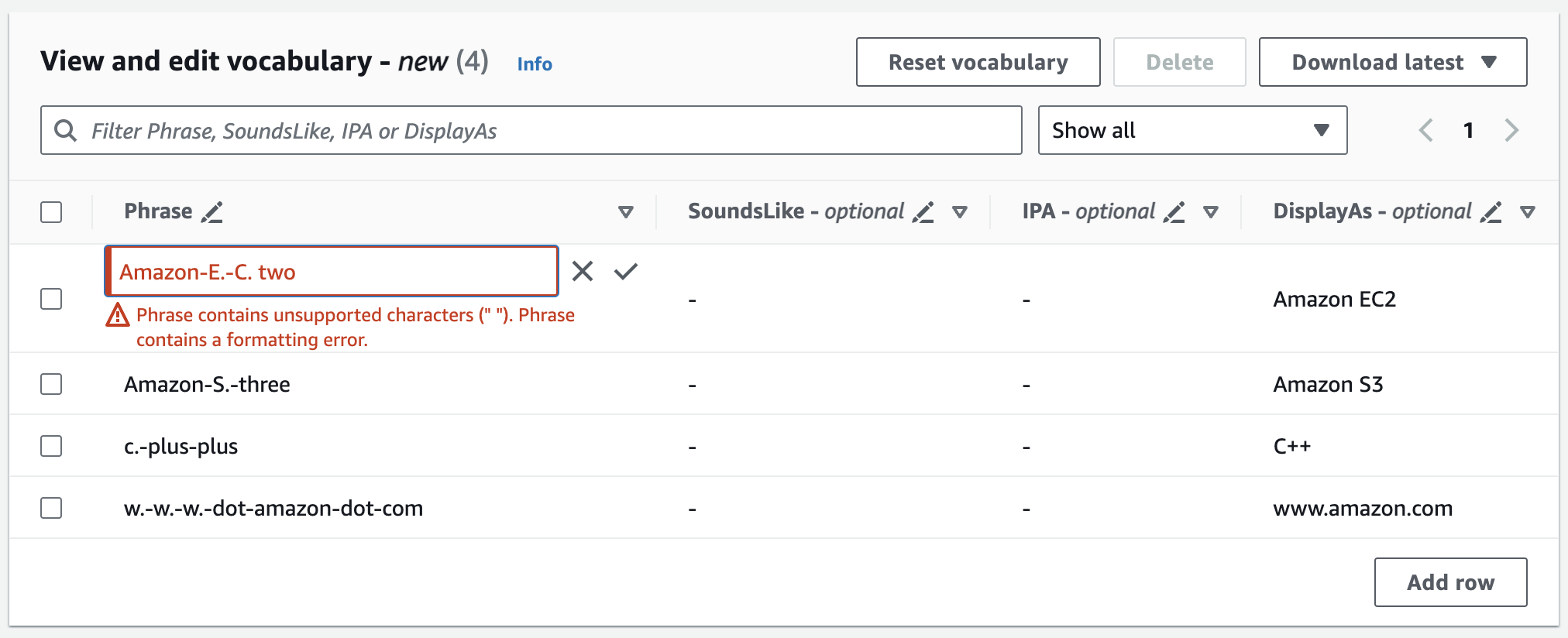
チェックマーク (✓) を選択して変更を保存するか、「X」を選択して変更を破棄します。
1. オプションで、カスタム語彙にタグを追加します。すべてのフィールドを入力し、語彙に問題がなければ、ページの一番下にある [**語彙の作成**] を選択します。**カスタム語彙**のページに戻ると、カスタム語彙のステータスを確認できます。ステータスが「保留中」から「準備完了」に変わったら、カスタム語彙を文字起こしに使用できます。

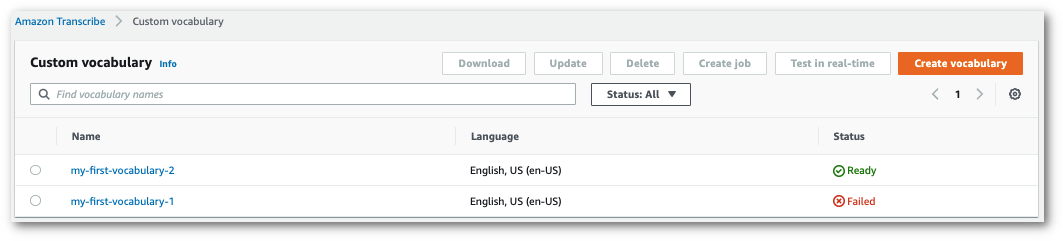
1. ステータスが「失敗」に変わったら、カスタム語彙の名前を選択して、その語彙の情報ページに移動します。
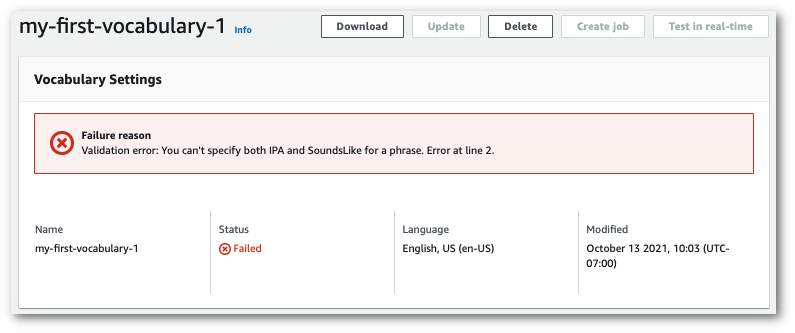
このページの上部には、カスタム語彙が失敗した理由に関する情報が記載された**失敗の理由**バナーがあります。テキストファイルのエラーを修正して、もう一度試してください。
### AWS CLI
この例では、テーブル形式の語彙ファイルで[語彙の作成](https://docs.aws.amazon.com/cli/latest/reference/transcribe/create-vocabulary.html)コマンドを使用します。詳細については、「[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html)」を参照してください。
文字起こしジョブで既存のカスタム語彙を使用するには、 [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html) オペレーションを呼び出すときに `VocabularyName` [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_Settings.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_Settings.html)フィールドに を設定するか、 からドロップダウンリストからカスタム語 AWS マネジメントコンソール彙を選択します。
```
aws transcribe create-vocabulary \
--vocabulary-name {{my-first-vocabulary}} \
--vocabulary-file-uri s3://{{amzn-s3-demo-bucket}}/{{my-vocabularies}}/{{my-vocabulary-file}}.txt \
--language-code {{en-US}}
```
ここでは、[語彙の作成](https://docs.aws.amazon.com/cli/latest/reference/transcribe/create-vocabulary.html)コマンドと、カスタム語彙を作成するリクエストボディを使用した別の例を示します。
```
aws transcribe create-vocabulary \
--cli-input-json file://{{filepath}}/{{my-first-vocab-table}}.json
```
ファイル *my-first-vocab-table.json* には、次のリクエストボディが含まれています。
```
{
"VocabularyName": "{{my-first-vocabulary}}",
"VocabularyFileUri": "s3://{{amzn-s3-demo-bucket}}/{{my-vocabularies}}/{{my-vocabulary-table}}.txt",
"LanguageCode": "{{en-US}}"
}
```
`VocabularyState` を`PENDING` から `READY` に変更すると、カスタム語彙を文字起こしに使用できるようになります。カスタム語彙の現在のステータスを表示するには、以下を実行します。
```
aws transcribe get-vocabulary \
--vocabulary-name {{my-first-vocabulary}}
```
### AWS SDK for Python (Boto3)
この例では AWS SDK for Python (Boto3) 、 を使用して create[\_vocabulary メソッドを使用してテーブルからカスタム語](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/transcribe.html#TranscribeService.Client.create_vocabulary)彙を作成します。詳細については、「[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html)」を参照してください。
文字起こしジョブで既存のカスタム語彙を使用するには、 [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html) オペレーションを呼び出すときに `VocabularyName` [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_Settings.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_Settings.html)フィールドに を設定するか、 からドロップダウンリストからカスタム語 AWS マネジメントコンソール彙を選択します。
機能固有の例、シナリオ例、クロスサービス例など、 AWS SDKs[SDK を使用した Amazon Transcribe のコード例 AWS SDKs](service_code_examples.md)「」の章を参照してください。
```
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', '{{us-west-2}}')
vocab_name = "{{my-first-vocabulary}}"
response = transcribe.create_vocabulary(
LanguageCode = '{{en-US}}',
VocabularyName = vocab_name,
VocabularyFileUri = 's3://{{amzn-s3-demo-bucket}}/{{my-vocabularies}}/{{my-vocabulary-table}}.txt'
)
while True:
status = transcribe.get_vocabulary(VocabularyName = vocab_name)
if status['VocabularyState'] in ['READY', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)
```
**注記**
カスタム語彙ファイル用に新しい Amazon S3 バケットを作成する場合は、[https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_CreateVocabulary.html)リクエストを行う IAM ロールにこのバケットへのアクセス許可があることを確認してください。ロールに正しいアクセス許可がない場合、リクエストは失敗します。オプションで、 `DataAccessRoleArn`パラメータを含めることで、リクエスト内で IAM ロールを指定できます。の IAM ロールとポリシーの詳細については Amazon Transcribe、「」を参照してください[Amazon Transcribe アイデンティティベースのポリシーの例](security_iam_id-based-policy-examples.md)。