統合ガイド
このソリューションは、簡単に拡張できるように設計されています。このソリューションのオーケストレーションレイヤーは、LangChain
サポートされている LLM の拡張
カスタム LLM プロバイダーなどの別のモデルプロバイダーを追加するには、ソリューションの次の 3 つのコンポーネントを更新する必要があります。
-
カスタム LLM プロバイダーで設定されたチャットアプリケーションをデプロイする新しい
TextUseCaseCDK スタックを作成します。-
このソリューションの GitHub リポジトリ
のクローンを作成し、README.md ファイルの手順に従ってビルド環境をセットアップします。 -
source/infrastructure/lib/bedrock-chat-stack.tsファイルをコピー (または新規作成) して同じディレクトリに貼り付け、名前をcustom-chat-stack.tsに変更します。 -
ファイル内のクラスの名前を、
CustomLLMChatなどの適切な名前に変更します。 -
このスタックに Secrets Manager シークレットを追加して、カスタム LLM の認証情報を保存することもできます。これらの認証情報は、次の段落で説明するチャット Lambda レイヤーでモデルを呼び出す際に取得できます。
-
-
追加するモデルプロバイダーの Python ライブラリを含む Lambda レイヤーを構築してアタッチします。Amazon Bedrock ユースケースのチャットアプリケーションの場合、
langchain-awsの Python ライブラリには、LangChain パッケージの上に構築されたカスタムコネクタが含まれており、AWS モデルプロバイダー (Amazon Bedrock および SageMaker AI)、ナレッジベース (Amazon Kendra および Amazon Bedrock ナレッジベース)、メモリタイプ (DynamoDB など) との接続に使用されます。同様に、他のモデルプロバイダーにも独自のコネクタがあります。このレイヤーは、このモデルプロバイダーの Python ライブラリをアタッチすることを目的としており、これにより、LLM を呼び出すチャット Lambda レイヤーでこれらのコネクタを使用できるようになります (ステップ 3)。このソリューションでは、カスタムアセットバンドラーを使用して Lambda レイヤーを構築し、CDK のアスペクトを使用してアタッチします。カスタムモデルプロバイダーライブラリの新しいレイヤーを作成するには:-
LambdaAspectsファイルのsource/infrastructure/lib/utils/lambda-aspects.tsクラスに移動します。 -
ファイル内で提供されている Lambda アスペクトクラスの機能を拡張する方法 (
getOrCreateLangchainLayerメソッドの追加など) についての手順に従います。この新しいメソッド (getOrCreateCustomLLMLayerなど) を使用するには、source/infrastructure/lib/utils/constants.tsファイル内のLLM_LIBRARY_LAYER_TYPES列挙型も更新します。
-
-
chatLambda 関数を拡張して、新しいプロバイダーのビルダー、クライアント、ハンドラーを実装します。source/lambda/chatには、さまざまな LLM の LangChain 接続と、これらの LLM を構築するためのサポートクラスが含まれています。これらのサポートクラスは、ビルダーとオブジェクト指向の設計パターンに従って LLM を作成します。各ハンドラー (
bedrock_handler.pyなど) は、まず client を作成し、必要な環境変数について環境をチェックしてから、get_modelメソッドを呼び出して LangChain LLM クラスを取得します。その後、生成メソッドが呼び出されて LLM が起動し、その応答を取得します。LangChain は現在 Amazon Bedrock のストリーミング機能をサポートしていますが、SageMaker AI はサポートしていません。ストリーミング機能または非ストリーミング機能に基づいて、適切な WebSocket ハンドラー (WebsocketStreamingCallbackHandlerまたはWebsocketHandler) が呼び出され、post_to_connectionメソッドを使用して応答が WebSocket 接続に送り返されます。clients/builderフォルダには、ビルダーパターンを使用して LLM ビルダーを構築するのに役立つクラスが含まれています。まず、DynamoDB の設定ストアからuse_case_configが取得されます。このストアには、構築するナレッジベース、会話メモリ、モデルのタイプに関する詳細が格納されています。また、モデルパラメータやプロンプトなど、関連するモデルの詳細も含まれています。ビルダーは、ナレッジベースの作成、会話コンテキストを維持するための LLM 用会話メモリの作成、ストリーミングケースと非ストリーミングケースに応じた LangChain コールバックの設定、提供されたモデル設定に基づく LLM モデルの作成の手順を支援します。この DynamoDB 設定は、デプロイダッシュボードからユースケースをデプロイするとき (またはデプロイダッシュボードなしでスタンドアロンのユースケーススタックデプロイでユーザーによって提供されるとき) に、ユースケースの作成時に保存されます。clients/factoriesサブフォルダには、LLM の設定に基づいて適切な会話メモリとナレッジベースクラスを設定するのに役立ちます。これにより、実装でサポートする他のナレッジベースやメモリタイプへの拡張が容易になります。sharedサブフォルダには、ビルダーがファクトリー内でインスタンス化するナレッジベースと会話メモリの具体的な実装が含まれています。また、RAG ユースケースでのドキュメント取得のために、LangChain 内で呼び出される Amazon Kendra および Amazon Bedrock ナレッジベース用のリトリーバーのほか、LangChain LLM モデルで使用されるコールバックも含まれています。LangChain の実装では、会話チェーンを構成するために LangChain 式言語 (LCEL) を使用してします。
RunnableWithMessageHistoryクラスは、カスタム LCEL チェーンを使用して会話履歴を維持するために使われます。これにより、例えばソースドキュメントを返したり、ナレッジベースに送信されたリフレーズされた (または曖昧性の解消された) 質問を LLM も送信したりできます。カスタムプロバイダーの独自の実装を作成するには、次の方法があります。
-
bedrock_handler.pyファイルをコピーして独自のカスタムハンドラー (custom_handler.pyなど) を作成します。これにより、カスタムクライアント (CustomProviderClientなど。次のステップで指定します) が作成されます。 -
クライアントフォルダの
bedrock_client.pyをコピーし、名前をcustom_provider_client.py(またはCustomProviderなど、特定のモデルプロバイダー名に応じた名前) に変更します。その中のクラスにも適切な名前を付けます (LLMChatClientを継承するCustomProviderClientなど)。LLMChatClientが提供するメソッドを使用することも、独自の実装を作成してこれらをオーバーライドすることもできます。get_modelメソッドはCustomProviderBuilderをビルドし (次のステップを参照)、ビルダーステップを使用してチャットモデルを構築するconstruct_chat_modelメソッドを呼び出します。このメソッドは、ビルダーパターンの Director として機能します。 -
clients/builders/bedrock_builder.pyをコピーして名前をcustom_provider_builder.pyに変更し、その中のクラスの名前を LLMBuilder (llm_builder.py) を継承するCustomProviderBuilderに変更します。LLMBuilder が提供するメソッドを使用することも、独自の実装を作成してこれらをオーバーライドすることもできます。ビルダーの各ステップは、クライアントのconstruct_chat_modelメソッド内で順番に呼び出されます (例:set_model_defaults、set_knowledge_base、set_conversation_memoryなど)。set_llm_modelメソッドは、それ以前に呼び出されたメソッドによって設定されたすべての値を使用して、実際の LLM モデルを作成します。具体的には、RAG あり (CustomProviderRetrievalLLM) または RAG なし (CustomProviderLLM) の LLM を、DynamoDB に保存された LLM 設定から取得したrag_enabled variableに基づいて作成します。この設定は、
LLMChatClientクラスのretrieve_use_case_configメソッドで取得されます。 -
RAG ありと RAG なしのユースケースのどちらが必要かに基づいて、
CustomProviderLLMまたはCustomProviderRetrievalLLMをllm_modelsサブフォルダに実装します。これらのモデルを実装するために必要な機能の大部分は、RAG なしのユースケースではBaseLangChainModelクラスで、RAG ありのユースケースではRetrievalLLMクラスで提供されています。llm_models/bedrock.pyファイルをコピーし、独自のカスタムプロバイダーを参照する LangChain モデルを呼び出すために必要な変更を加えることができます。例えば、Amazon Bedrock では、ChatBedrockクラスを使用して LangChain を通じてチャットモデルを作成します。generate メソッドは、LangChain の LCEL チェーンを使用して LLM の応答を生成します。
また、
get_clean_model_paramsメソッドを使用して、LangChain やモデルの要件に合わせてモデルパラメータをサニタイズすることもできます。
-
サポートされている Strands ツールの拡張
このソリューションを使用すると、MCP サーバー、AI エージェント、およびマルチエージェントワークフローを構築およびデプロイできます。エージェントビルダーエクスペリエンスの中で、MCP サーバーをアタッチして、エージェントに追加の機能を提供できます。MCP サーバーに加えて、Strands
このソリューションには、すぐに使用できる以下の Strands ツールが事前設定されています。
-
現在の時刻 (デフォルトで有効)
-
計算ツール (デフォルトで有効)
-
環境
組み込みの Strands ツールが表示されている、エージェントビルダーウィザードの MCP サーバーとツールの選択

追加の Strands ツールを使用してエージェントを拡張するには、このセクションで説明されている 4 ステップのプロセスに従います。
ステップ 1: Strands ツールを検索する
使用可能な Strands ツール
例えば、Amazon Bedrock ナレッジベースの取得機能を追加するには、取得
ステップ 2: SSM パラメータを更新する
エージェントビルダーデプロイ UI でツールを使用できるようにするには、サポートされている Strands ツールを定義する AWS Systems Manager Parameter Store のパラメータを更新します。
-
AWS アカウントの AWS Systems Manager Parameter Store に移動します。
-
/gaab/<stack-name>/strands-toolsパラメータを見つけます。 -
次の JSON 構造を使用して、ツール設定を既存のリストの末尾に追加します。
{ "name": "Bedrock KB Retrieve", "description": "Retrieve information from Bedrock Knowledge Base", "value": "retrieve", "category": "AI", "isDefault": false }フィールド 説明 .name
エージェントビルダー UI に表示される表示名
説明
ツールの機能の簡単な説明
値
Strands ツールパッケージで定義されている正確なツール名
category
UI 内でツールをグループ化するための組織カテゴリ
isDefault
新しいエージェントに対してツールをデフォルトで有効にするかどうか
ステップ 3: 環境変数を設定する
多くの Strands ツールでは、設定に環境変数が必要です。変数は次の 2 つの方法で定義できます。
オプション 1: AgentCore Runtime での直接設定
必要な環境変数を使用して、Amazon Bedrock AgentCore Runtime でデプロイされたエージェントを直接更新します。
オプション 2: デプロイウィザードのモデルパラメータ
モデルパラメータセクションを使用して、エージェントビルダーウィザードのモデル選択ステップ中に環境変数を追加します。命名規則 ENV_<ALL_CAPS_TOOL_NAME>_<env_variable_name> に従う環境変数は、実行時にエージェントの実行環境に <env_variable_name> として自動的にロードされます。
例えば、次のようになります。
-
ENV_RETRIEVE_KNOWLEDGE_BASE_IDが になりますKNOWLEDGE_BASE_ID -
ENV_RETRIEVE_MIN_SCOREが になりますMIN_SCORE
ENV_RETRIEVE_KNOWLEDGE_BASE_ID 設定を示す高度なモデルパラメータセクション

必要な環境変数を特定するには、特定のツールのドキュメントまたはソースコードを参照してください。取得ツールについては、ソースコード
ステップ 4: IAM アクセス許可を追加する
AgentCore Runtime 実行ロールに必要な IAM アクセス許可を手動で追加して、エージェントがツールを使用できるようにします。
例えば、Amazon Bedrock ナレッジベースで取得ツールを使用するには、以下を行います。
-
使用中の AWS アカウントで IAM コンソールに移動します。
-
エージェントの AgentCore Runtime 実行ロールを見つけます。
-
以下のアクセス許可を追加します。
{ "Effect": "Allow", "Action": "bedrock:Retrieve", "Resource": "arn:aws:bedrock:region:account-id:knowledge-base/knowledge-base-id" }
AgentCore Runtime 実行ロールにアタッチされた StrandsRetrieveToolKBAccess ポリシーを示す IAM コンソール

どんな特定のアクセス許可が必要になるかは、ツールによって異なります。ツールのドキュメントと AWS のサービスドキュメントを参照して、適切な IAM アクセス許可を決定します。
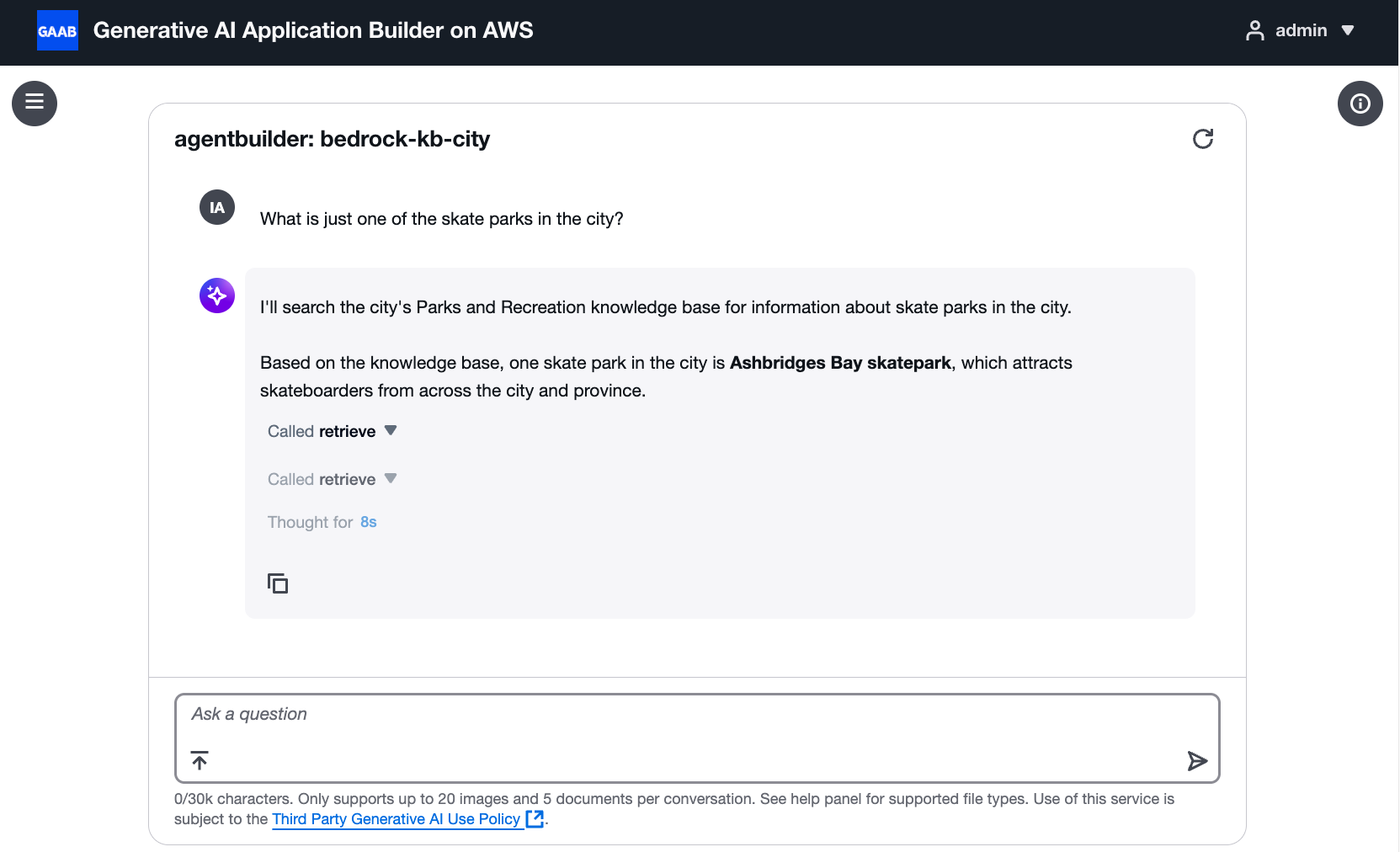
ステップ 5: エージェントをテストする
設定ステップを完了したら、エージェントをテストしてツールが正しく動作していることを確認します。エージェントの実行ログとレスポンスにツール呼び出しが表示されます。
エージェントが取得ツールを使用してスケートパークに関する質問に回答する
注記
利用可能な Strands ツールとその機能の完全なリストについては、「Strands コミュニティツールのドキュメント
サポートされているナレッジベースと会話メモリタイプの拡張
会話メモリまたはナレッジベースの実装を追加するには、shared フォルダに必要な実装を追加し、ファクトリーと適切な列挙を編集して、これらのクラスのインスタンスを作成します。
Parameter Store 内に保存されている LLM 設定を指定すると、LLM 用の適切な会話メモリとナレッジベースが作成されます。例えば、ConversationMemoryType を DynamoDB として指定すると、DynamoDBChatMessageHistory (shared_components/memory/ddb_enhanced_message_history.py 内で利用可能) のインスタンスが作成されます。KnowledgeBaseType が Amazon Kendra として指定されている場合、KendraKnowledgeBase (shared_components/knowledge/kendra_knowledge_base.py 内で利用可能) のインスタンスが作成されます。
コード変更のビルドとデプロイ
npm run build コマンドを使用してプログラムをビルドします。エラーが解決したら、cdk synth を実行してテンプレートファイルとすべての Lambda アセットを生成します。
-
–0—/stage-assets.shスクリプトを使用すると、生成されたアセットをアカウントのステージングバケットに手動でステージングできます。 -
次のコマンドを使用して、プラットフォームをデプロイまたは更新します。
cdk deploy DeploymentPlatformStack --parameters AdminUserEmail='admin-email@amazon.com'追加の AWS CloudFormation パラメータも AdminUserEmail パラメータとともに指定する必要があります。
