Amazon Redshift は、パッチ 198 以降、新しい Python UDF の作成をサポートしなくなります。既存の Python UDF は、2026 年 6 月 30 日まで引き続き機能します。詳細については、ブログ記事
データウェアハウスシステムのアーキテクチャ
このセクションでは、次の図で示すような、Amazon Redshift データウェアハウスアーキテクチャを構成するコンポーネントについて説明します。
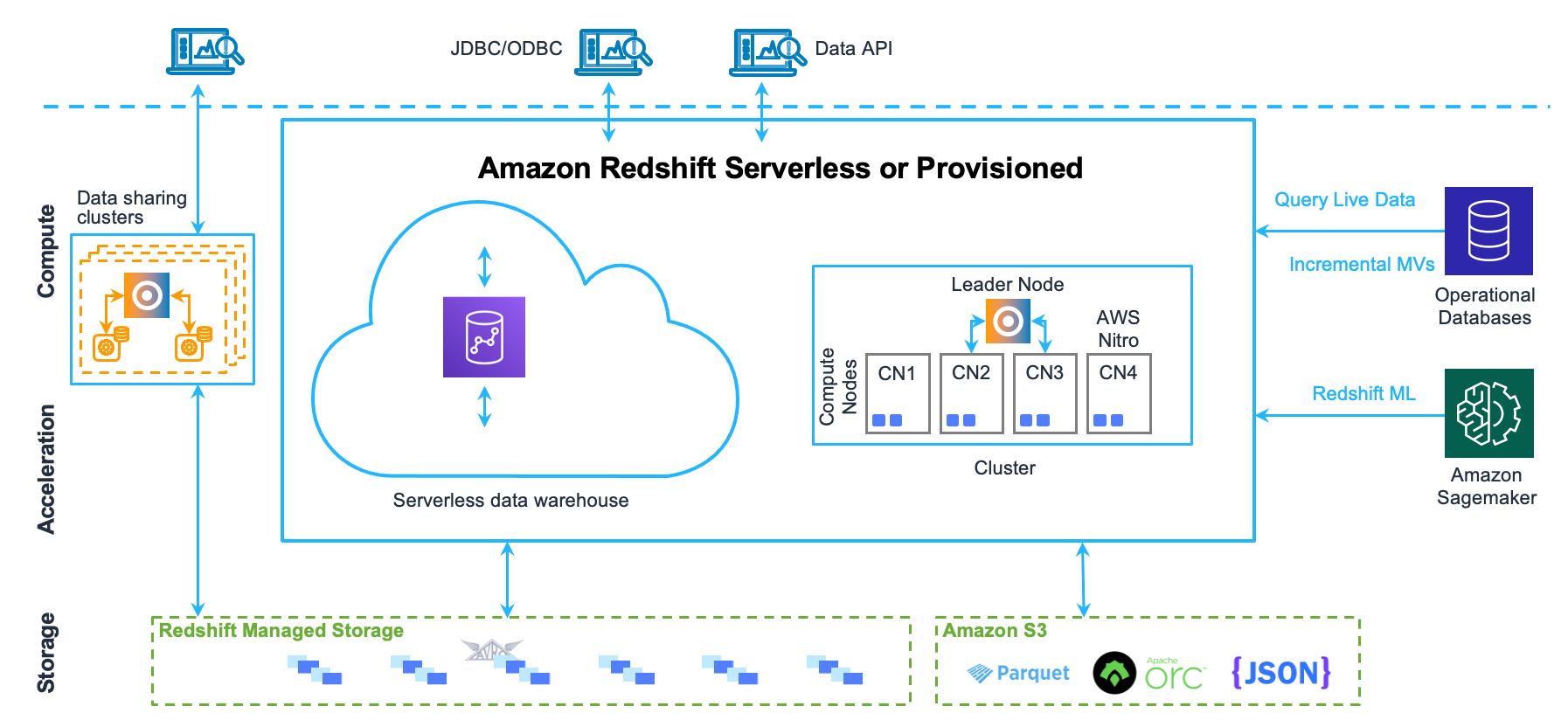
クライアントアプリケーション
Amazon Redshift は、さまざまなデータロードおよび ETL (抽出、変換、およびロード) ツールや、ビジネスインテリジェンス (BI) レポート、データマイニング、そして分析ツールなどと統合されています。Amazon Redshift はオープンスタンダードの PostgreSQL をベースにしているため、ほとんどの既存 SQL クライアントアプリケーションを、最小限の変更のみで動作させられます。Amazon Redshift SQL と PostgreSQL の間での重要な相違点については、「Amazon Redshift および PostgreSQL」を参照してください。
クラスター
Amazon Redshift データウェアハウスの中核となるインフラストラクチャコンポーネントは、クラスターです。
クラスターは、1 つまたは複数のコンピューティングノードで構成されます。クラスターが 2 つ以上のコンピューティングノードでプロビジョニングされている場合、追加のリーダーノードがコンピューティングノードを調整して、外部の通信を処理します。クライアントアプリケーションはリーダーノードとのみ直接通信します。コンピューティングノードは外部アプリケーションに対して透過的です。
リーダーノード
リーダーノードは、クライアントプログラムおよびコンピューティングノードとのすべての通信を管理します。リーダーノードは、データベース操作を遂行するための実行計画、特に複雑なクエリの結果を取得するために必要な一連の手順を解析および作成します。リーダーノードは、実行計画に基づいて、コードをコンパイルし、コンパイル済みのコードをコンピューティングノードに配布してから、データの一部分を各コンピューティングノードに割り当てます。
リーダーノードは、コンピューティングノードに格納されているテーブルがクエリで参照されている場合にのみ、コンピューティングノードに SQL ステートメントを配布します。他のすべてのクエリは、リーダーノードで排他的に実行されます。Amazon Redshift は、特定の SQL 機能をリーダーノードのみに実装するように設計されています。これらの機能を使用するクエリが、コンピューティングノードに存在するテーブルを参照する場合、エラーが返されます。詳細については、「リーダーノードでサポートされる SQL 関数」を参照してください。
コンピューティングノード
リーダーノードは、実行計画の個別要素のコードをコンパイルし、コードを個々のコンピューティングノードに割り当てます。コンピューティングノードは、コンパイル済みのコードを実行し、最終的な集計のために中間結果をリーダーノードに返送します。
各コンピューティングノードの専用 CPU およびメモリは、ノードのタイプによって異なります。ワークロードが増えるに従って、ノードの数を増やすかノードの種類をアップグレードして、または両方を行って、クラスターのコンピューティング能力を拡張できます。
Amazon Redshift には、コンピューティングのニーズに合わせて複数のノードタイプが用意されています。各ノードタイプの詳細については、「Amazon Redshift 管理ガイド」の「Amazon Redshift クラスター」を参照してください。
Redshift マネージドストレージ
データウェアハウスのデータは、Redshift マネージドストレージ (RMS) に保存されます。RMS では、Amazon S3 ストレージを使用してストレージをペタバイト規模にスケーリングできます。RMS では、コンピューティングとストレージを個別にスケールして料金を支払うことができるため、コンピューティングのニーズのみに基づいてクラスターのサイズを設定できます。高性能 SSD ベースのローカルストレージを Tier 1 キャッシュとして自動的に使用します。また、データブロックの温度、データブロックの有効期間、ワークロードパターンなどの最適化を利用し、操作を行わなくても必要に応じて自動的にストレージを Amazon S3 にスケーリングすることができます。
ノードスライス
コンピューティングノードはスライスに分割されています。各スライスは、ノードのメモリとディスク容量の一部を割り当てられ、ノードに割り当てられたワークロードの一部分を処理します。リーダーノードは、スライスへのデータの分散を管理し、クエリまたは他のデータベース操作のワークロードをスライスに分配します。スライスは、並列処理を行って操作を完了します。
ノードあたりのスライスの数は、クラスターのノードサイズによって決まります。各ノードサイズに含まれるスライス数の詳細については、「Amazon Redshift 管理ガイド」の「クラスターとノードについて」を参照してください。
テーブルを作成するときは、必要に応じて 1 つの列を分散キーとして指定できます。テーブルにデータがロードされるときは、テーブルに対して定義されている分散キーに従って行がノードスライスに分配されます。適切な分散キーを選択することにより、Amazon Redshift は並列処理を使用してデータのロードやクエリを効率的に実行できようになります。分散キーの選択については、「最適な分散スタイルの選択」を参照してください。
内部ネットワーク
Amazon Redshift は、高帯域幅接続、近接性、およびカスタム通信プロトコルを活用することで、リーダーノードとコンピューティングノードの間に、プライベートかつ非常に高速なネットワーク通信を実現します。コンピューティングノードは、クライアントアプリケーションが直接アクセスすることのない別の独立したネットワークで動作します。
データベース
クラスターは、1 つ以上のデータベースで構成されます。ユーザーデータはコンピューティングノードに格納されます。SQL クライアントはリーダーノードと通信し、リーダーノードはクエリの実行をコンピューティングノードと調整します。
Amazon Redshift はリレーショナルデータベース管理システム (RDBMS) なので、他の RDBMS アプリケーションとも互換性があります。Amazon Redshift は、標準的な RDBMS と同じ機能 (データの挿入や削除といったオンライントランザクション処理 (OLTP) 機能など) を提供しますが、この機能は、非常に大きいデータセットに関する高パフォーマンスの分析やレポート向けに最適化されています。
Amazon Redshift は PostgreSQL に基づいています。Amazon Redshift と PostgreSQL の間には非常に重要な相違点がいくつかあり、データウェアハウスアプリケーションの開発と設計の際には、それらを考慮に入れる必要があります。Amazon Redshift SQL と PostgreSQL の違いについては、「Amazon Redshift および PostgreSQL」 を参照してください。
