翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データ準備ステップ
Amazon Quick Sight のデータ準備エクスペリエンスには、データを体系的に変換できる 11 の強力なステップタイプが用意されています。各ステップは、データ準備ワークフローで特定の目的を果たします。
ステップは、設定ペインの直感的なインターフェイスを使用して設定でき、すぐにフィードバックがプレビューペインに表示されます。ステップを順番に組み合わせて、SQL の専門知識を必要とせずに高度なデータ変換を作成できます。
各ステップは、物理テーブルまたは前のステップの出力から入力を受け取ることができます。ほとんどのステップは 1 つの入力を受け入れ、追加ステップと結合ステップは例外です。これらには 2 つの入力のみが必要です。
Input
入力ステップは、後続のステップで変換のために複数のソースからデータを選択してインポートできるようにすることで、Quick Sight でデータ準備ワークフローを開始します。
入力オプション
-
データセットの追加
既存の Quick Sight データセットを入力ソースとして活用し、チームが既に準備して最適化したデータを構築します。
-
データソースの追加
特定のデータベースオブジェクトを選択し、接続パラメータを指定して、Amazon Redshift、Athena、RDS、またはその他のサポートされているソースなどのデータベースに直接接続します。
-
ファイルのアップロードを追加する
CSV、TSV、Excel、JSON などの形式でローカルファイルから直接データをインポートします。
設定
入力ステップには設定は必要ありません。プレビューペインには、インポートしたデータと、接続の詳細、テーブル名、列メタデータなどのソース情報が表示されます。
使用に関する注意事項
-
1 つのワークフロー内に複数の入力ステップが存在する場合があります。
-
ワークフローの任意の時点で入力ステップを追加できます。
計算列の追加
計算列の追加ステップでは、既存の列に対して計算を実行する行レベルの式を使用して新しい列を作成できます。スカラー (行レベル) 関数と演算子を使用して新しい列を作成し、既存の列を参照する行レベルの計算を適用できます。
設定
計算列の追加ステップを設定するには、設定ペインで次の操作を行います。
使用に関する注意事項
-
このステップでは、スカラー (行レベル) 計算のみがサポートされています。
-
SPICE では、計算された列がマテリアライズされ、後続のステップで標準列として機能します。
データ型を変更する
Quick Sight は、、date、decimal、および の 4 つの抽象データ型をサポートすることでinteger、データ型管理を簡素化しますstring。これらの抽象型は、さまざまなソースデータ型を Quick Sight の同等のデータ型に自動的にマッピングすることで、複雑さを排除します。たとえば、tinyint、smallint、、 bigintはすべて にマッピングintegerされinteger、date、datetime、 timestampはすべて にマッピングされますdate。
この抽象化は、Quick Sight がさまざまなデータソースを操作するときに基盤となるすべてのデータ型の変換と計算を自動的に処理するため、Quick Sight の 4 つのデータ型を理解するだけで済みます。
設定
データ型の変更ステップを設定するには、設定ペインで次の操作を行います。
-
変換する列を選択します。
-
ターゲットデータ型 (
string、integer、decimal、または ) を選択しますdate。 -
日付変換では、入力形式に基づいて形式設定とプレビュー結果を指定します。Quick Sight でサポートされている日付形式を参照してください。
-
必要に応じて変換する列を追加します。
使用に関する注意事項
-
効率を高めるために、1 つのステップで複数の列のデータ型を変換します。
-
SPICE を使用する場合、すべてのデータ型の変更はインポートされたデータにマテリアライズされます。
列の名前を変更する
列の名前変更ステップを使用すると、よりわかりやすく、ユーザーフレンドリで、組織の命名規則と一致するように列名を変更できます。
設定
列の名前変更ステップを設定するには、設定ペインで次の操作を行います。
-
名前を付ける列を選択します。
-
選択した列の新しい名前を入力します。
-
必要に応じて名前を変更する列を追加します。
使用に関する注意事項
-
すべての列名はデータセット内で一意である必要があります。
列の選択
列の選択ステップを使用すると、列を含めたり、除外したり、列の順序を変更したりして、データセットを合理化できます。これにより、不要な列を削除し、分析のために残りの列を論理シーケンスに整理することで、データ構造を最適化できます。
設定
列の選択ステップを設定するには、設定ペインで以下を行います。
-
出力に含める特定の列を選択します。
-
任意の順序で列を選択してシーケンスを確立します。
-
Select All を使用して、残りの列を元の順序で含めます。
-
選択しないままにして、不要な列を除外します。
主な機能
-
出力列は、選択順に表示されます。
-
すべて を選択すると、元の列シーケンスが保持されます。
使用に関する注意事項
-
選択されていない列は、後続のステップから削除されます。
-
不要な列を削除してデータセットのサイズを最適化します。
Append
追加ステップは、SQL UNION ALL オペレーションと同様に、2 つのテーブルを垂直に組み合わせます。Quick Sight は、列の順序や列数が異なる場合でも、列をシーケンスではなく名前で自動的に照合するため、効率的なデータ統合が可能になります。
設定
追加ステップを設定するには、設定ペインで以下を行います。
-
追加する入力テーブルを 2 つ選択します。
-
出力列のシーケンスを確認します。
-
どちらの列が両方のテーブルに存在するか、または単一のテーブルに存在するかを調べます。
主な特徴
-
列をシーケンスではなく名前で一致させます。
-
重複を含む両方のテーブルのすべての行を保持します。
-
列数が異なるテーブルをサポートします。
-
一致する列のテーブル 1 の列シーケンスに従い、テーブル 2 から一意の列を追加します。
-
すべての列の明確なソースインジケータを表示します
使用に関する注意事項
-
異なる名前の列を追加するときは、まず名前変更ステップを使用します。
-
各追加ステップは 2 つのテーブルのみを組み合わせます。追加の追加ステップを使用してテーブルを増やします。
結合
Join ステップは、指定された列の一致する値に基づいて、2 つのテーブルのデータを水平に組み合わせます。Quick Sight は、左外部、右外部、フル外部、および内部結合タイプをサポートしており、分析ニーズに合わせて柔軟なオプションを提供します。ステップには、重複する列名を自動的に処理するインテリジェントな列競合解決が含まれています。自己結合は特定の結合タイプとしては使用できませんが、ワークフローの相違を使用して同様の結果を得ることができます。
設定
結合ステップを設定するには、設定ペインで次の操作を行います。
-
結合する 2 つの入力テーブルを選択します。
-
結合タイプ (左外部、右外部、完全外部、または内部) を選択します。
-
各テーブルから結合キーを指定します。
-
自動解決された列名の競合を確認します。
主な特徴
-
さまざまな分析ニーズに合わせて複数の結合タイプをサポートします。
-
重複する列名を自動的に解決します。
-
計算された列を結合キーとして受け入れます。
使用に関する注意事項
-
結合キーには互換性のあるデータ型が必要です。必要に応じてデータ型の変更ステップを使用します。
-
各結合ステップは 2 つのテーブルのみを結合します。より多くのテーブルには追加の結合ステップを使用します。
-
結合後に名前変更ステップを作成して、自動解決された列ヘッダーをカスタマイズします。
集計
集計ステップでは、列をグループ化して集計オペレーションを適用することで、データを要約できます。この強力な変換により、詳細なデータが、指定したディメンションに基づいて意味のある概要に集約されます。Quick Sight は、直感的なインターフェイスを通じて複雑な SQL オペレーションを簡素化し、 ListAggや などの高度な文字列オペレーションを含む包括的な集計関数を提供しますListAgg distinct。
設定
集約ステップを設定するには、設定ペインで以下を行います。
-
グループ化する列を選択します。
-
メジャー列の集計関数を選択します。
-
出力列名をカスタマイズします。
-
ListAggおよびListAgg distinct用-
集計する列を選択します。
-
区切り文字 (カンマ、ダッシュ、セミコロン、または垂直線) を選択します。
-
-
要約されたデータをプレビューします。
データ型ごとにサポートされている関数
| データタイプ | サポートされている関数 |
|---|---|
|
数値 |
|
|
日付 |
|
|
文字列 |
|
主な特徴
-
同じステップ内の列に異なる集計関数を適用します。
-
集計関数なしでグループ化すると、SQL SELECT DISTINCT として機能します。
-
ListAggはすべての値を連結します。ListAgg distinctには一意の値のみが含まれます。 -
ListAgg関数は、デフォルトで昇順のソート順序を維持します。
使用に関する注意事項
-
集約により、データセットの行数が大幅に減少します。
-
ListAggと はdate値ListAgg distinctをサポートしますが、 はサポートしませんdatetime。 -
区切り文字を使用して文字列連結出力をカスタマイズします。
フィルター
フィルターステップでは、特定の基準を満たす行のみを含めることで、データセットを絞り込むことができます。1 つのステップで複数のフィルター条件を適用できます。すべてANDロジックを組み合わせて、関連するデータに分析を集中させることができます。
設定
フィルターステップを設定するには、設定ペインで次の操作を行います。
-
フィルタリングする列を選択します。
-
比較演算子を選択します。
-
列のデータ型に基づいてフィルター値を指定します。
-
必要に応じて、異なる列にフィルター条件を追加します。
注記
-
「is in」または「is not in」を含む文字列フィルター: 複数の値 (1 行に 1 つずつ) を入力します。
-
数値フィルターと日付フィルター: 単一の値を入力します (2 つの値を必要とする「間」を除く)。
データ型ごとにサポートされている演算子
| データタイプ | サポートされている演算子 |
|---|---|
|
整数と 10 進数 |
等しい、等しくない より大きい、より小さい 以上、以下 の間 |
|
日付 |
After、Before の間 Is after or equal to、Is before or equal to |
|
文字列 |
等しい、等しくない で始まる、で終わる 含まれる、含まれない Is in、 Is not in |
使用に関する注意事項
-
1 つのステップで複数のフィルター条件を適用します。
-
さまざまなデータ型に条件を混在させます。
-
フィルタリングされた結果をリアルタイムでプレビューします。
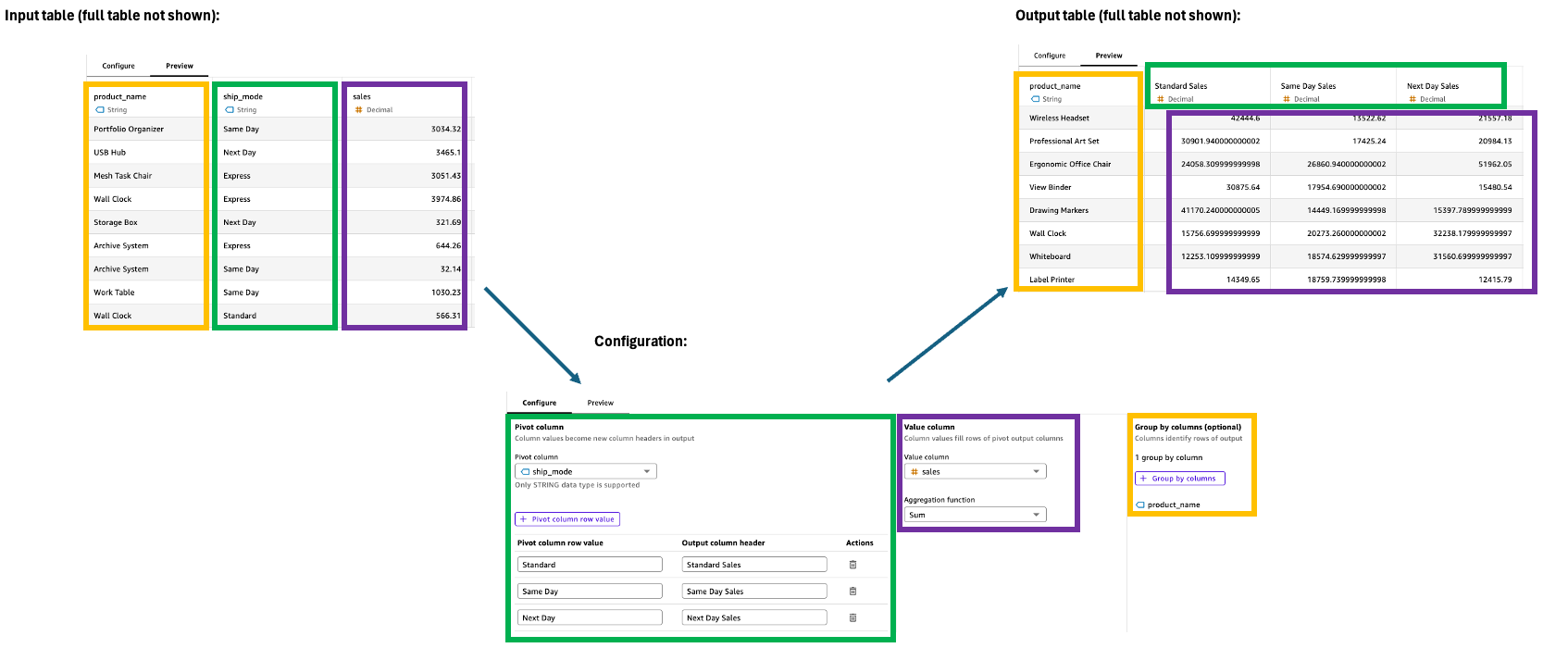
[Pivot] (ピボット)
ピボットステップは行値を一意の列に変換し、データを長い形式から広い形式に変換して、比較と分析を容易にします。この変換では、出力列を効果的に管理するために、値のフィルタリング、集約、グループ化の仕様が必要です。
設定
ピボットステップを設定するには、設定ペインで以下を使用します。
-
ピボット列: 値が列ヘッダーになる列 (Category など) を選択します。
-
ピボット列の行値: 含める特定の値をフィルタリングします (テクノロジー、オフィス用品など)。
-
出力列ヘッダー: 新しい列ヘッダーをカスタマイズします (デフォルトではピボット列値)。
-
値列: 集計する列を選択します (例: Sales)。
-
集計関数: 集計方法 (Sum など) を選択します。
-
グループ化基準: 列の整理 (セグメントなど) を指定します。
データ型ごとにサポートされている演算子
| データタイプ | サポートされている演算子 |
|---|---|
|
整数と 10 進数 |
|
|
日付 |
|
|
文字列 |
|
使用に関する注意事項
-
ピボットされた各列には、値列から集計された値が含まれます。
-
わかりやすいように列ヘッダーをカスタマイズします。
-
変換をプレビューすると、リアルタイムになります。
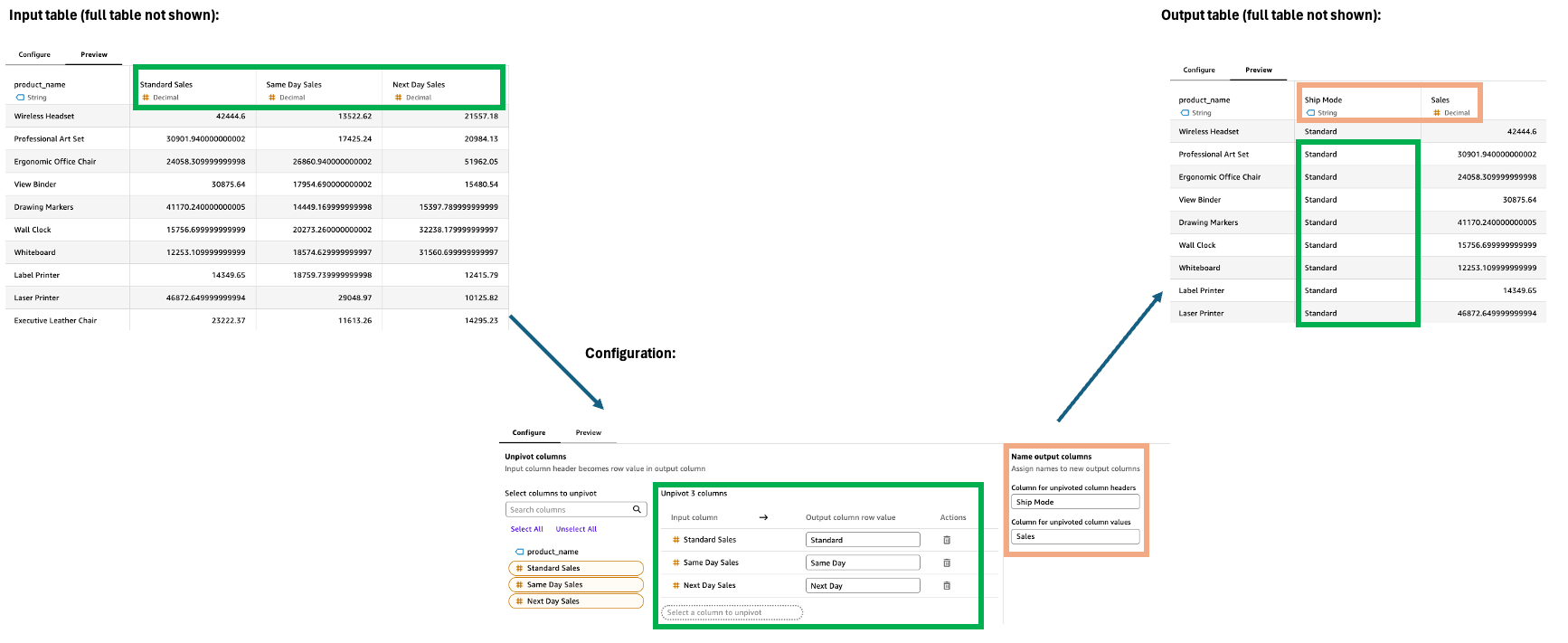
ピボット解除
Unpivot ステップは列を行に変換し、幅の広いデータをより長く狭い形式に変換します。この変換により、複数の列にまたがるデータをより構造化された形式に整理できるため、分析と視覚化が容易になります。
設定
Unpivot ステップを設定するには、設定ペインで次の操作を行います。
-
行にピボットを解除する列を選択します。
-
出力列の行値を定義します。デフォルトは元の列名です。例としては、テクノロジー、オフィス用品、家具などがあります。
-
2 つの新しい出力列に名前を付けます。
-
ピボットされていない列ヘッダー: 以前の列名の名前 (カテゴリなど)
-
ピボットされていない列値: ピボットされていない値の名前 (例: Sales)
-
主な特徴
-
ピボットされていないすべての列を出力に保持します。
-
2 つの新しい列を自動的に作成します。1 つは以前の列名用、もう 1 つは対応する値用です。
-
幅広いデータを長い形式に変換します。
使用に関する注意事項
-
ピボットされていないすべての列には、互換性のあるデータ型が必要です。
-
行数は通常、ピボット解除後に増加します。
-
変更を適用する前に、リアルタイムで変更をプレビューします。
