翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
高度なワークフロー機能
Amazon Quick Sight のデータ準備エクスペリエンスは、複雑で再利用可能なデータ変換を作成する機能を強化する高度な機能を提供します。このセクションでは、ワークフローの可能性を広げる 2 つの強力な機能について説明します。
分散を使用すると、1 つのステップから複数の変換パスを作成し、後で再結合できる並列処理ストリームを作成できます。この機能は、自己結合や並列変換などの複雑なシナリオに特に役立ちます。
複合データセットを使用すると、既存のデータセットを構成要素として使用して階層データ構造を構築できます。この機能は、チーム間のコラボレーションを促進し、再利用可能なレイヤード変換を通じて一貫したビジネスロジックを確保します。
これらの機能は連携して、柔軟なワークフロー設計、チームコラボレーションの強化、再利用可能なデータ変換を提供します。これにより、データリネージが明確になり、スケーラブルなデータ準備ソリューションが可能になり、組織がますます複雑になるデータシナリオを効率的かつ明確に処理できるようになります。
分散
分散を使用すると、ワークフローの 1 つのステップから複数の並列変換パスを作成できます。これらのパスは個別に変換でき、後で再結合できるため、自己結合などの複雑なデータ準備シナリオが可能になります。
異なるパスの作成
分散を開始するには、ワークフローで次の操作を行います。
-
発散を作成するステップを選択します。
-
表示される + アイコンを選択します。
-
表示される新しいブランチを設定します。
-
必要な変換を各パスに適用します。
-
結合または追加ステップを使用して、パスを 1 つの出力に再結合します。
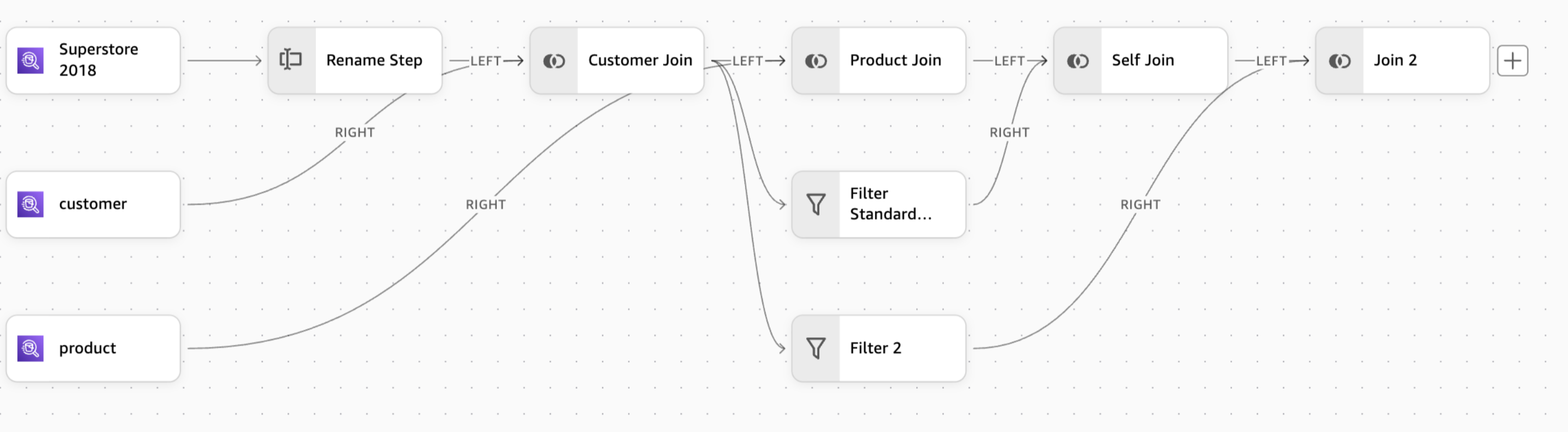
主な特徴
-
1 つのステップから最大 5 つの異なるパスを作成します。
-
各パスに異なる変換を適用します。
-
結合または追加ステップを使用してパスを再結合します。
-
各パスの変更を個別にプレビューします。
ベストプラクティス
-
自己結合の実装には相違を使用します。
-
並列変換用のデータコピーを作成します。
-
再結合戦略 (参加または追加) を計画します。
-
ワークフローの可視性を向上させるために、明確なパスの命名を維持します。
複合データセット
Composite Datasets を使用すると、既存のデータセットに基づいて構築し、組織全体で共有および再利用できる階層データ変換構造を作成できます。Quick Sight は、SPICE モードと Direct Query モードの両方で最大 10 レベルの複合データセットをサポートします。
複合データセットの作成
複合データセットを作成するには、ワークフローで次の操作を行います。
-
新しいデータセットを作成するときに入力ステップを選択します。
-
データの追加で、ソースとしてデータセットを選択します。
-
構築する既存のデータセットを選択します。
-
必要に応じて追加の変換を適用します。
-
新しいデータセットとして保存します。
主な特徴
-
階層データ変換構造を構築します。
-
最大 10 レベルのデータセットネストをサポートします。
-
SPICE と Direct Query の両方と互換性があります。
-
明確なデータリネージを維持します。
-
チーム固有の変換を有効にします。
この機能は、さまざまなチーム間のコラボレーションを強化します。例えば、
| ロール | Action | Output |
|---|---|---|
|
グローバルアナリスト |
グローバルビジネスロジックを使用してデータセットを作成します |
データセット A |
|
南北アメリカアナリスト |
データセット A を使用し、リージョンロジックを追加します |
データセット B |
|
米国西部アナリスト |
データセット B を使用し、ローカルロジックを追加します |
データセット C |
この階層的アプローチは、変換レイヤーの明確な所有権を割り当てることで、組織全体で一貫したビジネスロジックを促進します。最大 10 レベルのデータセットネストをサポートしながら、追跡可能なデータ系統を作成し、制御された体系的なデータ変換管理を可能にします。
ベストプラクティス
-
各変換レイヤーに明確な所有権を確立します。
-
データセットの関係と依存関係を文書化します。
-
ビジネスニーズに基づいて階層の深さを計画します。
-
一貫した命名規則を維持します。
-
アップストリームデータセットを慎重に確認および更新します。
