rank
rank 関数は、指定されたパーティションと比較したメジャーまたはディメンションのランクを計算します。各項目を重複も含めて 1 回ずつカウントし、重複した値を埋め合わせるために「穴あき」ランクを割り当てます。
構文
括弧が必要です。省略可能な引数については、次の説明を参照してください。
rank ([ sort_order_field ASC_or_DESC, ... ],[ partition_field, ... ])
引数
- sort order field
-
データをソートする 1 つ以上の集計されたメジャーおよびディメンション。コンマで区切って入力します。昇順 (
ASC) または降順 (DESC) のソート順を指定できます。複数の単語の場合は、リスト内の各フィールドを {} (中括弧) で囲みます。リスト全体は [ ] (角括弧) で囲まれます。
- partition field
-
(省略可能) パーティション分割する 1 つ以上のメジャーおよびディメンション。コンマで区切って入力します。
複数の単語の場合は、リスト内の各フィールドを {} (中括弧) で囲みます。リスト全体は [ ] (角括弧) で囲まれます。
- calculation level
-
(オプション)使用する計算レベルを指定します。
-
PRE_FILTER- 事前フィルター計算は、データセットフィルターの前に計算されます。 -
PRE_AGG- 事前集計計算は、集計と上位および下位の N フィルターをビジュアルに適用する前に計算されます。 -
POST_AGG_FILTER- (デフォルト) テーブルの計算は、ビジュアルが表示されるときに処理されます。
空白の場合、この値はデフォルトで
POST_AGG_FILTERです。詳細については、「Amazon QuickSight でのレベルアウェア計算の使用」 を参照してください。 -
例
次の例では、max(Sales) をランク付けします。State の City 内で、State および WA でソートし、順序は降順です。同じ max(Sales) の都市には同じランクが割り当てられますが、次のランクには前に存在するすべてのランクのカウントが含まれます。たとえば、3 つの都市が同じランクの場合、4 番目の都市は 4 位とランク付けされます。
rank ( [max(Sales) DESC], [State, City] )
次の例では、max(Sales) をランク付けします。State でソートし、順序は昇順です。同じ max(Sales) の州には同じランクが割り当てられますが、次のランクには前に存在するすべてのランクのカウントが含まれます。たとえば、3 つの州が同じランクの場合、4 番目の州は 4 位とランク付けされます。
rank ( [max(Sales) ASC], [State] )
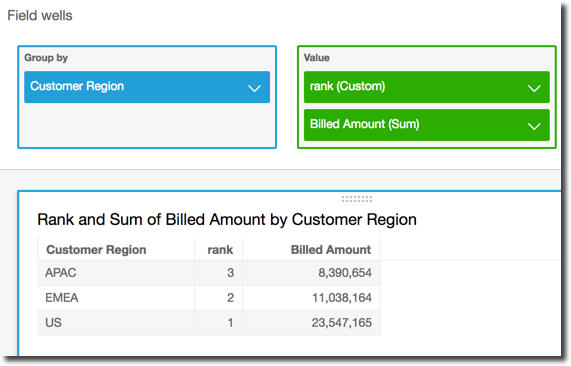
次の例では、合計 Customer Region で Billed
Amount をランク付けします。テーブル計算のフィールドは、ビジュアルのフィールドウェルにあります。
rank( [sum({Billed Amount}) DESC] )
次のスクリーンショットは、例の結果とともに合計 Billed Amount を示しています。これにより、各リージョンのランクを確認できます。