翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
研究コンピューティングにおけるクラウドでのバースト
米国の R1 (博士課程大学 – 研究活動が非常に活発) に分類される研究機関の研究コンピューティンググループは、長年にわたり、Slurm スケジューラを使用してオンプレミスのハイパフォーマンスコンピューティング (HPC) クラスターを運用していました。数週間の定期メンテナンスを除き、クラスターは 80~95% の使用率で稼働しており、ほとんどのキューが満杯でした。
機関での研究活動の増加により、容量と処理能力の課題が生じていました。特定のキューでは、数人の著名な研究者が常に長時間実行されるシミュレーションを実行していたため、他のユーザーの待機時間が長くなっていました。新たに採用された教員は、気象予測用の新しい人工知能と機械学習 (AI/ML) モデルを構築するために多数の気象シミュレーションを実行する必要がありましたが、利用可能な容量よりも多くの容量を必要としていました。研究コンピューティンググループには、機械学習モデルのトレーニングに使用する最新のグラフィックス処理ユニット (GPU) に対するリクエストも増加していました。新しい GPU の資金は確保されていても、チームは、データセンター内のラックスペースを拡張するための承認を得るまでに、数か月待たなければなりませんでした。
多くの研究者が古いデータを削除したがらなかったため、ローカルストレージの容量も課題となっていました。オンプレミスの貴重な高性能ストレージを解放するには、よりスケーラブルで長期的なストレージオプションが必要でした。
クラウドは、オンプレミスの容量が不足している場合に研究コンピューティングをクラウドにバーストできる、ハイブリッドなコンピューティングおよびストレージソリューションによって、これらの課題に対処します。次のアーキテクチャ図は、AWS ParallelCluster
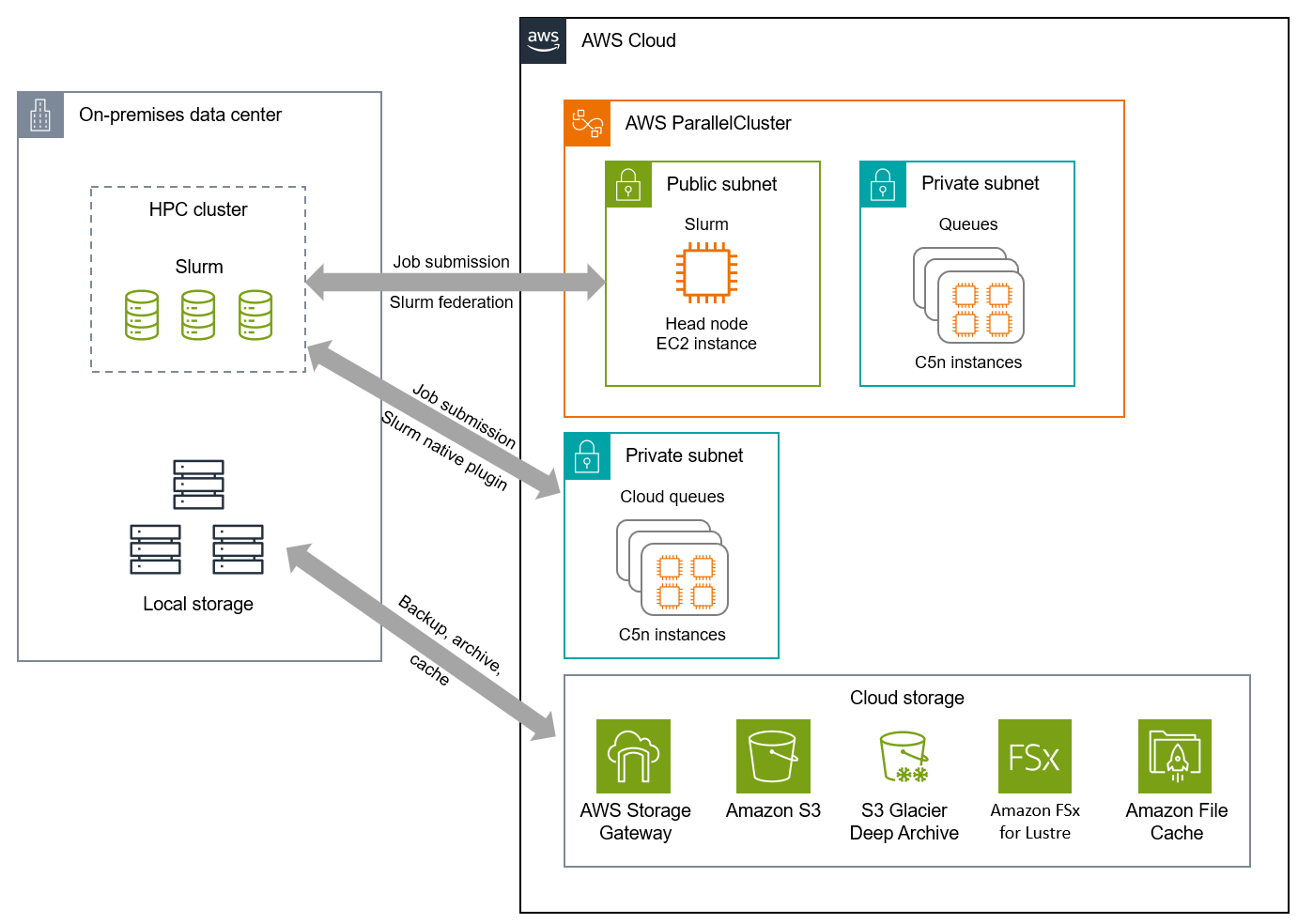
このアーキテクチャは、次の推奨事項に従います。
-
プライマリの戦略的クラウドプロバイダーを選択します。このアーキテクチャでは、最小公分母アプローチによる制約を回避するために、1 つのプライマリクラウドプロバイダーを使用します。これにより、プライマリクラウドプロバイダーが提供するイノベーションやネイティブなコンピューティングおよびストレージサービスを活用できます。研究コンピューティングチームは、異なるクラウド環境での対応方法ではなく、プライマリクラウドプロバイダーが提供する環境におけるワークロードの最適化に集中できます。
-
各クラウドサービスプロバイダーのセキュリティとガバナンスの要件を確立します。このアーキテクチャで使用される各サービスとツールは、プライベート接続、転送中および保管中のデータ暗号化、アクティビティのログ記録など、研究コンピューティングチームのセキュリティおよびガバナンス要件を満たすように設定できます。
-
可能な限り、かつ実用的であれば、クラウドネイティブのマネージドサービスを採用します。このアーキテクチャでは、マネージド型のストレージおよびコンピューティングサービスに加えて、クラスター管理を簡素化するツールを使用できます。これにより、研究コンピューティングチームは、クラスターや基盤となるインフラストラクチャを自分たちで管理する必要がなくなり、こうした管理の複雑さや時間的負担から解放されます。
-
既存のオンプレミス投資が継続利用を促す場合は、ハイブリッドアーキテクチャを実装します。このアーキテクチャにより、機関はオンプレミスのリソースを引き続き使用しながら、クラウドを活用して容量を増やし、必要に応じてコンピューティング能力を増強できます。クラウドを利用することで、コンピューティングタイプを適切なサイズにして価格パフォーマンスを最大化し、追加のオンプレミスハードウェアに多額の先行投資を行うことなく、最新のテクノロジーを活用してイノベーションを促進できます。
