翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データ圧縮の設定
EnterpriseOne のビジネスデータおよびコントロールテーブルのテーブルとインデックスは、ページ圧縮または行圧縮を使用して圧縮できます。のほとんどの EnterpriseOne ワークロードはページ圧縮で最高のパフォーマンス AWS を発揮しますが、非常に大きなワークロード (非圧縮テラバイト数) は行圧縮でパフォーマンスが向上する可能性があります。ページ圧縮と行圧縮の詳細な説明は、このガイドの範囲外です。このセクションでは、主にページ圧縮に焦点を当てています。
通常の EnterpriseOne のワークロードで圧縮を有効にすると、CPU 使用率の増加が最小限に抑えられ、システム全体のパフォーマンスに大きなメリットがあります。この利点は次の点で測定できます。
-
データが圧縮形式でディスクに保存されるため、データベースのサイズとストレージ要件が小さくなります。
-
圧縮によりバッファキャッシュが保持できるデータ量が増えるため、バッファキャッシュのヒット率が高くなります。
-
各 I/O オペレーションがより多くのデータを返すため、必要な Amazon EBS IOPS とスループットが低下します。また、バッファキャッシュはより効率的なため、必要なオペレーションも少なくて済みます。
-
バックアッププロセス全体を通してデータが圧縮されたままになるため、バックアップが高速化されます。
圧縮は、テーブルごとに個別に有効にすることも、インデックスのみで有効にすることもできます。圧縮のタイプ (ページまたは行) をテーブルごと、またはインデックスごとに選択できます。F0002 (次の番号) テーブルや F0902 (口座残高) テーブルなど、定期的に更新されるテーブルは圧縮しないほうが有利な場合があります。オブジェクトごとの分析を必要とせずにほとんどの利点を得られるため、多くの場合、すべてのテーブルとインデックスの圧縮を有効にすることは最も簡単なソリューションです。このガイドのステップでは、ページ圧縮を使用してすべてのテーブルとインデックスを圧縮します。
場合によっては、特にサードパーティシステムが JD Edwards データベースに直接アクセスしてテーブルとインデックスのスキャンオペレーションを実行する場合に、圧縮によってパフォーマンスが低下することがあります。通常、この低下はクエリのパフォーマンスが低いことが原因です。このような場合は、遅いクエリを見直し、一般的な最適化の手法を使用してパフォーマンスを改善してください。例えば、クエリを書き直して既存のインデックスを使用するか、新しいインデックスを作成することを検討してください。
圧縮の有効化は、複数ステップのプロセスです。これらのステップの多くは、データベースオブジェクトへの排他的アクセスを必要とするため、EnterpriseOne やその他のシステムをオフラインにする必要があります。DTA スキーマと CTL スキーマのすべてのテーブルとインデックスでページ圧縮を有効にするには、以下のハイレベルステップに従ってください。
圧縮前にディスクスペース使用率をチェックする
データベースの現在のディスクスペース使用率をチェックするには、次のスクリプトを実行します。
USE JDE_PRIST920 SELECT DB_NAME() AS DbName, type_desc, CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS SpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'; SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS TotalSpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'
出力は次の例のようになります:
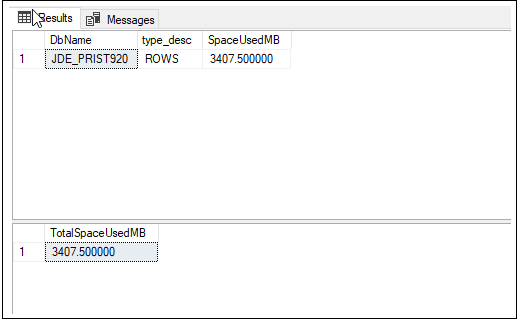
この例では、テーブル行が 3,407 MB のディスクスペースを占めています。
列挙スクリプトを実行します。
EnterpriseOne データベースには大量のテーブルとインデックスがあるため、スクリプトを使用して圧縮するオブジェクトを列挙します。列挙スクリプトの出力は、次のセクションで使用される圧縮スクリプトです。次のスクリプトを実行する前に、圧縮するテーブルとインデックスの所有者を反映するようにスキーマの所有者名を更新します。
declare @tblname as varchar(100) declare @idxname as varchar(100) declare @schemaname as varchar(100) declare @sqlstatement as varchar(512) declare tblcurs CURSOR for select t.name as tblname, s.name as schemaname from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id inner join sys.partitions p on i.object_id = p.object_id AND i.index_id = p.index_id where s.name in ('PS920DTA', 'PS920CTL') and i.type_desc='CLUSTERED' and p.data_compression_desc <> 'PAGE' open tblcurs FETCH next from tblcurs into @tblname, @schemaname while @@FETCH_STATUS = 0 begin FETCH next from tblcurs into @tblname, @schemaname set @sqlstatement = 'alter table ' + @schemaname + '.' + @tblname + ' rebuild with (DATA_COMPRESSION = PAGE)' print @sqlstatement end close tblcurs deallocate tblcurs declare idxcurs CURSOR for select i.name as idxname, t.name as tblname, s.name as schemaname from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id inner jOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id where s.name in ('PS920DTA', 'PS920CTL') and p.data_compression_desc <> 'PAGE' and i.type_desc='NONCLUSTERED' and i.name is not null open idxcurs FETCH next from idxcurs into @idxname, @tblname, @schemaname while @@FETCH_STATUS = 0 begin FETCH next from idxcurs into @idxname, @tblname, @schemaname set @sqlstatement = 'alter index ' + @idxname + ' on ' + @schemaname + '.' + @tblname + ' rebuild with (DATA_COMPRESSION = PAGE)' print @sqlstatement end close idxcurs deallocate idxcurs
圧縮スクリプトを実行する
前のセクションで実行した列挙スクリプトの出力を確認してください。この圧縮スクリプトを小さなスクリプトに分割して、個別に実行することも、並列で実行することもできます。
重要
EnterpriseOne データベースに対してこのスクリプトを実行するときは、EnterpriseOne システムがオフラインであることを確認してください。
圧縮スクリプトの例を示します。
alter table PS920DTA.F07620 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F760404A rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F31B93Z1 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F31B65 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F47156 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F74F210 rebuild with (DATA_COMPRESSION = PAGE) ... alter index F4611_16 on PS920DTA.F4611 rebuild with (DATA_COMPRESSION = PAGE) alter index F4611_17 on PS920DTA.F4611 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_PK on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_3 on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_4 on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F76A801T_PK on PS920DTA.F76A801T rebuild with (DATA_COMPRESSION = PAGE) ...
圧縮後のディスクスペース使用率をチェックする
圧縮後のデータベースの現在のディスクスペース使用率をチェックするには、次のスクリプトを実行します。
USE JDE_PRIST920 SELECT DB_NAME() AS DbName, type_desc, CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS SpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'; SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS TotalSpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'
出力は以下のようになります。
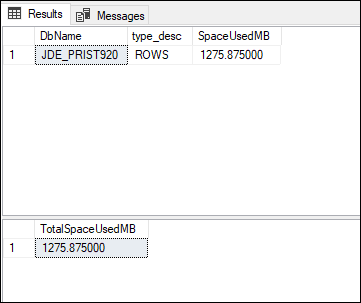
この例では、スペースの使用容量が 3,407 MB から 1,275 MB に減少したことがわかります。これは、圧縮によってスペースが 62% 節約されたことを示しています。データベースの節約は、データベース内のテーブル間のデータの分散方法によって異なります。
