翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
OPA ドキュメントモデルによるテナント分離
OPA はドキュメントを使用して意思決定を行います。これらのドキュメントにはテナント固有のデータを含めることができるため、テナントデータの分離を維持する方法を検討する必要があります。OPA ドキュメントは、ベースドキュメントと仮想ドキュメントで構成されます。ベースドキュメントには、外部からのデータが含まれています。これには、OPA に直接提供されるデータ、OPA リクエストに関するデータ、および入力として OPA に渡される可能性のあるデータが含まれます。仮想ドキュメントはポリシーによって計算され、OPA ポリシーとルールが含まれます。詳細については、OPA ドキュメント
マルチテナントアプリケーション用に OPA でドキュメントモデルを設計するには、まず OPA で決定する必要があるベースドキュメントのタイプを考慮する必要があります。これらのベースドキュメントにテナント固有のデータが含まれている場合は、このデータが誤ってクロステナントアクセスにさらされないように対策を講じる必要があります。幸い、多くの場合、OPA で決定を下すためにテナント固有のデータは必要ありません。次の例は、入力ドキュメントに示されているように、API を所有するテナントと、ユーザーがテナントのメンバーであるかどうかに基づいて API へのアクセスを許可する架空の OPA ドキュメントモデルを示しています。
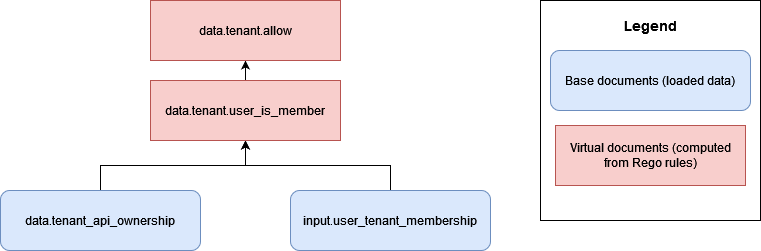
このアプローチでは、OPA は、API を所有するテナントに関する情報を除き、テナント固有のデータにアクセスできません。この場合、OPA がアクセス決定を行うために使用する唯一の情報は、ユーザーのテナントとの関連付けとテナントの APIs との関連付けであるため、OPA によるクロステナントアクセスの促進に懸念はありません。各テナントは独立したリソースを所有するため、このタイプの OPA ドキュメントモデルをサイロ化された SaaS モデルに適用できます。
ただし、多くの RBAC 認可アプローチでは、クロステナントの情報が公開される可能性があります。次の例では、架空の OPA ドキュメントモデルにより、ユーザーがテナントのメンバーであるかどうか、およびユーザーが API にアクセスするための正しいロールを持っているかどうかに基づいて、API へのアクセスが許可されます。
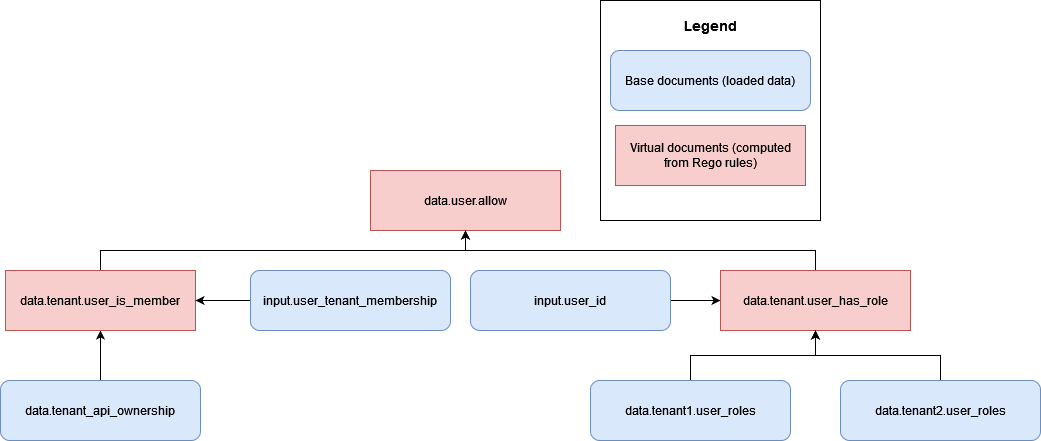
このモデルでは、クロステナントアクセスのリスクが生じます。これは、 および で複数のテナントのロールdata.tenant1.user_rolesとアクセス許可を OPA がアクセスできるようにして、認可の決定を行うdata.tenant2.user_roles必要があるためです。テナントの分離とロールマッピングのプライバシーを維持するために、このデータは OPA 内に存在しないでください。RBAC データは、データベースなどの外部データソースに存在する必要があります。さらに、事前定義されたロールを特定のアクセス許可にマッピングするために OPA を使用しないでください。これにより、テナントが独自のロールとアクセス許可を定義することが難しくなります。また、認可ロジックがリジッドになり、継続的な更新が必要になります。RBAC データを OPA 意思決定プロセスに安全に組み込む方法のガイダンスについては、このガイドの後半にある「テナントの分離とデータプライバシーに関する推奨事項」セクションを参照してください。
テナント固有のデータを非同期ベースドキュメントとして保存しないことで、OPA でテナント分離を簡単に維持できます。非同期ベースドキュメントは、メモリに保存され、OPA で定期的に更新できるデータです。OPA 入力などの他の基本ドキュメントは同期的に渡され、決定時にのみ使用できます。例えば、クエリへの OPA 入力の一部としてテナント固有のデータを提供することは、テナント分離の違反にはなりません。これは、そのデータが決定プロセス中に同期的にしか利用できないためです。
