翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Redshift テーブル設計のベストプラクティス
このセクションでは、データベーステーブルの設計に関するベストプラクティスの概要を説明します。クエリのパフォーマンスと効率を最適化するには、以下のベストプラクティスに従うことをお勧めします。
ソートキーの仕組みを理解する
Amazon Redshift は、ソートキーに応じたソート順でデータをディスクに保存します。Amazon Redshift クエリオプティマイザは、最適なクエリプランを決定する際にソート順を使用します。ソートキーを効果的に使用するには、以下を実行することをお勧めします。
-
テーブルは可能な限りソートされたままにします。
-
VACUUMソートを使用して最適なパフォーマンスを復元します。 -
ソートキー列を圧縮しないでください。
-
ソートキーが圧縮され、
sortkey1_skew比率が著しく高い場合は、ソートキーで圧縮を有効にせずにテーブルを再作成します。 -
ソートキー列に関数を適用しないでください。例えば、次のクエリでは、
trans_dt : TIMESTAMPTZソートキー列をDATEにキャストする場合、そのソートキー列は使用されません。select order_id, order_amt from sales where trans_dt::date = '2021-01-08'::date -
ソートキーの順序で
INSERTオペレーションを実行します。 -
可能な場合は、
GROUP BY句でソートキーを使用します。
クエリ調整のヒント
クエリを調整するには、以下を実行することをお勧めします。
-
最適な効果を得るには、常に複合ソートキーをカーディナリティの低いものから高いものの順に並べます。
-
複合ソートキーの先頭キーが比較的一意である (つまり、カーディナリティが高い) 場合は、ソートキーに列を追加しないでください。列を追加してもクエリのパフォーマンスにはほとんど影響せず、メンテナンスコストが増えていきます。
ソートキーの有効性を評価する
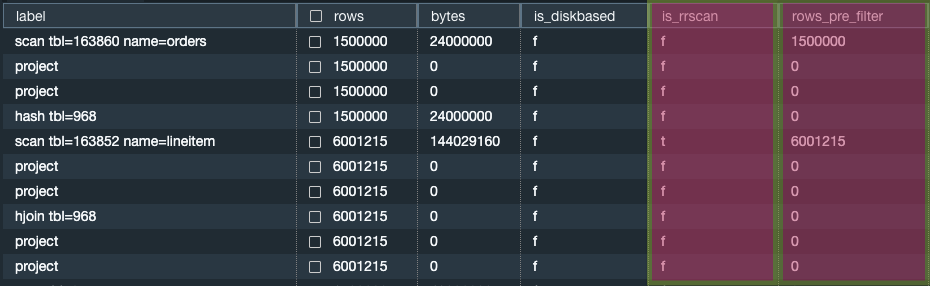
クエリを最適化するには、クエリの有効性を評価できるようにする必要があります。SVL_QUERY_SUMMARY ビューを使用して、クエリの実行についての全般的な情報を確認することをお勧めします。このビューでは、IS_RRSCAN 属性を使用して、EXPLAIN プランのステップで範囲制限付きスキャンを使用しているかどうかを判断できます。また、rows_pre_filter 属性を使用して、ソートキーの選択性を決定することもできます。
v_my_last_query_summary
次のステートメントは、クエリの実行に関する一般的な情報を検索する方法を示しています。
select lpad(' ',stm+seg+step) || label as label, rows, bytes, is_diskbased, is_rrscan, rows_pre_filter from svl_query_summary where query = pg_last_query_id() order by stm, seg, step;
前述のクエリは、次のサンプル出力を返します。
テーブルについて理解する
テーブルの重要なプロパティを理解することが重要です。テーブルの詳細については、以下を実行してください。
-
PG_TABLE_DEF を使用して、テーブル列に関する情報を表示します。
-
SVV_TABLE_INFO を使用すると、データ分散スキュー、キー分散スキュー、テーブルサイズ、統計情報など、テーブルに関するより包括的な情報を表示することができます。
適切なテーブルの分散スタイルを選択する
クエリを実行すると、必要に応じて結合と集計を実行するために、クエリオプティマイザによって行がコンピューティングノードに再分散されます。テーブル分散スタイルの選択は、クエリを実行する前にデータを必要な場所に配置しておくことによって、再分散ステップの影響を最小限に抑えるために行われます。
適切なテーブル分散スタイルを選択するには、次のアプローチをお勧めします。
-
同じノード内の行をコロケーションすることで、クエリ実行プランでのブロードキャストと再分散を回避します。例えば、
DISTKEYを選択すると、ファクトテーブルと 1 次元テーブルを共通の列に分散できます。フィルタリングされたデータセットのサイズに基づいて最大ディメンションを選択します。結合で使用されている行のみが分散される必要があるため、テーブルのサイズではなく、フィルタリング後のデータセットのサイズを考慮します。 -
分散キーが作成された列に歪みがないことを確認します。歪みがあると、1 つのコンピューティングノードが他のコンピューティングノードよりも重い負荷をかける可能性があります。歪みがあることに気付いた場合は、分散キー列の変更を検討してください。列の値が均一に分散されているか、カーディナリティ値が高い場合、列を分散キーの候補と見なすことができます。
-
結合条件で使用されるテーブルが小さい (1 GB 未満) 場合は、分散スタイル
ALLを検討してください。 -
分散キーを圧縮することはできますが、ソートキー列 (特にソートキーの最初の列) を圧縮しないようにする必要があります。
注記
自動テーブル最適化を使用する場合、テーブルの分散スタイルを選択する必要はありません。詳細については、Amazon Redshift ドキュメントの「Working with automatic table optimization」を参照してください。Amazon Redshift が適切なディストリビューションスタイルを選択できるようにするには、ディストリビューションスタイルに AUTO を指定します。
