翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Lambda 関数で Python を使用して S3 オブジェクトの並列読み取りを実行する
Eduardo Bortoluzzi、Amazon Web Services
概要
このパターンを使用して、Amazon Simple Storage Service (Amazon S3) バケットからドキュメントのリストをリアルタイムで取得して要約できます。このパターンは、Amazon Web Services (AWS) の S3 バケットからオブジェクトを並列に読み取るためのサンプルコードを提供します。このパターンは、Python を使用して AWS Lambda 関数で I/O バインドタスクを効率的に実行する方法を示しています。
ある金融会社は、このパターンをインタラクティブなソリューションで使用して、相関する金融取引をリアルタイムで手動で承認または拒否しました。金融取引ドキュメントを市場に関連する S3 バケットに保存しました。オペレーターは S3 バケットからドキュメントのリストを選択し、ソリューションが計算した取引の合計値を分析して、選択したバッチを承認または拒否することを決定しました。
I/O にバインドされたタスクは複数のスレッドをサポートします。このサンプルコードでは、Lambda 関数が最大 1,024 スレッドをサポートしている場合でも、concurrent.futures.ThreadPoolExecutorbotocore でプールの最大接続数を増やす必要があります。
サンプルコードは、S3 バケット内で JSON データとともに 8.3 KB オブジェクトを 1 つ使用します。オブジェクトは複数回読み込まれます。Lambda 関数がオブジェクトを読み取ると、JSON データは Python オブジェクトにデコードされます。2024 年 12 月、この例を実行した後の結果は、2,304 MB のメモリで設定された Lambda 関数を使用して 2.3 秒で 1,000 回の読み込みを処理し、27 秒で 10,000 回の読み込みを処理しました。 は、128 MB から 10,240 MB (10 GB) のメモリ設定 AWS Lambda をサポートしますが、Lambdamemory を 2,304 MB を超えて増やすと、この特定の I/O バウンドタスクの実行時間を短縮することはできませんでした。
AWS Lambda Power Tuning
前提条件と制限事項
前提条件
アクティブな AWS アカウント
Python 開発の習熟度
制限事項
Lambda 関数は、最大 1,024 の実行プロセスまたはスレッドを持つことができます。
新しい AWS アカウント の Lambda メモリ制限は 3,008 MB です。それに応じて AWS Lambda Power Tuning ツールを調整します。詳細については、「トラブルシューティング」セクションを参照してください。
Amazon S3 には、パーティション化されたプレフィックスごとに 1 秒あたり 5,500 件の GET/HEAD リクエストの制限があります。
製品バージョン
Python 3.9 以降
AWS Cloud Development Kit (AWS CDK) v2
AWS Command Line Interface (AWS CLI) バージョン 2
AWS Lambda Power Tuning 4.3.6 (オプション)
アーキテクチャ
ターゲットテクノロジースタック
AWS Lambda
Amazon S3
AWS Step Functions ( AWS Lambda Power Tuning がデプロイされている場合)
ターゲットアーキテクチャ
次の図は、S3 バケットからオブジェクトを並行して読み取る Lambda 関数を示しています。この図には、Lambda 関数メモリを微調整するための AWS Lambda Power Tuning ツール用の Step Functions ワークフローもあります。このファインチューニングは、コストとパフォーマンスのバランスをとるのに役立ちます。
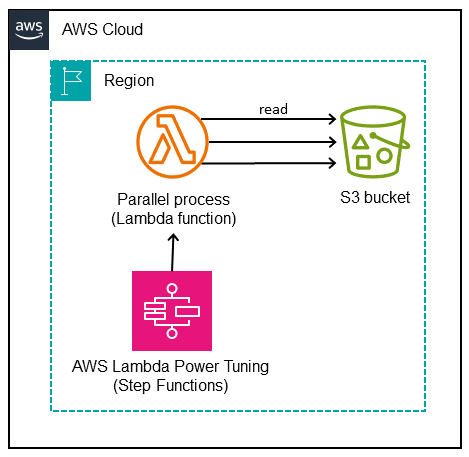
自動化とスケール
Lambda 関数は、必要に応じて迅速にスケールします。需要が高いときに Amazon S3 から 503 Slow Down エラーを受信しないように、スケーリングにいくつかの制限を設定することをお勧めします。
ツール
AWS サービス
AWS Cloud Development Kit (AWS CDK) v2 は、コードで AWS クラウド インフラストラクチャを定義してプロビジョニングするのに役立つソフトウェア開発フレームワークです。デプロイするインフラストラクチャの例が作成されました AWS CDK。
AWS Command Line InterfaceAWS CLI は、コマンドラインシェルのコマンド AWS のサービス を使用して を操作するのに役立つオープンソースツールです。このパターンでは、 AWS CLI バージョン 2 を使用してサンプル JSON ファイルをアップロードします。
AWS Lambda は、サーバーのプロビジョニングや管理を行うことなくコードを実行できるコンピューティングサービスです。必要に応じてコードを実行し、自動的にスケーリングするため、課金は実際に使用したコンピューティング時間に対してのみ発生します。
Amazon Simple Storage Service Amazon S3 は、どのようなデータ量であっても、データを保存、保護、取得することを支援するクラウドベースのオブジェクトストレージサービスです。
AWS Step Functions は、 AWS Lambda 関数と他の AWS のサービスを組み合わせてビジネスクリティカルなアプリケーションを構築するのに役立つサーバーレスオーケストレーションサービスです。
その他のツール
「Python
」は汎用のコンピュータープログラミング言語です。アイドルワーカースレッドの再利用 は Python バージョン 3.8 で導入され、このパターンの Lambda 関数コードは Python バージョン 3.9 以降用に作成されました。
コードリポジトリ
このパターンのコードは、「aws-lambda-parallel-download
ベストプラクティス
この AWS CDK コンストラクトは、インフラストラクチャをデプロイするための AWS アカウントユーザーのアクセス許可に依存します。 AWS CDK Pipelines またはクロスアカウントデプロイを使用する場合は、「スタックシンセサイザー」を参照してください。
このサンプルアプリケーションでは、S3 バケットでアクセスログが有効になっていません。本番コードでアクセスログを有効にするのがベストプラクティスです。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
Python がインストールされているバージョンを確認します。 | このコードは Python 3.9 と Python 3.13 で特別にテストされており、これらのリリース間のすべてのバージョンで動作するはずです。Python のバージョンを確認するには、ターミナルで 必要なモジュールがインストールされていることを確認するには、 | クラウドアーキテクト |
をインストールします AWS CDK。 | まだインストール AWS CDK されていない場合は、「 の開始方法 AWS CDK」の手順に従ってください。インストールされている AWS CDK バージョンが 2.0 以降であることを確認するには、 を実行します | クラウドアーキテクト |
環境 をブートストラップします。 | まだブートストラップされていない場合、環境をブートストラップするには、「AWS CDKで使用する環境をブートストラップする」の手順に従ってください。 | クラウドアーキテクト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
リポジトリのクローン作成 | 最新バージョンのリポジトリのクローンを作成するには、次のコマンドを実行します。
| クラウドアーキテクト |
作業ディレクトリをクローニングされたリポジトリに変更します。 | 次のコマンドを実行します。
| クラウドアーキテクト |
Python 仮想環境を作成します。 | Python 仮想環境を作成するには、次のコマンドを実行します。
| クラウドアーキテクト |
仮想環境をアクティブ化します。 | 仮想環境を有効にするには、次のコマンドを実行します。
| クラウドアーキテクト |
SDK の依存関係をインストールします。 | Python 依存関係をインストールするには、
| クラウドアーキテクト |
コードを参照します。 | (オプション) S3 バケットからオブジェクトをダウンロードするサンプルコードは、 インフラストラクチャコードは | クラウドアーキテクト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
アプリケーションをデプロイします。 |
AWS CDK 出力を書き留めます。
| クラウドアーキテクト |
サンプル JSON ファイルをアップロードします。 | リポジトリには、約 9 KB のサンプル JSON ファイルが含まれています。作成したスタックの S3 バケットにファイルをアップロードするには、次のコマンドを実行します。
を AWS CDK 出力の対応する値 | クラウドアーキテクト |
アプリを実行します。 | アプリを実行するには、次の手順を実行します。
| クラウドアーキテクト |
ダウンロード数を追加します。 | (オプション) 1,500 の GET オブジェクト呼び出しを実行するには、
| クラウドアーキテクト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
AWS Lambda Power Tuning ツールを実行します。 |
実行の最後に、[実行の入力と出力] タブに結果が表示されます。 | クラウドアーキテクト |
AWS Lambda パワーチューニングの結果をグラフで表示します。 | [実行の入力と出力] タブで、 | クラウドアーキテクト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
S3 バケットからオブジェクトを削除します。 | デプロイされたリソースを破棄する前に、S3 バケットからすべてのオブジェクトを削除します。
を AWS CDK 出力の値 | クラウドアーキテクト |
リソースを破棄します。 | このパイロット用に作成されたすべてのリソースを破棄するには、次のコマンドを実行します。
| クラウドアーキテクト |
トラブルシューティング
| 問題 | ソリューション |
|---|---|
| 新しいアカウントでは、Lambda 関数で 3,008 MB 以上を設定できない場合があります。 AWS Lambda Power Tuning を使用してテストするには、Step Functions の実行を開始するときに、入力 JSON に次のプロパティを追加します。
|
関連リソース
追加情報
Code
次のコードスニペットは、並列 I/O 処理を実行します。
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: for result in executor.map(a_function, (the_arguments)): ...
ThreadPoolExecutor は、スレッドが利用可能になると再利用します。
テストと結果
これらのテストは 2024 年 12 月に実施されました。
最初のテストでは 2,500 のオブジェクト読み取りが処理され、次のような結果になりました。

3,009 MB から、処理時間レベルはメモリが増えてもほぼ同じままでしたが、メモリサイズの増加に伴ってコストが増加しました。
別のテストでは、256 MB の倍数の値を使用し、10,000 のオブジェクト読み取りを処理して、1,536 MB から 3,072 MB のメモリの範囲を調査しました。その結果は次のとおりです。

最高の費用対効果の比率は、2,304 MB のメモリ Lambda 設定でした。
比較として、2,500 のオブジェクト読み取りのシーケンシャルプロセスには 47 秒かかりました。2,304 MB の Lambda 設定を使用した並列処理には 7 秒かかり、85% 短縮されました。

