翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Blu Age モダナイズされたアプリケーションのパフォーマンスを最適化する
Amazon Web Services、Vishal Jaswani、Manish Roy、Himanshu Sah
概要
AWS Blu Age でモダナイズされたメインフレームアプリケーションは、本番環境にデプロイする前に、機能とパフォーマンスの同等性テストが必要です。パフォーマンステストでは、モダナイズされたアプリケーションは、特に複雑なバッチジョブで、レガシーシステムよりも動作が遅くなる可能性があります。このギャップは、メインフレームアプリケーションがモノリシックであるのに対し、最新のアプリケーションが多層アーキテクチャを使用していることに由来します。このパターンは、AWS Blu Age で自動リファクタリングを使用してモダナイズされたアプリケーションのパフォーマンスギャップに対処するための最適化手法を示しています。
このパターンでは、ネイティブ Java およびデータベース調整機能を備えた AWS Blu Age モダナイゼーションフレームワークを使用して、パフォーマンスのボトルネックを特定して解決します。このパターンでは、プロファイリングとモニタリングを使用して、SQL 実行時間、メモリ使用率、I/O パターンなどのメトリクスに関するパフォーマンスの問題を特定する方法について説明します。次に、データベースクエリの再編成、キャッシュ、ビジネスロジックの改良など、ターゲットを絞った最適化を適用する方法について説明します。
バッチ処理時間とシステムリソース使用率の向上により、モダナイズされたシステムのメインフレームパフォーマンスレベルを一致させることができます。このアプローチは、最新のクラウドベースのアーキテクチャへの移行中も機能的同等性を維持します。
このパターンを使用するには、「エピック」セクションの手順に従ってシステムを設定してパフォーマンスホットスポットを特定し、「アーキテクチャ」セクションで詳述されている最適化手法を適用してください。
前提条件と制限
前提条件
AWS Blu Age モダナイズされたアプリケーション
データベースクライアントとプロファイリングツールをインストールするための管理者権限
AWS Blu Age レベル 3 認定
AWS Blu Age フレームワーク、生成されたコード構造、Java プログラミングに関する中級レベルの理解
制限事項
以下の最適化機能と機能は、このパターンの範囲外です。
アプリケーション層間のネットワークレイテンシーの最適化
Amazon Elastic Compute Cloud (Amazon EC2) インスタンスタイプとストレージの最適化によるインフラストラクチャレベルの最適化
同時ユーザー負荷テストとストレステスト
製品バージョン
JProfiler バージョン 13.0 以降 (最新バージョンを推奨)
pgAdmin バージョン 8.14 以降
アーキテクチャ
このパターンでは、JProfiler や pgAdmin などのツールを使用して AWS Blu Age アプリケーションのプロファイリング環境を設定します。 AWS Blu Age が提供する DAOManager API と SQLExecutionBuilder APIs による最適化をサポートしています。
このセクションの残りの部分では、モダナイズされたアプリケーションのパフォーマンスホットスポットと最適化戦略を特定するための詳細情報と例を示します。「エピック」セクションのステップでは、詳細なガイダンスのためにこの情報を参照します。
モダナイズされたメインフレームアプリケーションでのパフォーマンスホットスポットの特定
モダナイズされたメインフレームアプリケーションにおいて、パフォーマンスホットスポットとは、大幅な速度低下や非効率を引き起こすコード内の特定の領域を指します。ホットスポットが生まれる要因として、メインフレームアプリケーションとモダナイズされたアプリケーション間のアーキテクチャ上の違いが挙げられます。こうしたパフォーマンスのボトルネックを特定し、モダナイズされたアプリケーションのパフォーマンスを最適化するには、SQL ログ記録、EXPLAIN プランのクエリ、JProfiler 分析の 3 つの手法を使用できます。
ホットスポット特定手法: SQL ログ記録
AWS Blu Age を使用してモダナイズされたアプリケーションを含む最新の Java アプリケーションには、SQL クエリをログに記録する機能が組み込まれています。 AWS Blu Age プロジェクトで特定のロガーを有効にして、アプリケーションによって実行される SQL ステートメントを追跡および分析できます。この手法は、過剰な個々のクエリや構造化されていないデータベース呼び出しなど、バッチ処理やクエリの改良によって最適化される可能性のある非効率的なデータベースアクセスパターンを特定するのに特に役立ちます。
AWS Blu Age モダナイズされたアプリケーションで SQL ログ記録を実装するには、 application.properties ファイル内の SQL ステートメントDEBUGのログレベルを に設定して、クエリ実行の詳細をキャプチャします。
level.org.springframework.beans.factory.support.DefaultListableBeanFactory : WARN level.com.netfective.bluage.gapwalk.runtime.sort.internal: WARN level.org.springframework.jdbc.core.StatementCreatorUtils: DEBUG level.com.netfective.bluage.gapwalk.rt.blu4iv.dao: DEBUG level.com.fiserv.signature: DEBUG level.com.netfective.bluage.gapwalk.database.support.central: DEBUG level.com.netfective.bluage.gapwalk.rt.db.configuration.DatabaseConfiguration: DEBUG level.com.netfective.bluage.gapwalk.rt.db.DatabaseInteractionLoggerUtils: DEBUG level.com.netfective.bluage.gapwalk.database.support.AbstractDatabaseSupport: DEBUG level.com.netfective.bluage.gapwalk.rt: DEBUG
最適化ターゲットを特定するために、ログに記録されたデータを使用して高頻度およびパフォーマンスの低いクエリをモニタリングします。バッチプロセス内のクエリは通常、パフォーマンスへの影響が最も大きいため、それらに焦点を当てます。
ホットスポット特定手法: EXPLAIN プランをクエリする
このメソッドは、リレーショナルデータベース管理システムのクエリ計画機能を使用します。PostgreSQL や MySQL の EXPLAIN や、Oracle などの EXPLAIN PLAN コマンドを使用することで、データベースが特定のクエリをどのように実行するか調べることができます。これらのコマンドの出力は、インデックスを使用するか、完全なテーブルスキャンを実行するかなど、クエリ実行戦略に関する貴重なインサイトを提供します。この情報は、クエリのパフォーマンスを最適化するために重要であり、適切なインデックス作成により実行時間が大幅に短縮される場合には特に重要です。
アプリケーションログから最も反復的な SQL クエリを抽出し、データベースに固有の EXPLAIN コマンドを使用して、パフォーマンスの低いクエリの実行パスを分析します。PostgreSQL データベースの例を次に示します。
クエリ:
SELECT * FROM tenk1 WHERE unique1 < 100;
EXPLAIN コマンド:
EXPLAIN SELECT * FROM tenk1 where unique1 < 100;
出力:
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) Index Cond: (unique1 < 100)
EXPLAIN 出力は以下のように解釈できます。
EXPLAIN計画を最も内側から外側 (下から上) のオペレーションに読み取ります。主要な用語を探します。例えば、
Seq Scanはフルテーブルスキャンを示し、Index Scanはインデックスの使用状況を示します。コスト値を確認する: 最初の数値は起動コスト、2 番目の数値は合計コストです。
推定出力行数の
rowsの値を参照してください。
この例では、クエリエンジンはインデックススキャンを使用して一致する行を検索し、それらの行のみを取得します (Bitmap Heap Scan)。これは、個々の行アクセスのコストが高いにもかかわらず、テーブル全体をスキャンするよりも効率的です。
EXPLAIN プランの出力のテーブルスキャンオペレーションは、インデックスが欠落していることを示します。最適化には、適切なインデックスを作成する必要があります。
ホットスポット特定手法: JProfiler 分析
JProfiler は包括的な Java プロファイリングツールです。低速のデータベース呼び出しと CPU 負荷の高い呼び出しを特定することで、パフォーマンスのボトルネックを解決できます。このツールは、遅い SQL クエリと非効率的なメモリ使用を特定するのに特に効果的です。
クエリの分析例:
select evt. com.netfective.bluage.gapwalk.rt.blu4iv.dao.Blu4ivTableManager.queryNonTrasactional
JProfiler ホットスポットビューには、次の情報が表示されます。
時間列
合計実行時間を表示します (例: 329 秒)
合計アプリケーション時間の割合を表示します (例: 58.7%)
最も時間のかかるオペレーションを特定するのに役立ちます
平均時間列
実行あたりの時間を表示します (例: 2,692 マイクロ秒)
個々のオペレーションパフォーマンスを示します
個々のオペレーションが遅い場合の発見に役立ちます
イベント列
実行数を表示します (例: 122,387 回)
オペレーションの頻度を示します
頻繁に呼び出されるメソッドの特定に役立ちます
サンプル結果:
高頻度: 実行数 122,387 回は、最適化の可能性を示します
パフォーマンス上の懸念: 平均時間 2,692 マイクロ秒は、非効率を示します
重大な影響: 合計時間の 58.7% は、重大なボトルネックを示します
JProfiler は、アプリケーションのランタイム動作を分析して、静的コード分析や SQL ログ記録では明白ではなかった可能性のあるホットスポットを明らかにすることができます。これらのメトリクスは、最適化が必要なオペレーションを特定し、最も効果的な最適化戦略を決定するのに役立ちます。JProfiler の各機能について、詳しくは JProfiler ドキュメント
これらの 3 つの手法 (SQL ログ記録、EXPLAIN プランのクエリ、JProfiler) を組み合わせて使用すると、アプリケーションのパフォーマンス特性を包括的に把握できます。最も重要なパフォーマンスホットスポットを特定して対処することで、元のメインフレームアプリケーションとモダナイズされたクラウドベースのシステムの間のパフォーマンスギャップを埋めることができます。
アプリケーションのパフォーマンスホットスポットを特定したら、次のセクションで説明する最適化戦略を適用できます。
メインフレームモダナイズの最適化戦略
このセクションでは、メインフレームシステムからモダナイズされたアプリケーションを最適化するための主要な戦略の概要を説明します。既存 API の利用、効果的なキャッシュの実装、ビジネスロジックの最適化の 3 つの戦略に焦点を当てています。
最適化戦略: 既存の API を使用する
AWS Blu Age は、パフォーマンスを最適化するために使用できる DAO インターフェイスにいくつかの強力な APIs を提供します。DAOManager と SQLExecutionBuilder の 2 つのプライマリインターフェイスは、アプリケーションのパフォーマンスを向上させる機能を提供します。
DAOManager
DAOManager は、モダナイズされたアプリケーションのデータベースオペレーションのプライマリインターフェイスとして機能します。データベースオペレーションを強化し、アプリケーションのパフォーマンスを向上させる複数の方法を提供するものであり、特に簡単な作成、読み取り、更新、削除 (CRUD) オペレーションとバッチ処理に役立ちます。
SetMaxResults を使用します。DAOManager API では、SetMaxResults メソッドを使用して、単一のデータベースオペレーションで取得するレコードの最大数を指定できます。デフォルトでは、DAOManager は一度に取得するレコード数は 10 に限られるため、大規模なデータセットを処理する際には複数のデータベース呼び出しが発生する可能性があります。この最適化は、アプリケーションが多数のレコードを処理する必要があり、それらを取得するために現在複数のデータベース呼び出しを実行している場合に使用します。これは、大規模なデータセットを反復処理するバッチ処理シナリオで特に役立ちます。次の例では、左側のコード (最適化前) は、デフォルトのデータ取得値である 10 レコードを使用しています。右側のコード (最適化後) では、一度に 100,000 件のレコードを取得するように setMaxResults を設定しています。

注記
より大きなバッチサイズを慎重に選択し、オブジェクトのサイズを確認します。この最適化によりメモリフットプリントが増加するためです。
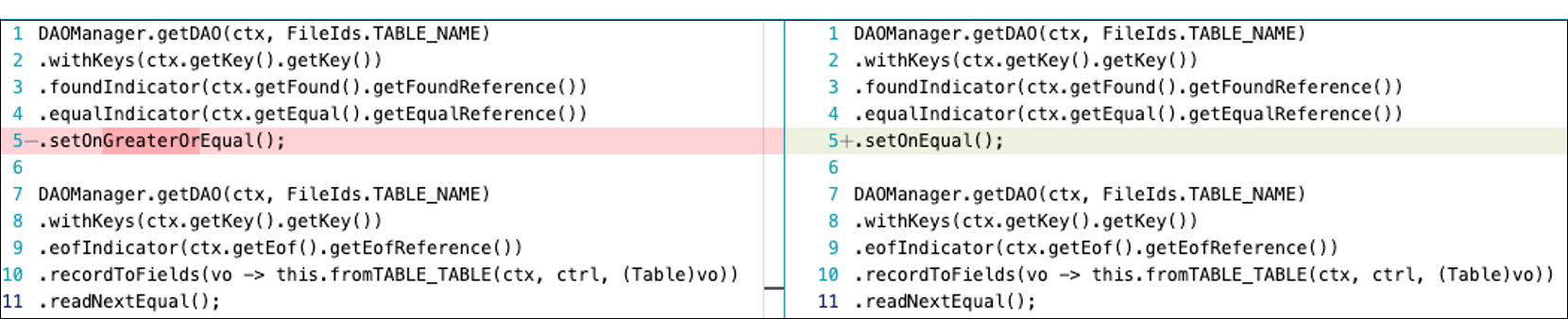
SetOnGreatorOrEqual を SetOnEqual に置き換えます。この最適化では、レコードを取得するための条件設定に使用する方法を変更する必要があります。SetOnGreatorOrEqual メソッドは指定された値以上のレコードを取得しますが、SetOnEqual は指定された値と正確に一致するレコードのみを取得します。
正確な一致が必要であり、現在 SetOnGreatorOrEqual メソッドの後に readNextEqual() を使用している場合は、以下のコード例に示すように SetOnEqual を使用してください。この最適化により、不要なデータの取得が軽減されます。
バッチ書き込みおよび更新オペレーションを使用します。バッチオペレーションを使用して、複数の書き込みまたは更新オペレーションを 1 つのデータベーストランザクションにグループ化できます。これにより、データベース呼び出しの数が減少し、複数のレコードを含むオペレーションのパフォーマンスが大幅に向上します。
次の例では、左側のコードがループで書き込みオペレーションを実行するため、アプリケーションのパフォーマンスが低下します。このコードは、バッチ書き込みオペレーションを使用して最適化できます。
WHILEループのイテレーションのたびに、バッチサイズが所定のサイズである 100 に達するまでレコードをバッチに追加します。その後、バッチが所定のバッチサイズに達したときにバッチをフラッシュしてから、残りのレコードをデータベースにフラッシュできます。これは、更新が必要な大規模なデータセットを処理するシナリオで特に役立ちます。
インデックスを追加します。インデックスの追加は、クエリのパフォーマンスを大幅に向上させるデータベースレベルの最適化です。インデックスを使用すると、データベースはテーブル全体をスキャンすることなく、特定の列値を持つ行をすばやく見つけることができます。
WHERE句、JOIN条件、またはORDER BYステートメントで頻繁に使用される列のインデックス作成を使用します。これは、大きなテーブルや、迅速なデータ取得が重要な場合に特に重要です。
SQLExecutionBuilder
SQLExecutionBuilder は柔軟な API であり、実行される SQL クエリを制御したり、特定の列のみを取得したり、SELECT を利用した INSERT を実行したり、動的なテーブル名を使用したりすることができます。次の例では、SQLExecutorBuilder は定義したカスタムクエリを使用します。

DAOManager と SQLExecutionBuilder の選択
これらの API の選択は、特定のユースケースによって異なります。
AWS Blu Age ランタイムで SQL クエリを自分で記述するのではなく生成する場合は、DAOManager を使用します。
データベース固有の機能を活用したり、最適な SQL クエリを作成したりするために SQL クエリを記述する必要がある場合は、SQLExecutionBuilder を選択します。
最適化戦略: キャッシュ
モダナイズされたアプリケーションでは、効果的なキャッシュ戦略を実装することで、データベース呼び出しを大幅に削減し、応答時間を短縮できます。これにより、メインフレーム環境とクラウド環境のパフォーマンスギャップを埋めることができます。
AWS Blu Age アプリケーションでは、シンプルなキャッシュ実装はハッシュマップや配列リストなどの内部データ構造を使用するため、コストとコードの再編成を必要とする外部キャッシュソリューションを設定する必要はありません。このアプローチは、頻繁にアクセスされるが、頻繁に変更はされないデータに特に効果的です。キャッシュを実装するときは、メモリの制約と更新パターンを検討して、キャッシュされたデータの一貫性を維持し、実際のパフォーマンス上の利点が得られるようにします。
キャッシュを成功させるための鍵は、キャッシュする適切なデータを特定することです。次の例では、左側のコードは常にテーブルからデータを読み取りますが、ローカルハッシュマップに特定のキーの値がない場合、右側のコードはテーブルからデータを読み取ります。cacheMap は、プログラムのコンテキストで作成され、プログラムコンテキストのクリーンアップメソッドでクリアされるハッシュマップオブジェクトです。
DAOManager を使用したキャッシュ:

SQLExecutionBuilder を使用したキャッシュ:

最適化戦略: ビジネスロジックの最適化
ビジネスロジックの最適化では、最新のアーキテクチャ機能に合わせて AWS Blu Age から自動生成されたコードを再構築することに重点を置いています。これは、生成されたコードがレガシーメインフレームコードと同じロジック構造を維持している場合に必要になります。これは、最新のシステムには適していない可能性があります。目標は、元のアプリケーションと機能的同等性を維持しながらパフォーマンスを向上させることです。
この最適化アプローチは、単純な API 調整やキャッシュ戦略にとどまりません。これには、アプリケーションがデータを処理し、データベースとやり取りする方法を変更する必要もあります。一般的な最適化には、シンプルな更新を行うための不要な読み取り操作の回避、冗長なデータベース呼び出しの削除、最新のアプリケーションアーキテクチャとの整合性を高めるためのデータアクセスパターンの再編成などがあります。ここにいくつか例を挙げます。
データベース内のデータを直接更新します。ループにより複数の DAOManager オペレーションを行う代わりに、直接 SQL 更新を使用してビジネスロジックを再構築します。例えば、次のコード (左側) は複数のデータベース呼び出しを行い、過剰なメモリを使用します。具体的には、ループ内の複数のデータベースの読み取りおよび書き込みオペレーション、バッチ処理ではなく個々の更新、イテレーションごとに不要なオブジェクトの作成を使用します。
次の最適化されたコード (右側) では、単一の Direct SQL 更新オペレーションを使用します。具体的には、複数の呼び出しの代わりに 1 つのデータベース呼び出しを使用し、すべての更新を 1 つのステートメントで処理するため、ループは必要ありません。この最適化によって、パフォーマンスとリソース使用率が向上し、複雑さが軽減されます。これにより、SQL インジェクションが防止され、クエリ計画のキャッシュが改善され、セキュリティが向上します。

注記
常にパラメータ化されたクエリを使用して SQL インジェクションを防ぎ、適切なトランザクション管理を確保します。
冗長なデータベース呼び出しを削減します。冗長なデータベース呼び出しは、特にループ内で発生する場合、アプリケーションのパフォーマンスに大きな影響を与える可能性があります。単純で効果的な最適化手法は、同じデータベースクエリを複数回繰り返さないようにすることです。次のコード比較は、
retrieve()データベース呼び出しをループ外に移動することで、同じクエリが冗長的に実行されるのを防ぎ、効率を向上させる例を示します。
SQL
JOIN句を使用してデータベース呼び出しを減らします。SQLExecutionBuilder を実装して、データベースの呼び出しを最小限に抑えます。SQLExecutionBuilder は SQL 生成をより細かく制御でき、DAOManager では効率的に処理できない複雑なクエリに特に役立ちます。例えば、次のコードは複数の DAOManager 呼び出しを使用します。List<Employee> employees = daoManager.readAll(); for(Employee emp : employees) { Department dept = deptManager.readById(emp.getDeptId()); // Additional call for each employee Project proj = projManager.readById(emp.getProjId()); // Another call for each employee processEmployeeData(emp, dept, proj); }最適化済みのコードは、SQLExecutionBuilder でデータベース呼び出しを 1 回だけ使用します。
SQLExecutionBuilder builder = new SQLExecutionBuilder(); builder.append("SELECT e.*, d.name as dept_name, p.name as proj_name"); builder.append("FROM employee e"); builder.append("JOIN department d ON e.dept_id = d.id"); builder.append("JOIN project p ON e.proj_id = p.id"); builder.append("WHERE e.status = ?", "ACTIVE"); List<Map<String, Object>> results = builder.execute(); // Single database call for(Map<String, Object> result : results) { processComplexData(result); }
最適化戦略を合わせて使用する
これらの 3 つの戦略は相乗的に機能します。API は効率的なデータアクセスのためのツールを提供し、キャッシュはデータ取り出しを繰り返す必要性を減らし、ビジネスロジックの最適化はこれらの API を可能な限り最も効果的な方法で使用できるようにします。これらの最適化を定期的にモニタリングおよび調整することで、確実に、モダナイズされたアプリケーションの信頼性と機能を維持しながら、パフォーマンスを継続的に向上させることができます。成功の鍵は、アプリケーションの特性とパフォーマンス目標に基づいて各戦略を適用するタイミングと方法を理解することです。
ツール
JProfiler
は、開発者とパフォーマンスエンジニア向けに設計された Java プロファイリングツールです。Java アプリケーションを分析して、パフォーマンスのボトルネック、メモリリーク、スレッドの問題を特定するのに役立ちます。JProfiler は、CPU、メモリ、スレッドプロファイリングや、データベースと Java 仮想マシン (JVM) のモニタリングを提供することで、アプリケーションの動作に関するインサイトを提供します。 注記
JProfiler の代わりに、Java VisualVM
を使用することもできます。これは、Java アプリケーションのパフォーマンスのプロファイリングとモニタリングを行う無料のオープンソースツールであり、CPU 使用率、メモリ消費量、スレッド管理、ガベージコレクション統計をリアルタイムでモニタリングします。Java VisualVM は組み込みの JDK ツールであるため、基本的なプロファイリングのニーズに対しては JProfiler よりもコスト効率が高くなります。 pgAdmin
はオープンソースの PostgreSQL 向け管理開発ツールです。データベースオブジェクトの作成、管理、使用を支援するグラフィカルインターフェイスを提供します。pgAdmin を使用すると、単純な SQL クエリの記述から複雑なデータベースの開発まで、幅広いタスクを実行できます。その機能には、SQL エディタを強調表示する構文、サーバー側のコードエディタ、SQL、シェル、バッチタスクのスケジュールエージェント、初心者と経験豊富な PostgreSQL ユーザーの両方に対するすべての PostgreSQL 機能のサポートが含まれます。
ベストプラクティス
パフォーマンスホットスポットの特定:
最適化を開始する前に、パフォーマンスのベースラインメトリクスを文書化します。
ビジネス要件に基づき、パフォーマンス改善の明確な目標を設定します。
ベンチマークを行うときは、詳細なログ記録はパフォーマンスに影響する可能性があるため、無効にします。
パフォーマンステストスイートを設定して、定期的に実行します。
pgAdmin の最新バージョンを使用してください。(古いバージョンは
EXPLAINクエリプランに対応していません)ベンチマークでは、最適化が完了したら JProfiler をデタッチします。これによりレイテンシーが増加するためです。
ベンチマークでは、必ずデバッグモードではなく開始モードでサーバーを実行してください。デバッグモードではレイテンシーが増加するためです。
最適化戦略:
application.yamlファイルで SetMaxResults 値を設定し、システム仕様に従って適切なサイズのバッチを指定します。データボリュームとメモリの制約に基づいて、SetMaxResults 値を設定します。
後続の呼び出しが
.readNextEqual()である場合にのみ、SetOnGreatorOrEqual を SetOnEqual に変更します。バッチ書き込みまたは更新オペレーションでは、最後のバッチについては、設定されたバッチサイズより小さく、書き込みまたは更新オペレーションによって失われる可能性があるため、個別に処理します。
キャッシュ:
processImplでキャッシュするために導入するフィールドは実行のたびに変更し、常にそのprocessImplのコンテキストで定義するようにしてください。また、フィールドはdoReset()またはcleanUp()メソッドを使用してクリアする必要があります。インメモリキャッシュを実装する場合は、キャッシュのサイズを適正化します。メモリに非常に大きなキャッシュが保存されていると、すべてのリソースが占有され、アプリケーションの全体的なパフォーマンスに影響が及ぶ可能性があります。
SQLExecutionBuilder:
SQLExecutionBuilder で使用する予定のクエリの場合は、
PROGRAMNAME_STATEMENTNUMBERなどのキー名を使用します。SQLExecutionBuilder を使用する場合は、常に
Sqlcodフィールドを確認してください。このフィールドには、クエリが正しく実行されたか、エラーが発生したかを明示する値が含まれています。パラメータ化されたクエリを使用して SQL インジェクションを防ぎます。
ビジネスロジックの最適化:
コードを再構築するときは機能的同等性を維持し、関連するプログラムのサブセットに対してリグレッションテストとデータベース比較を実行します。
比較のためにプロファイリングのスナップショットを維持します。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
JProfiler をインストールして設定します。 |
| アプリ開発者 |
pgAdmin をインストールして設定します。 | このステップでは、DB クライアントをインストールして自分のデータベースをクエリするように設定します。このパターンでは、データベースクライアントとして PostgreSQL データベースと pgAdmin を使用します。別のデータベースエンジンを使用する場合は、対応する DB クライアントのドキュメントに従ってください。
| アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
AWS Blu Age アプリケーションで SQL クエリのログ記録を有効にします。 | アーキテクチャセクションで説明されているように、 AWS Blu Age アプリケーションの | アプリ開発者 |
クエリ | 詳しくは「アーキテクチャ」セクションをご確認ください。 | アプリ開発者 |
JProfiler のスナップショットを作成して、パフォーマンスの低いテストケースを分析します。 |
| アプリ開発者 |
JProfiler スナップショットを分析し、パフォーマンスのボトルネックを特定します。 | 次の手順に従って、JProfiler スナップショットを分析します。
JProfiler の使用について、詳しくは「アーキテクチャ」セクションおよび JProfiler ドキュメント | アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
最適化を実装する前に、パフォーマンスベースラインを確立します。 |
| アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
読み取りの呼び出しを最適化します。 | DAOManager SetMaxResults メソッドを使用して、データの取得を最適化します。手法の詳細については「アーキテクチャ」セクションをご確認ください。 | アプリ開発者、DAOManager |
データベースへの複数回の呼び出しを避けるために、ビジネスロジックをリファクタリングします。 | SQL | アプリケーション開発者、SQLExecutionBuilder |
コードをリファクタリングし、キャッシュを使用して読み取り呼び出しのレイテンシーを短縮します。 | この手法の詳細については、「アーキテクチャ」セクションの「キャッシュ」を参照してください。 | アプリ開発者 |
複数の DAOManager オペレーションを使用して単純な更新オペレーションを行う非効率的なコードを書き換えます。 | データベース内のデータを直接更新する方法の詳細については、「アーキテクチャ」セクションの「ビジネスロジックの最適化」を参照してください。 | アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
機能同等性を維持しながら、各最適化の変更を繰り返し検証します。 |
注記ベースラインメトリクスをリファレンスとして使用すると、システムの信頼性を維持しながら、各最適化の影響を正確に測定できます。 | アプリデベロッパー |
トラブルシューティング
| 問題 | ソリューション |
|---|---|
最新のアプリケーションを実行すると、エラー | この問題を解決するには。
|
インデックスを追加しましたが、パフォーマンスが向上していません。 | 次の手順に従って、クエリエンジンがインデックスを使用していることを確認します。
|
out-of-memory の例外が発生しました。 | コードが、データ構造によって保持されていたメモリを解放していることを確認します。 |
バッチ書き込みオペレーションで、テーブルのレコードが欠落します。 | コードを確認し、バッチ数がゼロでない場合に追加の書き込みオペレーションが実行されていることを確認します。 |
SQL ログはアプリケーションログには表示されません。 |
|
関連リソース
AWS Blu Age を使用したアプリケーションの自動リファクタリング (AWS Mainframe Modernization ユーザーガイド)
