翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# AWS Glue ジョブと Python を使用してテストデータを生成します
*Moinul Al-Mamun、Amazon Web Services*
## 概要
このパターンは、Python で記述された AWS Glue ジョブを作成することで、何百万ものサンプルファイルをすばやく簡単に同時に生成する方法を示しています。サンプルファイルは Amazon Simple Storage Service (Amazon S3) のバケットに保存されています。大量のサンプルファイルをすばやく生成できることは、AWS クラウド内のサービスをテストまたは評価する上で重要です。たとえば、Amazon S3 プレフィックス内の何百万もの小さなファイルに対してデータ分析を実行することで、AWS Glue Studio または AWS Glue DataBrew ジョブのパフォーマンスをテストできます。
他の AWS のサービスを使用してサンプルデータセットを生成できますが、AWS Glue を使用することをお勧めします。AWS Glue はサーバーレスのデータ処理サービスであるため、インフラストラクチャを管理する必要はありません。コードを持ち込んで AWS Glue クラスターで実行するだけで済みます。さらに、AWS Glue はジョブの実行に必要なリソースをプロビジョニング、設定、スケーリングします。ジョブの実行中に使用したリソースに対してのみ料金を支払います。
## 前提条件と制限
**前提条件**
+ アクティブな AWS アカウント。
+ AWS コマンドラインインターフェイス(AWS CLI)、AWS アカウントと連携するように「[インストール](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html)」および「[設定](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html)」されている
**製品バージョン**
+ Python 3.9
+ AWS CLI バージョン 2
機能制限
トリガーあたりの AWS Glue ジョブの最大数は 50 です。詳細については、「[AWS Glue のエンドポイントとクォータ](https://docs.aws.amazon.com/general/latest/gr/glue.html)」を参照してください。
## アーキテクチャ
次の図は、出力 (つまりサンプルファイル) を S3 バケットに書き込む AWS Glue ジョブを中心としたアーキテクチャの例を示しています。
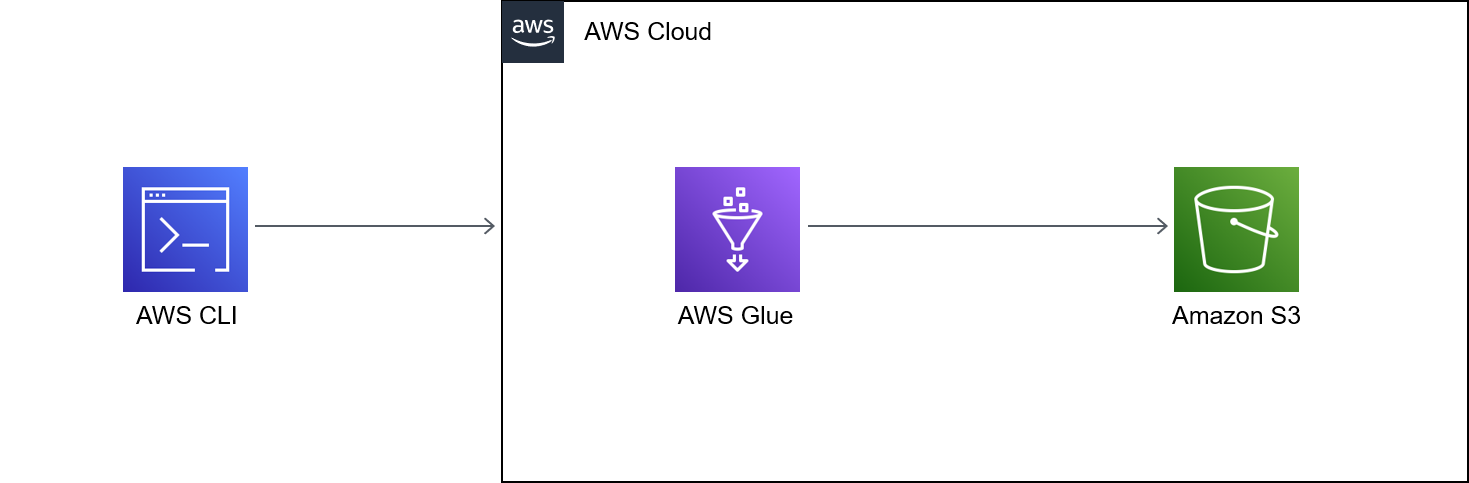
この図には、次のワークフローが含まれている。
1. AWS CLI、AWS マネジメントコンソール、または API を使用して、AWS Glue ジョブの開始を行います。AWS CLI または API を使用すると、呼び出されたジョブの並列化を自動化し、サンプルファイルを生成するためのランタイムを短縮できます。
1. AWS Glue ジョブは、ファイルコンテンツをランダムに生成し、そのコンテンツを CSV 形式に変換して、共通のプレフィックスの下で Amazon S3 オブジェクトとして保存します。各ファイルは 1 KB 未満です。AWS Glue ジョブは、`START_RANGE` と `END_RANGE` の 2 つのユーザー定義ジョブパラメータを受け入れます。これらのパラメータを使用して、ジョブを実行するたびに Amazon S3 で生成されるファイル名とファイル数を設定できます。このジョブの複数のインスタンス (たとえば、100 インスタンス) を並行実行できます。
## ツール
+ [Amazon Simple Storage Service (Amazon S3)](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html) は、あらゆる量のデータを保存、保護、取得できるクラウドベースのオブジェクトストレージサービスです。
+ 「[AWS コマンドラインインターフェイス (AWS CLI)](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html)」は、オープンソースのツールであり、コマンドラインシェルのコマンドを使用して AWS サービスとやり取りすることができます。
+ [AWS Glue](https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html) は、フルマネージド型の抽出、変換、ロード (ETL) サービスです。これにより、データストアとデータストリーム間でのデータの分類、整理、強化、移動を確実に行うことができます。
+ 「[AWS Identity and Access Management (IAM)](https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html)」は、AWS リソースへのアクセスを安全に管理し、誰が認証され、使用する権限があるかを制御するのに役立ちます。
## ベストプラクティス
このパターンを実装する際には、次の AWS Glue のベストプラクティスを検討してください。
+ 適切な AWS Glue ワーカータイプを使用してコストを削減します。ワーカータイプのさまざまなプロパティを理解し、CPU とメモリの要件に基づいてワークロードに適したワーカータイプを選択することをお勧めします。このパターンでは、DPU を最小限に抑えてコストを削減するために、Python シェルジョブをジョブタイプとして使用することをお勧めします。詳細については、AWS Glue 開発者ガイドの「[AWS Glue でのジョブの追加](https://docs.aws.amazon.com/glue/latest/dg/add-job.html)」を参照してください。
+ 同時実行数の上限を適切に設定してジョブをスケールしてください。AWS Glue ジョブの最大同時実行数は、時間要件と必要なファイル数に基づいて設定することをお勧めします。
+ 最初は、少数のファイルの生成から始めてください。AWS Glue ジョブを構築する際のコスト削減と時間の節約のため、最初は少数のファイル (1,000 など) から始めてください。これにより、トラブルシューティングが容易になります。少数のファイルの生成に成功すれば、より多くのファイル数に拡張できます。
+ 最初にローカルで実行します。AWS Glue ジョブを構築する際のコストを削減し、時間を節約するには、ローカルで開発を開始し、コードをテストしてください。シェルと統合開発環境 (IDE) の両方で AWS Glue の抽出、変換、ロード (ETL) ジョブを作成するのに役立つ Docker コンテナの設定方法については、AWS ビッグデータブログの「[コンテナを使用して AWS Glue ETL ジョブをローカルで開発する](https://aws.amazon.com/blogs/big-data/developing-aws-glue-etl-jobs-locally-using-a-container/)」を参照してください。
AWS Glue のその他のベストプラクティスについては、AWS Glue ドキュメントの「[ベストプラクティス](https://docs.aws.amazon.com/prescriptive-guidance/latest/serverless-etl-aws-glue/best-practices.html)」を参照してください。
## エピック
### 送信先 S3 バケットと IAM ロールの作成
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| ファイルを保存する S3 バケットを作成します。 | 「[S3 バケット](https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html)」とその中に「[プレフィックス](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-prefixes.html)」を作成します。このパターンでは、`s3://{your-s3-bucket-name}/small-files/` ロケーションをデモンストレーションに使用しています。 | アプリ開発者 |
| IAM ロールを作成して設定します。 | AWS Glue ジョブが S3 バケットへの書き込みに使用できる IAM ロールを作成する必要があります。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/generate-test-data-using-an-aws-glue-job-and-python.html) | アプリ開発者 |
### 同時実行を処理するように AWS Glue ジョブを作成して設定する
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| AWS Glue ジョブの作成 | コンテンツを生成して S3 バケットに保存する AWS Glue ジョブを作成する必要があります。
「[AWS Glue ジョブを作成](https://docs.aws.amazon.com/glue/latest/dg/console-jobs.html)」し、次のステップを完了してジョブを設定します。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/generate-test-data-using-an-aws-glue-job-and-python.html) | アプリ開発者 |
| ジョブのコードを更新する。 | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/generate-test-data-using-an-aws-glue-job-and-python.html) | アプリ開発者 |
### コマンドラインまたはコンソールから AWS Glue ジョブを実行する
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| コマンドラインから AWS Glue ジョブの実行を行います。 | AWS Glue ジョブの実行を AWS CLI から実行するには、指定した値を使用して次のコマンドを実行します。cmd:~$ aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"0","--END_RANGE":"1000000"}'
cmd:~$ aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"1000000","--END_RANGE":"2000000"}'AWS マネジメントコンソールから AWS Glue ジョブを実行する手順については、このパターンの「*AWS マネジメントコンソールで AWS Glue ジョブを実行します*」ストーリーを参照してください。上記の例のように、異なるパラメータで一度に複数の実行を実行する場合は、AWS CLI を使用して AWS Glue ジョブを実行することをお勧めします。
特定の並列化係数を使用して定義済みの数のファイルを生成するために必要なすべての AWS CLI コマンドを生成するには、次の bash コードを (指定した値を使用して) 実行します。# define parameters
NUMBER_OF_FILES=10000000;
PARALLELIZATION=50;
# initialize
_SB=0;
# generate commands
for i in $(seq 1 $PARALLELIZATION);
do
echo aws glue start-job-run --job-name create_small_files --arguments "'"'{"--START_RANGE":"'$(((NUMBER_OF_FILES/PARALLELIZATION) * (i-1) + _SB))'","--END_RANGE":"'$(((NUMBER_OF_FILES/PARALLELIZATION) * (i)))'"}'"'";
_SB=1;
done
上記のスクリプトを使用する場合は、次の点を考慮してください。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/generate-test-data-using-an-aws-glue-job-and-python.html) 上記のスクリプトの出力例については、このパターンの「*追加情報*」セクションにある「*シェルスクリプト出力*」を参照してください。 | アプリ開発者 |
| AWS マネジメントコンソールで AWS Glue ジョブを実行します。 | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/generate-test-data-using-an-aws-glue-job-and-python.html) | アプリ開発者 |
| AWS Glue ジョブのステータスを確認します。 | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/generate-test-data-using-an-aws-glue-job-and-python.html) | アプリ開発者 |
## 関連リソース
**リファレンス**
+ 「[Registry of Open Data on AWS](https://registry.opendata.aws/)」
+ 「[分析用データセット](https://aws.amazon.com/marketplace/solutions/data-analytics/data-sets)」
+ 「[AWS のオープンデータ](https://aws.amazon.com/opendata/)」
+ 「[AWS Glue でのジョブ追加](https://docs.aws.amazon.com/glue/latest/dg/add-job.html)」
+ 「[AWS Glue の使用開始](https://aws.amazon.com/glue/getting-started/)」
**ガイドとパターン**
+ 「[AWS Glue のベストプラクティス](https://docs.aws.amazon.com/prescriptive-guidance/latest/serverless-etl-aws-glue/best-practices.html)」
+ 「[アプリケーションの負荷テスト](https://docs.aws.amazon.com/prescriptive-guidance/latest/load-testing/welcome.html)」
## 追加情報
ベンチマークテスト
このパターンを使用して、ベンチマークテストの一環として、さまざまな並列化パラメーターを使用して 1,000 万個のファイルを生成しました。次のテーブルは、テストの出力を示しています。
|
|
| 並列化 | 1 回のジョブ実行で生成されるファイルの数 | ジョブ所要時間 | [Speed] (スピード) |
| --- |--- |--- |--- |
| 10 | 1,000,000 | 6 時間、40 分 | とても遅い |
| 50 | 200,000 件の | 80 分 | 中 |
| 100 | 100,000 | 40 分 | 高速 |
処理を速くしたい場合は、ジョブ設定で同時実行数を増やすことができます。要件に基づいてジョブ設定を簡単に調整できますが、AWS Glue サービスのクォータ制限があることに注意してください。詳細については、「[AWS Glue のエンドポイントとクォータ](https://docs.aws.amazon.com/general/latest/gr/glue.html)」を参照してください。
シェルスクリプト出力
次の例は、このパターンの「*コマンドラインから AWS Glue ジョブの実行を行います*」ストーリーのシェルスクリプトの出力を示しています。
```
user@MUC-1234567890 MINGW64 ~
$ # define parameters
NUMBER_OF_FILES=10000000;
PARALLELIZATION=50;
# initialize
_SB=0;
# generate commands
for i in $(seq 1 $PARALLELIZATION);
do
echo aws glue start-job-run --job-name create_small_files --arguments "'"'{"--START_RANGE":"'$(((NUMBER_OF_FILES/PARALLELIZATION) (i-1) + SB))'","--ENDRANGE":"'$(((NUMBER_OF_FILES/PARALLELIZATION) (i)))'"}'"'";
_SB=1;
done
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"0","--END_RANGE":"200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"200001","--END_RANGE":"400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"400001","--END_RANGE":"600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"600001","--END_RANGE":"800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"800001","--END_RANGE":"1000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"1000001","--END_RANGE":"1200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"1200001","--END_RANGE":"1400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"1400001","--END_RANGE":"1600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"1600001","--END_RANGE":"1800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"1800001","--END_RANGE":"2000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"2000001","--END_RANGE":"2200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"2200001","--END_RANGE":"2400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"2400001","--END_RANGE":"2600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"2600001","--END_RANGE":"2800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"2800001","--END_RANGE":"3000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"3000001","--END_RANGE":"3200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"3200001","--END_RANGE":"3400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"3400001","--END_RANGE":"3600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"3600001","--END_RANGE":"3800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"3800001","--END_RANGE":"4000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"4000001","--END_RANGE":"4200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"4200001","--END_RANGE":"4400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"4400001","--END_RANGE":"4600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"4600001","--END_RANGE":"4800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"4800001","--END_RANGE":"5000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"5000001","--END_RANGE":"5200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"5200001","--END_RANGE":"5400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"5400001","--END_RANGE":"5600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"5600001","--END_RANGE":"5800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"5800001","--END_RANGE":"6000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"6000001","--END_RANGE":"6200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"6200001","--END_RANGE":"6400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"6400001","--END_RANGE":"6600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"6600001","--END_RANGE":"6800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"6800001","--END_RANGE":"7000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"7000001","--END_RANGE":"7200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"7200001","--END_RANGE":"7400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"7400001","--END_RANGE":"7600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"7600001","--END_RANGE":"7800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"7800001","--END_RANGE":"8000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"8000001","--END_RANGE":"8200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"8200001","--END_RANGE":"8400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"8400001","--END_RANGE":"8600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"8600001","--END_RANGE":"8800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"8800001","--END_RANGE":"9000000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"9000001","--END_RANGE":"9200000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"9200001","--END_RANGE":"9400000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"9400001","--END_RANGE":"9600000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"9600001","--END_RANGE":"9800000"}'
aws glue start-job-run --job-name create_small_files --arguments '{"--START_RANGE":"9800001","--END_RANGE":"10000000"}'
user@MUC-1234567890 MINGW64 ~
```
**よくある質問**
同時実行または並列ジョブはいくつ使用すべきですか?
同時実行数と並行ジョブ数は、所要時間と必要なテストファイル数によって異なります。作成するファイルのサイズを確認することをお勧めします。まず、AWS Glue ジョブが希望する数のファイルを生成するのにかかる時間を確認します。次に、目標に合わせて適切な数の同時実行を行います。たとえば、100,000 ファイルの実行が完了するまでに 40 分かかるが、目標時間が 30 分であると仮定した場合、AWS Glue ジョブの同時実行設定を増やす必要があります。
このパターンではどのようなコンテンツを作成できますか?
区切り文字が異なるテキストファイル (PIPE、JSON、CSV など) など、あらゆる種類のコンテンツを作成できます。このパターンでは、Boto3 を使用してファイルに書き込み、そのファイルを S3 バケットに保存します。
S3 バケットにはどのレベルの IAM 権限が必要ですか?
S3 バケット内のオブジェクトへの `Write` アクセスを許可する ID ベースのポリシーが必要です。詳細については、Amazon S3 ドキュメントの「[Amazon S3: S3 バケットのオブジェクトへの読み取りおよび書き込みのアクセス許可](https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_examples_s3_rw-bucket.html)」を参照してください。