翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Quick Sight で AWS Mainframe Modernization と Amazon Q を使用して Db2 z/OS データインサイトを生成する
Amazon Web Services、Shubham Roy、Roshna Razack、Santosh Kumar Singh
概要
注: AWS Mainframe Modernization サービス (マネージドランタイム環境エクスペリエンス) は、新規のお客様に公開されなくなりました。 AWS Mainframe Modernization サービス (マネージドランタイム環境エクスペリエンス) と同様の機能については、 AWS Mainframe Modernization サービス (セルフマネージドエクスペリエンス) をご覧ください。既存のお客様は、通常どおりサービスを引き続き使用できます。詳細については、「AWS Mainframe Modernization 可用性の変更」を参照してください。
組織がビジネスクリティカルなデータを IBM Db2 メインフレーム環境でホストしている場合、そのデータからインサイトを得ることは、成長とイノベーションを促進するために不可欠です。メインフレームデータをロック解除することで、迅速、安全、スケーラブルなビジネスインテリジェンスを構築し、Amazon Web Services (AWS) クラウドでデータ駆動型の意思決定、成長、イノベーションを加速することができます。
このパターンでは、ビジネスインサイトを生成し、IBM Db2 for z/OS テーブル内のメインフレームデータから共有可能な説明文を作成するためのソリューションを示します。メインフレームデータの変更は、AWS Mainframe Modernization Data Replication with Precisely を使用して Amazon Managed Streaming for Apache Kafka (Amazon MSK) トピックにストリーミングされます。Amazon Redshift ストリーミング取り込みを使用すると、Amazon MSK トピックデータは Amazon Quick Sight での分析のために Amazon Redshift Serverless データウェアハウステーブルに保存されます。
Quick Sight でデータが利用可能になったら、Amazon Q in Quick Sight で自然言語プロンプトを使用して、データの概要を作成し、質問し、データストーリーを生成することができます。SQL クエリを記述したり、ビジネスインテリジェンス (BI) ツールを学習したりする必要はありません。
ビジネスコンテキスト
このパターンでは、メインフレームデータ分析とデータインサイトのユースケースのソリューションを示します。パターンを使用して、会社のデータのビジュアルダッシュボードを構築します。このソリューションを実証するために、このパターンでは、米国のメンバーに医療的、歯科的、眼科的なプランを提供する医療会社を使用しています。この例では、メンバーの人口統計データとプラン情報が IBM Db2 for z/OS データテーブルに保存されます。ビジュアルダッシュボードでは以下について確認できます。
リージョン別のメンバーの分布
性別別のメンバーの分布
年齢別のメンバーの分布
プランタイプ別のメンバーの分布
予防接種を完了していないメンバー
リージョン別のメンバーの分布と、予防接種を完了していないメンバーの例については、「追加情報」セクションを参照してください。
ダッシュボードを作成したら、前の分析からのインサイトを示すデータストーリーを生成します。データストーリーでは、予防接種を完了したメンバーの数を増やすための推奨事項を提供します。
前提条件と制限
前提条件
アクティブ AWS アカウント。このソリューションは、Amazon Elastic Compute Cloud (Amazon EC2) の Amazon Linux 2 で構築およびテストされました。
サブネットを持つ仮想プライベートクラウド (VPC) にメインフレームシステムからアクセスできること。
ビジネスデータを含むメインフレームデータベース。このソリューションの構築とテストに使用されるデータの例については、「添付ファイル」セクションを参照してください。
Db2 z/OS テーブルで変更データキャプチャ (CDC) が有効になっていること。Db2 z/OS で CDC を有効にするには、IBM のドキュメント
を参照してください。 ソースデータベースをホストしている z/OS システムに Precisely Connect CDC for z/OS がインストールされていること。Precisely Connect CDC for z/OS イメージは、AWS Mainframe Modernization – Data Replication for IBM z/OS
Amazon マシンイメージ (AMI) 内の zip ファイルとして提供されます。Precisely Connect CDC for z/OS をメインフレームにインストールするには、Precisely のインストールドキュメント を参照してください。
制限事項
メインフレーム Db2 データは、Precisely Connect CDC でサポートされているデータ型である必要があります。サポートされているデータ型のリストについては、Precisely Connect CDC のドキュメント
を参照してください。 Amazon MSK のデータは、Amazon Redshift でサポートされているデータ型である必要があります。サポートされているデータ型のリストについては、Amazon Redshift のドキュメントを参照してください。
Amazon Redshift には、データ型ごとに異なる動作とサイズ制限があります。詳細については、Amazon Redshift のドキュメントを参照してください。
Quick Sight のほぼリアルタイムのデータは、Amazon Redshift データベースに設定された更新間隔によって異なります。
一部の AWS のサービス は、すべてで利用できるわけではありません AWS リージョン。リージョンの可用性については、「AWS のサービス (リージョン別)
」を参照してください。Amazon Q in Quick Sight は現在、Quick Sight をサポートするすべてのリージョンで利用できるわけではありません。特定のエンドポイントについて確認するには、「Service endpoints and quotas」ページを参照し、サービスのリンクを選択してください。
製品バージョン
AWS Mainframe Modernization Precisely バージョン 4.1.44 によるデータレプリケーション
Python バージョン 3.6 以降
Apache Kafka バージョン 3.5.1
アーキテクチャ
ターゲットアーキテクチャ
次の図に、AWS Mainframe Modernization Data Replication with Precisely
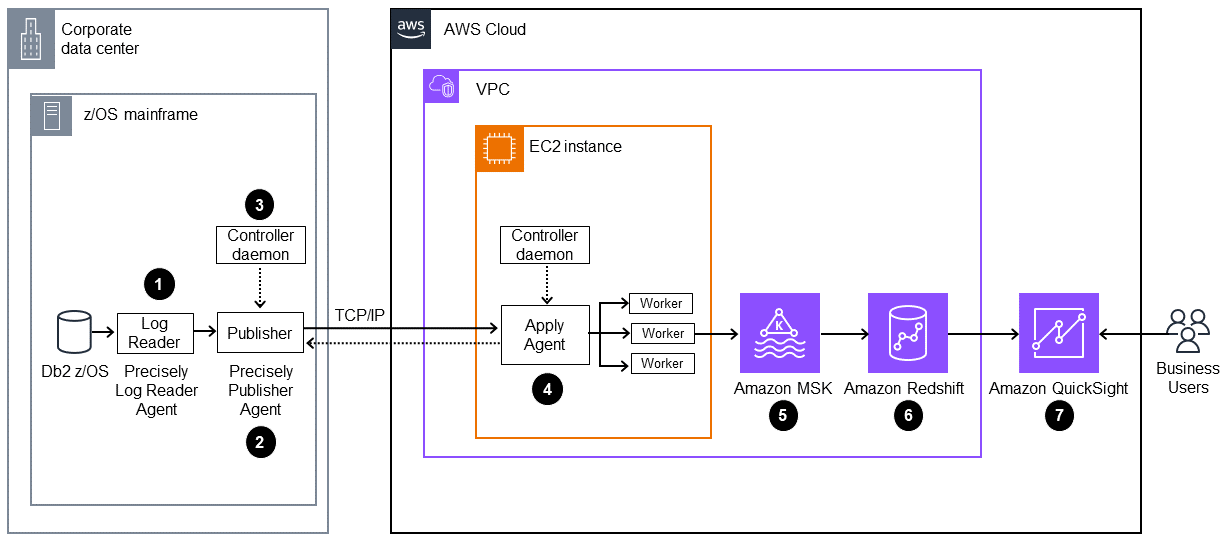
この図表は、次のワークフローを示しています:
Precisely ログリーダーエージェントが Db2 ログからデータを読み取り、メインフレームの OMVS ファイルシステムの一時ストレージに書き込みます。
パブリッシャーエージェントが一時ストレージから未処理の Db2 ログを読み取ります。
オンプレミスコントローラーデーモンが、オペレーションの認証、認可、モニタリング、管理を行います。
事前設定された AMI を使用して、Apply エージェントが Amazon EC2 にデプロイされます。TCP/IP を使用し、コントローラーデーモンを介してパブリッシャーエージェントに接続されます。Apply エージェントは、高スループットを実現するため、複数のワーカーを使用してデータを Amazon MSK にプッシュします。
ワーカーが、データを JSON 形式で Amazon MSK トピックに書き込みます。レプリケートされたメッセージの中間ターゲットとして、Amazon MSK は高可用性と自動フェイルオーバー機能を備えています。
Amazon Redshift ストリーミング取り込み機能により、Amazon MSK から Amazon Redshift Serverless データベースへの高速・低遅延のデータインジェストを実行します。Amazon Redshift のストアドプロシージャは、Amazon Redshift テーブルへのメインフレームデータの変更 (挿入/更新/削除) を調整します。これらの Amazon Redshift テーブルは、Quick Sight のためのデータ分析ソースとして機能します。
ユーザーが、分析とインサイトのために Quick Sight のデータにアクセスします。Amazon Q in Quick Sight を使用して、自然言語プロンプトを使用してデータを操作できます。
ツール
AWS のサービス
Amazon Elastic Compute Cloud (Amazon EC2) は、 AWS クラウドでスケーラブルなコンピューティング容量を提供します。必要な数の仮想サーバーを起動し、迅速なスケールアップおよびスケールダウンができます。
AWS Key Management Service (AWS KMS) は、データの保護に役立つ暗号化キーの作成と制御に役立ちます。
「Amazon Managed Streaming for Apache Kafka (Amazon MSK)」 は、Apache Kafka を使ってストリーミングデータを処理するアプリケーションを、構築および実行することを支援するフルマネージドサービスです。
Amazon QuickSight は、視覚化、分析、レポート生成に使用できるクラウドスケールのビジネスインテリジェンス (BI) サービスです。このパターンでは、Amazon Q in Quick Sight の生成 BI 機能を使用します。
Amazon Redshift Serverless
は Amazon Redshift のサーバーレスオプションであり、データウェアハウスインフラストラクチャの設定と管理を行わなくても、数秒で分析の実行とスケーリングをより効率的に行うことができます。 AWS Secrets Manager を使用すると、コード内のハードコードされた認証情報 (パスワードを含む) を Secrets Manager への API コールで置き換えて、プログラムでシークレットを取得することができます。
その他のツール
Precisely Connect CDC
は、レガシーシステムからデータを収集し、クラウドおよびデータプラットフォームに統合します。
コードリポジトリ
このパターンのコードは、GitHub 内の 「Mainframe_DataInsights_change_data_reconciliation
ベストプラクティス
Amazon MSK クラスターをセットアップするときは、ベストプラクティスに従ってください。
パフォーマンスを改善するには、Amazon Redshift の「パフォーマンス改善に向けたデータ解析のベストプラクティス」に従ってください。
Precisely セットアップ用の AWS Identity and Access Management (IAM) ロールを作成するときは、最小特権の原則に従い、タスクの実行に必要な最小限のアクセス許可を付与します。詳細については、IAM ドキュメントの「最小限の特権を認める。」と「IAM でのセキュリティのベストプラクティス」を参照してください。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
セキュリティグループをセットアップする。 | コントローラーデーモンと Amazon MSK クラスターに接続するには、EC2 インスタンス用のセキュリティグループを作成します。以下のインバウンドルールおよびアウトバウンドルールを追加します。
セキュリティグループの名前を書き留めておきます。この名前は、EC2 インスタンスを起動し、Amazon MSK クラスターを設定するときに参照する必要があります。 | DevOps エンジニア、AWS DevOps |
IAM ポリシーと IAM ロールを作成する。 |
| DevOps エンジニア、AWS システム管理者 |
EC2 インスタンスをプロビジョニングする。 | Precisely CDC を実行して Amazon MSK に接続するように EC2 インスタンスをプロビジョニングするには、次の手順を実行します。
| AWS 管理者、DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Amazon MSK クラスターを作成します。 | Amazon MSK クラスターを作成するには、次の手順を実行します。
一般的なプロビジョニング済みクラスターの作成には最大 15 分かかります。クラスターが作成されると、そのステータスは作成中からアクティブに変わります。 | AWS DevOps、クラウド管理者 |
SASL/SCRAM 認証をセットアップする。 | Amazon MSK クラスターの SASL/SCRAM 認証をセットアップするには、次の手順を実行します。
| クラウドアーキテクト |
Amazon SNS トピックを作成する。 | Amazon MSK トピックを作成するには、次の手順を実行します。
| クラウド管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
データ変更をレプリケートするように Precisely スクリプトをセットアップする。 | 変更されたデータをメインフレームから Amazon MSK トピックにレプリケートするように Precisely Connect CDC スクリプトをセットアップするには、次の手順を実行します。
.ddl ファイルの例は、「追加情報」セクションを参照してください。 | アプリ開発者、クラウドアーキテクト |
ネットワーク ACL キーを生成する。 | ネットワークアクセスコントロールリスト (ネットワーク ACL) キーを生成するには、次の手順を実行します。
| クラウドアーキテクト、AWS DevOps |
| タスク | 説明 | 必要なスキル |
|---|---|---|
ISPF 画面でデフォルトを設定する。 | Interactive System Productivity Facility (ISPF) でデフォルト設定を設定するには、Precisely ドキュメント | メインフレームシステム管理者 |
コントローラーデーモンを設定する。 | コントローラーデーモンを設定するには、以下を実行します。
| メインフレームシステム管理者 |
Configure the publisher。 | パブリッシャーを設定するには、次の手順を実行します。
| メインフレームシステム管理者 |
デーモン設定ファイルを更新する。 | コントローラーデーモン設定ファイルのパブリッシャーの詳細を更新するには、次の手順を実行します。
| メインフレームシステム管理者 |
コントローラーデーモンを開始するジョブを作成する。 | ジョブを作成するには、以下の手順を実行します。
| メインフレームシステム管理者 |
キャプチャパブリッシャー JCL ファイルを生成する。 | キャプチャパブリッシャー JCL ファイルを生成するには、次の手順を実行します。
| メインフレームシステム管理者 |
CDC を確認して更新する。 |
| メインフレームシステム管理者 |
JCL ファイルを送信する。 | 前のステップで設定した次の JCL ファイルを送信します。
JCL ファイルが送信されれば、EC2 インスタンスで Precisely の Apply Engine を起動できるようになります。 | メインフレームシステム管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Apply Engine を起動し、CDC を検証する。 | EC2 インスタンスで Apply Engine を起動し、CDC を検証するには、次の手順を実行します。
| クラウドアーキテクト、アプリ開発者 |
Amazon MSK トピックのレコードを検証する。 | Kafka トピックからメッセージを読み取るには、次の手順を実行します。
| アプリ開発者、クラウドアーキテクト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Amazon Redshift Serverless を設定する。 | Amazon Redshift Serverless データウェアハウスを作成するには、AWS ドキュメントの指示に従います。 Amazon Redshift Serverless ダッシュボードで、名前空間とワークグループが作成され、使用可能であることを確認します。このパターン例では、プロセスに 2~5 分かかる場合があります。 | データエンジニア |
ストリーミング取り込みに必要な IAM ロールと信頼ポリシーをセットアップする。 | Amazon MSK からの Amazon Redshift Serverless ストリーミング取り込みをセットアップするには、次の手順を実行します。
| データエンジニア |
Amazon Redshift Serverless を Amazon MSK に接続する。 | Amazon MSK トピックに接続するには、Amazon Redshift Serverless で外部スキーマを作成します。Amazon Redshift Query Editor V2 で、次の SQL コマンドを実行します。
| 移行エンジニア |
マテリアライズドビューを作成する。 | Amazon Redshift Serverless で Amazon MSK トピックのデータを使用するには、マテリアライズドビューを作成します。Amazon Redshift Query Editor V2 で、次の SQL コマンドを実行します。
| 移行エンジニア |
Amazon Redshift でターゲットテーブルを作成する。 | Amazon Redshift テーブルは、Quick Sight の入力となります。このパターンでは、メインフレームのソース Db2 テーブルと一致するテーブル Amazon Redshift で 2 つのテーブルを作成するには、Amazon Redshift Query Editor V2 で次の SQL コマンドを実行します。
| 移行エンジニア |
Amazon Redshift でストアドプロシージャを作成して保存する。 | このパターンでは、ストアドプロシージャを使用して、Quick Sight での分析のために、ソースメインフレームからターゲット Amazon Redshift データウェアハウステーブルに変更データ ( Amazon Redshift でストアドプロシージャを作成するには、Query Editor v2 を使用して、GitHub リポジトリにあるストアドプロシージャコードを実行します。 | 移行エンジニア |
ストリーミングマテリアライズドビューから読み取り、ターゲットテーブルにロードする。 | ストアドプロシージャは、ストリーミングマテリアライズドビューからデータ変更を読み取り、ターゲットテーブルにロードします。ストアドプロシージャを実行するには、次のコマンドを実行します。
Amazon EventBridge もう 1 つのオプションは、Amazon Redshift Query Editor V2 を使用して更新をスケジュールすることです。詳細については、「クエリエディタ v2 でスケジュールされたクエリ」を参照してください。 | 移行エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Quick Sight をセットアップする。 | Quick Sight をセットアップするには、AWS ドキュメントの指示に従います。 | 移行エンジニア |
Quick Sight と Amazon Redshift 間の安全な接続をセットアップする。 | Quick Sight と Amazon Redshift 間の安全な接続をセットアップするには、次の手順を実行します。
| 移行エンジニア |
Quick Sight のデータセットを作成する。 | Amazon Redshift から Quick Sight のデータセットを作成するには、次の手順を実行します。
| 移行エンジニア |
データセットを結合する。 | Quick Sight で分析を作成するには、AWS ドキュメントの指示に従って 2 つのテーブルを結合します。 [結合設定] ペインで、[結合タイプ] に [左] を選択します。[結合句] で、 | 移行エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Amazon Q in Quick Sight を設定する。 | Amazon Q in Quick Sight の生成 BI 機能をセットアップするには、AWS ドキュメントの指示に従います。 | 移行エンジニア |
メインフレームデータを分析し、ビジュアルダッシュボードを構築する。 | Quick Sight でデータを分析および視覚化するには、以下を実行します。
それらが完了したら、ダッシュボードを公開して、組織内の他のユーザーと共有することができます。例については、「追加情報」セクションの「メインフレームビジュアルダッシュボード」を参照してください。 | 移行エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
データストーリーを作成する。 | 前の分析からのインサイトを説明するデータストーリーを作成し、メンバーの予防接種を促進するための推奨事項を生成します。
| 移行エンジニア |
生成されたデータストーリーを表示する。 | 生成されたデータストーリーを表示するには、[データストーリー] ページでそのストーリーを選択します。 | 移行エンジニア |
生成されたデータストーリーを編集する。 | データストーリーのフォーマット、レイアウト、ビジュアルを変更するには、AWS ドキュメントの指示に従います。 | 移行エンジニア |
データストーリーを共有する。 | データストーリーを共有するには、AWS ドキュメントの指示に従います。 | 移行エンジニア |
トラブルシューティング
| 問題 | ソリューション |
|---|---|
Quick Sight から Amazon Redshift へのデータセットの作成で、 |
|
EC2 インスタンスで Apply Engine を起動しようとすると、次のエラーが返される。
| 次のコマンドを実行して、
|
Apply Engine を起動しようとすると、次のいずれかの接続エラーが返される。
| メインフレームスプールをチェックして、コントローラーデーモンジョブが実行されていることを確認してください。 |
関連リソース
追加情報
.ddl ファイルの例
members_details.ddl
CREATE TABLE MEMBER_DTLS ( memberid INTEGER NOT NULL, member_name VARCHAR(50), member_type VARCHAR(20), age INTEGER, gender CHAR(1), email VARCHAR(100), region VARCHAR(20) );
member_plans.ddl
CREATE TABLE MEMBER_PLANS ( memberid INTEGER NOT NULL, medical_plan CHAR(1), dental_plan CHAR(1), vision_plan CHAR(1), preventive_immunization VARCHAR(20) );
.sqd ファイルの例
<kafka topic name> は Amazon MSK トピック名に置き換えてください。
script.sqd
-- Name: DB2ZTOMSK: DB2z To MSK JOBNAME DB2ZTOMSK;REPORT EVERY 1;OPTIONS CDCOP('I','U','D');-- Source Descriptions JOBNAME DB2ZTOMSK; REPORT EVERY 1; OPTIONS CDCOP('I','U','D'); -- Source Descriptions BEGIN GROUP DB2_SOURCE; DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_details.ddl AS MEMBER_DTLS; DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_plans.ddl AS MEMBER_PLANS; END GROUP; -- Source Datastore DATASTORE cdc://<zos_host_name>/DB2ZTOMSK/DB2ZTOMSK OF UTSCDC AS CDCIN DESCRIBED BY GROUP DB2_SOURCE ; -- Target Datastore(s) DATASTORE 'kafka:///<kafka topic name>/key' OF JSON AS TARGET DESCRIBED BY GROUP DB2_SOURCE; PROCESS INTO TARGET SELECT { REPLICATE(TARGET) } FROM CDCIN;
メインフレームビジュアルダッシュボード
次のデータビジュアルは、分析の質問 show member distribution by region のために Amazon Q in Quick Sight によって作成されました。
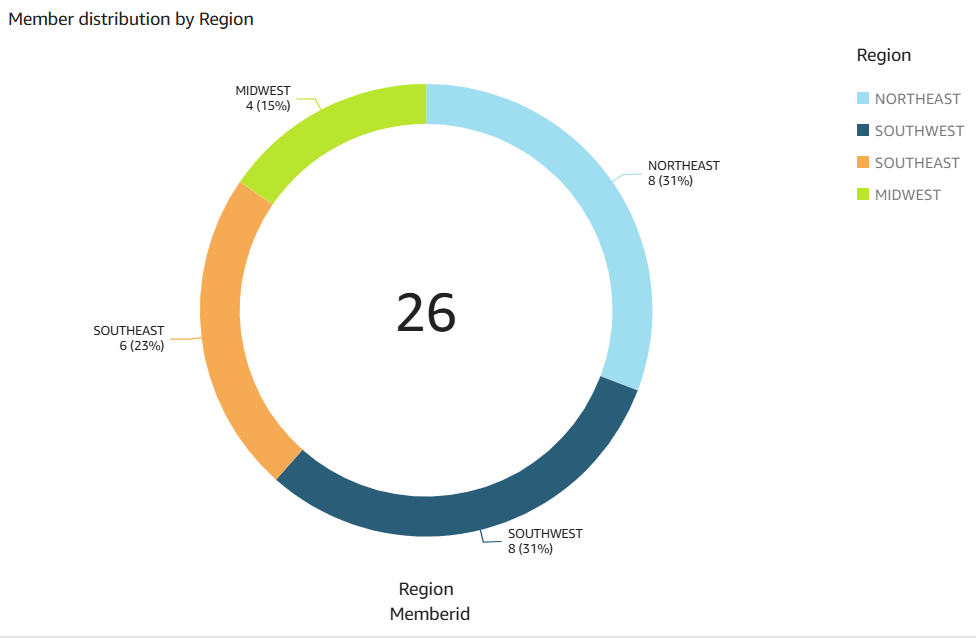
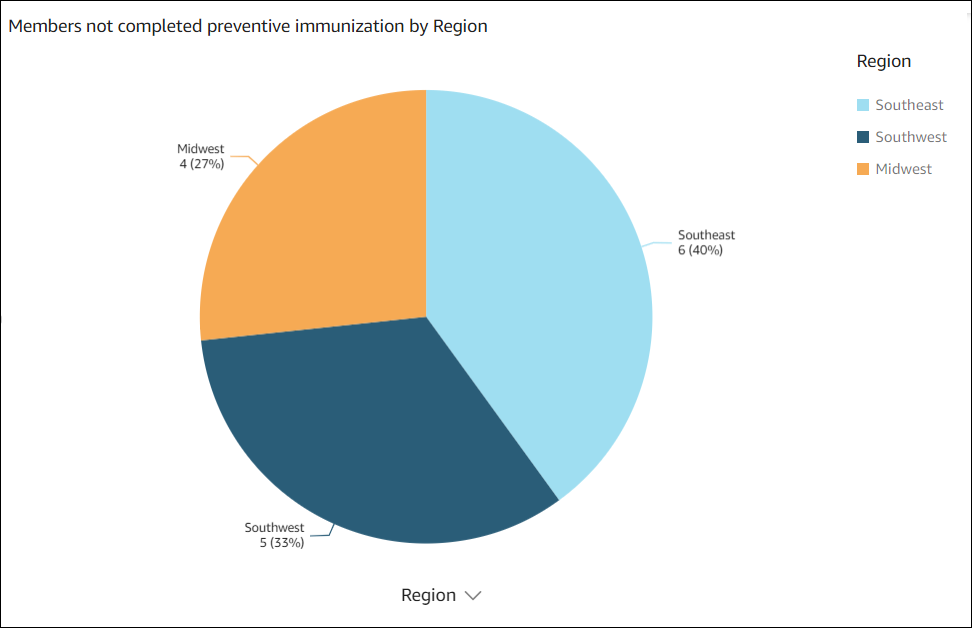
次のデータビジュアルは、質問 show member distribution by Region who have not completed preventive immunization, in pie chart のために Amazon Q in Quick Sight によって作成されました。
データストーリーの出力
次のスクリーンショットに、プロンプト Build a data story about Region with most numbers of members. Also show the member distribution by age, member distribution by gender. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern のために Amazon Q in Quick Sight によって作成されたデータストーリーのセクションを示します。
概要でデータストーリーにより推奨されているのは、予防接種の取り組みから最大の効果を得られるようにメンバー数が最も多い地域を選択することです。

データストーリーでは、4 つのリージョンのメンバー数の分析を示します。メンバーが多いのは、北東部、南西部、および南東部リージョンです。

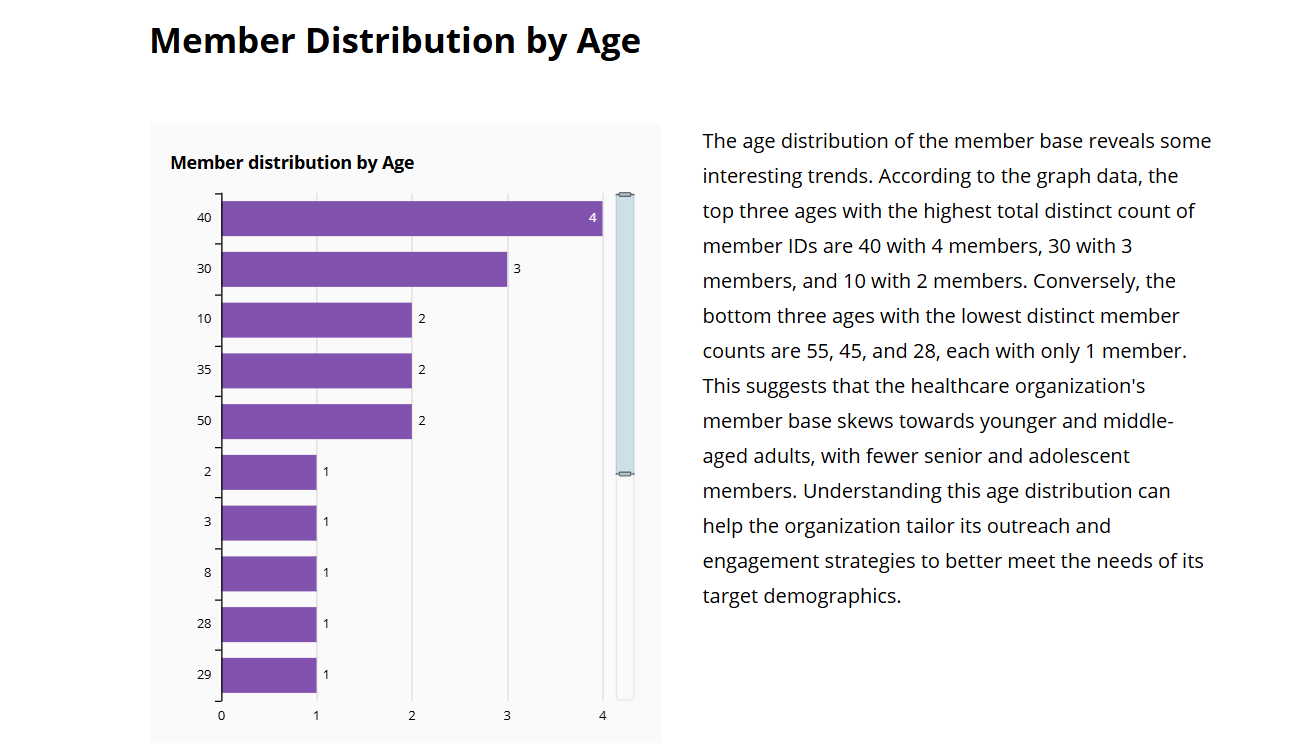
データストーリーは、年齢別のメンバーの分析を示しています。
データストーリーは、中西部での予防接種の取り組みに焦点を当てています。


アタッチメント
このドキュメントに関連付けられている追加のコンテンツにアクセスするには、添付ファイルをダウンロードして解凍します。zip
