翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Athena と Amazon Quick Sight を使用してネストされた JSON データを分析および視覚化する
Amazon Web Services、Anoop Singh
概要
このパターンでは、Amazon Athena を使用してネストされた JSON 形式のデータ構造を表形式ビューに変換し、Amazon Quick Sight でデータを視覚化する方法について説明します。
オペレーションシステムから得られた、API を活用したデータフィードに JSON 形式のデータを使用することで、データプロダクトを作成できます。また、このデータは顧客が製品をどのように使用しているのかを深く理解することにも役立ち、ユーザーエクスペリエンスを調整したり結果を予測したりできます。
前提条件と制限
前提条件
アクティブな AWS アカウント
ネストされたデータ構造を表す JSON ファイル (このパターンではサンプルファイルを使用)
機能制限:
JSON 機能は、Athena の既存の SQL 指向関数と十分に統合されています。ただし、これらは ANSI SQL 互換ではなく、JSON ファイルは各レコードを個別の行に格納することが想定されています。Athena の
ignore.malformed.jsonプロパティを使用して、不正な形式の JSON レコードを null 文字に変換するか、エラーを生成するかを示す必要がある場合があります。詳細については、Athena ドキュメントの「Best practices for reading JSON data」を参照してください。本パターンでは、JSON 形式の単純かつ少量のデータのみを取り上げます。これらの概念を大規模に使用する場合は、データのパーティショニングを適用し、データをより大きなファイルに統合することを検討します。
アーキテクチャ
次の図は、本パターンのアーキテクチャとワークフローを示したものです。ネストされたデータ構造は、Amazon Simple Storage Service (Amazon S3) に JSON 形式で保存されます。Athena では、JSON データは Athena データ構造にマッピングされます。次に、データを分析するためのビューを作成し、Quick Sight でデータ構造を視覚化します。
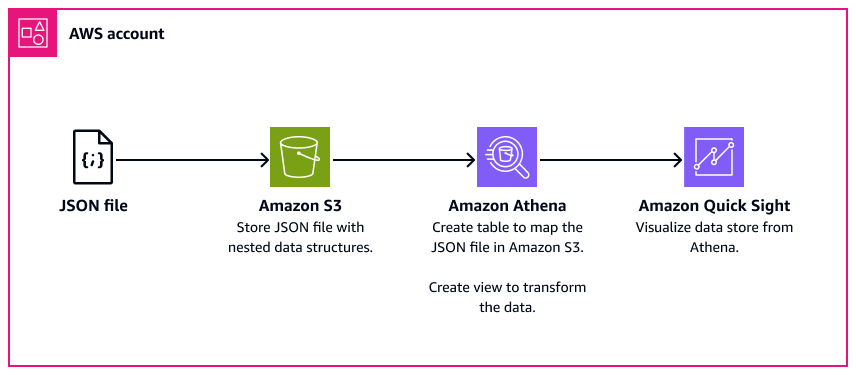
ツール
AWS サービス
Amazon Simple Storage Service (Amazon S3) は、量にかかわらず、データを保存、保護、取得するのに役立つクラウドベースのオブジェクトストレージサービスです。本パターンでは、Amazon S3 を使用して JSON ファイルを保存します。
Amazon Athena は、標準 SQL を使用して Amazon S3 でデータを直接分析するのに役立つ対話型のクエリサービスです。本パターンでは、JSON データのクエリと変換に Athena を使用します。でいくつかのアクションを使用すると AWS マネジメントコンソール、Amazon S3 のデータに Athena をポイントし、標準 SQL を使用して 1 回限りのクエリを実行できます。Athena はサーバーレスであるため、インフラストラクチャの設定や管理は不要です。また、実行したクエリにのみ課金されます。Athena は、自動的にスケールしてクエリを並列実行するため、大規模なデータベースや複合型のクエリでも結果がすぐに返されます。
Amazon Quick Sight は、単一のダッシュボードでデータを視覚化、分析、レポートするのに役立つクラウドスケールのビジネスインテリジェンス (BI) サービスです。Quick Sight を使用すると、機械学習 (ML) インサイトを含むインタラクティブなダッシュボードを簡単に作成して公開できます。どのデバイスからでもダッシュボードにアクセスし、アプリケーション、ポータル、ウェブサイトに埋め込むことができます。
コードの例
次の JSON ファイルは、本パターンで使用できるネストされたデータ構造を提供します。
{ "symbol": "AAPL", "financials": [ { "reportDate": "2017-03-31", "grossProfit": 20591000000, "costOfRevenue": 32305000000, "operatingRevenue": 52896000000, "totalRevenue": 52896000000, "operatingIncome": 14097000000, "netIncome": 11029000000, "researchAndDevelopment": 2776000000, "operatingExpense": 6494000000, "currentAssets": 101990000000, "totalAssets": 334532000000, "totalLiabilities": 200450000000, "currentCash": 15157000000, "currentDebt": 13991000000, "totalCash": 67101000000, "totalDebt": 98522000000, "shareholderEquity": 134082000000, "cashChange": -1214000000, "cashFlow": 12523000000, "operatingGainsLosses": null } ] }
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
S3 バケットを作成する。 | JSON ファイルを保存するバケットを作成するには、 にサインインし AWS マネジメントコンソール、Amazon S3 コンソール | システム管理者 |
ネストされた JSON データを追加します。 | JSON ファイルを S3 バケットにアップロードします。JSON ファイルのサンプルについては、前のセクションを参照してください。手順については、Amazon S3 ドキュメントの「オブジェクトのアップロード」を参照してください。 | システム管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
テーブルを作成して JSON データをマッピングします。 |
テーブルの作成の詳細については、Athena ドキュメントを参照してください。 | 開発者 |
データ分析用のビューを作成します。 |
ビューの作成の詳細については、Athena ドキュメントを参照してください。 | 開発者 |
データを分析して検証します。 |
| 開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Quick Sight で Athena をデータソースとして設定します。 |
| システム管理者 |
Quick Sight でデータを視覚化します。 |
| データアナリスト |
関連リソース
