翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
プールモデルマルチテナンシー
コストや運用上のオーバーヘッドにより、サイロモデルを実装する必要や実現不可能な場合があります。
-
テナントごとに個々のクラスターを維持するリソースがない可能性があります。
-
各テナントのデータを物理的に分離する必要はなく、論理的に分離するだけでニーズとコンプライアンス要件を満たすことができます。
次の図は、テナントデータが単一の Amazon Neptune クラスターに配置され、すべてのテナントが共通のデータベースを共有するプールモデルを示しています。
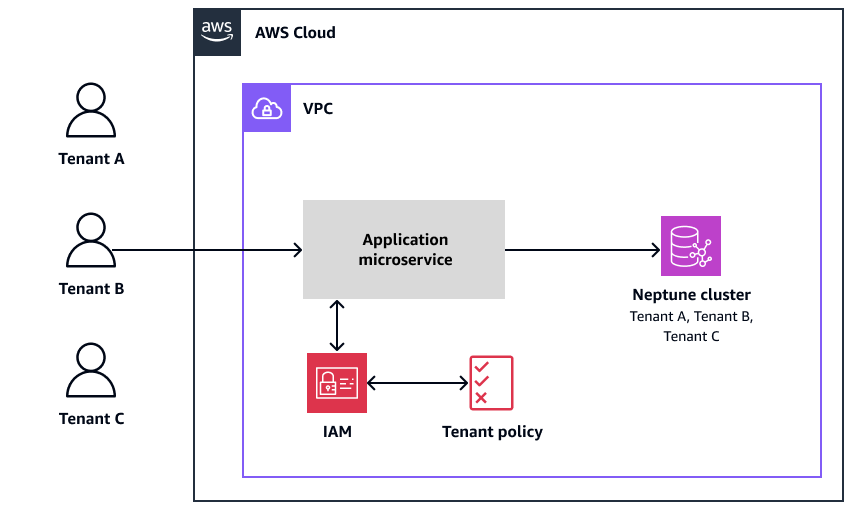
このプール分離モデルは、管理するクラスターが少ないため、管理オーバーヘッドを削減し、運用効率を向上させることができます。また、コンピューティングリソースは、顧客の非アクティブ期間中もアイドル状態のままではなく、複数の顧客間で共有できます。
プールモデルを使用する場合、データをモデル化する方法は 2 つあります。アプローチは、ラベル付きプロパティグラフ (LPG) を構築するか、リソース記述フレームワーク (RDF) を使用してグラフを構築するかによって異なります。
