翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ステージ 2: 大規模な移行の実装
大規模な移行のステージ 2 では、サーバーを大規模に移行することを目標としています。たとえば、6 か月で 1,000 台の サーバーを移行するには、まず 1 週間あたり 5 台の サーバーを移行してから、速度を 1 週間あたり 50~100 台の サーバーに徐々に増やすことができます。
次に、ステージ 1 で開発したランブックを使用して、サーバーをウェーブで移行します。移行ワークストリームとポートフォリオワークストリームはランブックのプロセスを採用および調整しているため、最初のいくつかのウェーブは通常小規模です。ランブックの改善は、大規模な移行を成功させるための鍵です。ランブックは生きているドキュメントです。カットオーバーのたびに、ランブックを確認、改訂、改善する必要があります。ランブックが時間の経過とともに進化するにつれて、速度は波ごとに増加します。
ステージ 2 では、次のコンポーネントを使用して移行ファクトリを運用します。
-
プロジェクトガバナンスルール – プロジェクトガバナンスプロセスに従って、ウェーブ、コミュニケーション、タイムライン、カットオーバーを管理します。これらのプロセスとツールにより、全員が適切なタイミングと順序で正しいことを行うことができます。
-
ポートフォリオランブック – ポートフォリオランブックを使用して、アプリケーションの優先順位付け、ウェーブの計画、移行をサポートする必要なメタデータの収集を行います。このメタデータは、製造工場の原材料と同等です。
-
移行ランブック – 移行ランブックを使用して、アプリケーションとサーバーを移行し、メタデータを移行ツールにロードし、各ウェーブの最後にカットオーバープロセスを完了します。移行ランブックに従うときは、ポートフォリオランブックのウェーブプランに従い、ポートフォリオランブックまたは別の信頼できるソースのメタデータを使用します。
-
大規模な移行のベストプラクティスとヘルスチェックマトリックス – ヘルスチェックマトリックスを使用して、現在の状態を頻繁に定期的に評価し、すべてが軌道に乗っていることを確認します。
次の図は、大規模な移行の一般的な移行工場を示しています。
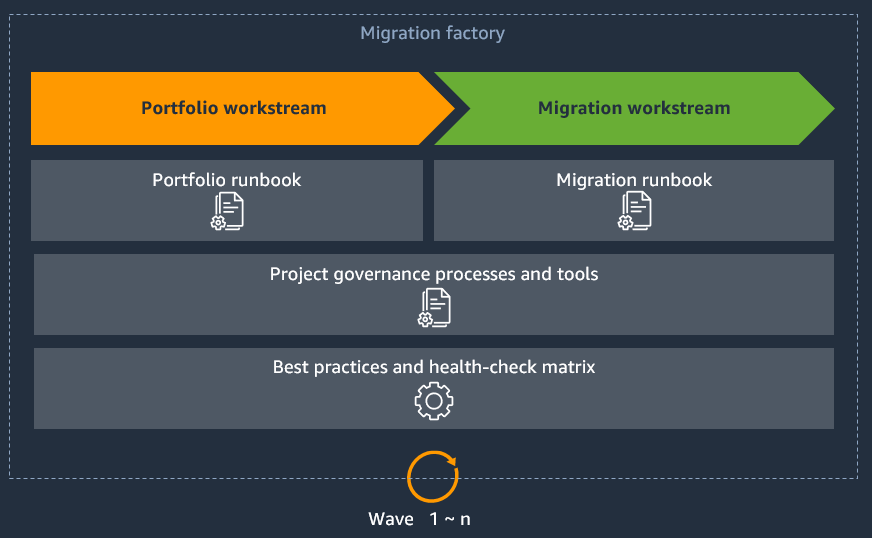
ランブックは移行ファクトリーの主要なコンポーネントであり、ポートフォリオと移行の 2 つのワークストリームを通じてデータフローを形成するために連携します。これらのワークストリームの詳細については、AWS 「大規模な移行のための Foundation プレイブック」を参照してください。チームは通常、移行ファクトリーを通じて波を見るのではなく、ファクトリーの特定の部分に専念し、波は各ワークストリームを流れます。各ワークストリームの期間は、プロジェクトのタイムライン、範囲、リソースの可用性によって異なります。たとえば、ポートフォリオワークストリームは 3 週間、移行ワークストリームは 2~5 週間です。移行用に十分なサーバーウェーブが準備されていることを確認することで、移行ファクトリーのサプライチェーンの問題を防止します。ポートフォリオワークストリームは、移行ワークストリームより 5 ウェーブ先になることをお勧めします。
次の図は、一般的な移行ファクトリーの動的ビューを示しています。ウェーブごとに、ポートフォリオワークストリームは 1~2 週間、移行ワークストリームは通常 3~4 週間実行されます。ポートフォリオワークストリームは移行ワークストリームより 5 波進んでいるため、ポートフォリオと移行ワークストリームの間には常に 5 波バッファがあります。移行ステージ 1 の初期化の最後に、ポートフォリオワークストリームは 5 つのウェーブのバッファのウェーブプランニングを完了します。移行ワークストリームがアプリケーションの移行を開始すると、ステージ 2 に入り、実装したことを示します。ポートフォリオと移行ワークストリームの両方が引き続きウェーブを処理し、バッファにより移行するサーバーが不足するのを防ぎます。

