翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データベース分解中のテーブル関係のデカップリング
このセクションでは、モノリシックデータベースの分解中に複雑なテーブル関係と JOIN オペレーションを分解するためのガイダンスを提供します。テーブル結合は、関連する列に基づいて 2 つ以上のテーブルの行を結合します。これらの関係を分離する目標は、マイクロサービス間でデータの整合性を維持しながら、テーブル間の高い結合を減らすことです。
このセクションは、以下のトピックで構成されます。
非正規化戦略
非正規化は、テーブル間でデータを結合または複製することで、意図的に冗長性を導入するデータベース設計戦略です。大規模なデータベースを小さなデータベースに分割する場合、サービス間で一部のデータを複製することは理にかなっている場合があります。例えば、名前や E メールアドレスなどの基本的な顧客の詳細をマーケティングサービスと注文サービスの両方に保存することで、サービス間の継続的な検索が不要になります。マーケティングサービスでは、キャンペーンターゲティングに顧客の好みと連絡先情報が必要になる場合がありますが、注文サービスでは注文処理と通知に同じデータが必要です。これによりデータの冗長性がある程度生じる一方で、サービスのパフォーマンスと独立性が大幅に向上するため、マーケティングチームはカスタマーサービスのリアルタイム検索に依存することなくキャンペーンを運用できます。
非正規化を実装するときは、データアクセスパターンを注意深く分析して識別する、頻繁にアクセスされるフィールドに焦点を当てます。Oracle AWR レポートや などのツールを使用してpg_stat_statements、一般的に一緒に取得されるデータを把握できます。ドメインエキスパートは、自然データのグループ化に関する貴重なインサイトを提供することもできます。非正規化はall-or-nothingのアプローチではなく、システムパフォーマンスを向上させたり、複雑な依存関係を減らしたりする重複データのみであることに注意してください。
Reference-by-key戦略
reference-by-key戦略は、実際の関連データを保存するのではなく、一意のキーを通じてエンティティ間の関係を維持するデータベース設計パターンです。従来の外部キー関係の代わりに、最新のマイクロサービスは多くの場合、関連するデータの一意の識別子のみを保存します。たとえば、注文テーブルにすべての顧客詳細を保持するのではなく、注文サービスは顧客 ID のみを保存し、必要に応じて API コールを通じて追加の顧客情報を取得します。このアプローチは、関連データへのアクセスを確保しながら、サービスの独立性を維持します。
CQRS パターン
コマンドクエリ責任分離 (CQRS) パターンは、データストアの読み取りオペレーションと書き込みオペレーションを分離します。このパターンは、高性能要件を持つ複雑なシステム、特に非対称読み取り/書き込みロードを持つシステムで特に役立ちます。アプリケーションが複数のソースからのデータを頻繁に組み合わせる必要がある場合は、複雑な結合の代わりに専用の CQRS モデルを作成できます。たとえば、すべてのリクエストで Product、、Pricingおよび Inventoryテーブルを結合するのではなく、必要なデータを含む統合Product Catalogテーブルを維持します。このアプローチの利点は、追加のテーブルのコストを上回る可能性があります。
Product、Price、および Inventoryのサービスが頻繁に製品情報を必要とするシナリオを考えてみましょう。共有テーブルに直接アクセスするようにこれらのサービスを設定する代わりに、専用Product Catalogサービスを作成します。このサービスは、統合された製品情報を含む独自のデータベースを保持します。製品関連のクエリの信頼できる単一のソースとして機能します。製品の詳細、価格、またはインベントリレベルが変更されると、各サービスはイベントを発行してProduct Catalogサービスを更新できます。これにより、サービスの独立性を維持しながらデータの一貫性が得られます。次の図は、Amazon EventBridge
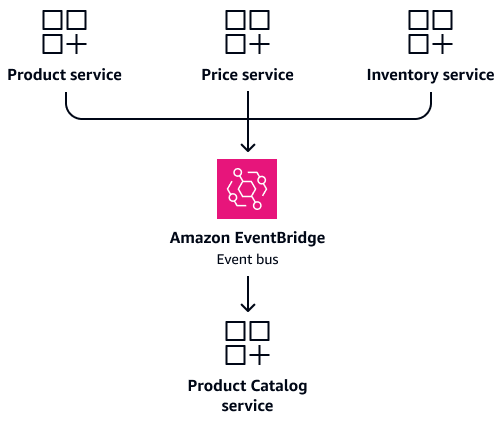
で説明されているようにイベントベースのデータ同期、次のセクションでは、イベントを通じて CQRS モデルを更新し続けます。製品の詳細、価格、またはインベントリレベルが変更されると、各サービスはイベントを発行します。Product Catalog サービスはこれらのイベントをサブスクライブし、統合ビューを更新します。これにより、複雑な結合なしで高速読み取りが可能になり、サービスの独立性が維持されます。
イベントベースのデータ同期
イベントベースのデータ同期は、データへの変更がキャプチャされ、イベントとして伝達されるパターンです。これにより、さまざまなシステムまたはコンポーネントが同期されたデータ状態を維持できます。データが変更されると、関連するすべてのデータベースをすぐに更新する代わりに、 イベントを発行して、サブスクライブされたサービスに通知します。例えば、顧客がCustomerサービスの配送先住所を変更すると、CustomerUpdatedイベントは各Orderサービスのスケジュールに従ってDeliveryサービスとサービスの更新を開始します。このアプローチは、リジッドテーブル結合を柔軟でスケーラブルなイベント駆動型更新に置き換えます。一部のサービスは一時的に古いデータを持っているかもしれませんが、トレードオフはシステムのスケーラビリティとサービスの独立性の向上です。
テーブル結合に代わる方法の実装
通常、データベースの分解は移行と検証が簡単なため、読み取りオペレーションで開始します。読み取りパスが安定したら、より複雑な書き込みオペレーションに取り組みます。重要で高性能な要件については、CQRS パターンの実装を検討してください。読み取りには最適化された別のデータベースを使用し、書き込みには別のデータベースを使用します。
クロスサービス呼び出しの再試行ロジックを追加し、適切なキャッシュレイヤーを実装することで、回復力のあるシステムを構築します。サービスのやり取りを注意深くモニタリングし、データ整合性の問題に関するアラートを設定します。最終目標は、どこにいても完全な一貫性ではありません。ビジネスニーズに適したデータ精度を維持しながら、優れたパフォーマンスを発揮する独立したサービスを作成しています。
マイクロサービスの分離により、データ管理に次の新しい複雑さが導入されます。
-
データは分散されます。データは独立したサービスによって管理される個別のデータベースに存在するようになりました。
-
サービス間でのリアルタイムの同期は実用的ではないことが多く、結果整合性モデルが必要になります。
-
1 つのデータベーストランザクション内で以前に発生したオペレーションが、複数のサービスにまたがるようになりました。
これらの課題に対処するには、以下を実行します。
-
イベント駆動型アーキテクチャの実装 – メッセージキューとイベント発行を使用して、サービス間でデータ変更を伝達します。詳細については、「サーバーレスランドでのイベント駆動型アーキテクチャの構築
」を参照してください。 -
Saga オーケストレーションパターンを採用する – このパターンは、分散トランザクションを管理し、サービス間でデータの整合性を維持するのに役立ちます。詳細については、 AWS ブログの「Saga オーケストレーションパターンを使用してサーバーレス分散アプリケーションを構築する
」を参照してください。 -
障害の設計 — 再試行メカニズム、サーキットブレーカー、補償トランザクションを組み込み、ネットワークの問題やサービス障害を処理します。
-
バージョンスタンプを使用する – データバージョンを追跡して競合を管理し、最新の更新が適用されていることを確認します。
-
定期的な調整 — 定期的なデータ同期プロセスを実装して、不整合をキャッチして修正します。
シナリオベースの例
次のスキーマの例には、テーブルとCustomerテーブルの 2 つのOrderテーブルがあります。
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
以下は、非正規化アプローチを使用する方法の例です。
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
新しいOrderテーブルには、非正規化された顧客名と E メールアドレスがあります。customer_id が参照され、Customerテーブルに外部キーの制約はありません。この非正規化アプローチの利点は次のとおりです。
-
Orderサービスは注文履歴を顧客の詳細とともに表示でき、Customerマイクロサービスへの API コールは必要ありません。 -
Customerサービスが停止している場合、Orderサービスは完全に機能し続けます。 -
注文処理とレポート作成のクエリの実行が高速化されます。
次の図は、Orderマイクロサービスへの getOrder(customer_id)、、getOrder(order_id)、getCustomerOders(customer_id)および createOrder(Order order) API 呼び出しを使用して注文データを取得するモノリシックアプリケーションを示しています。
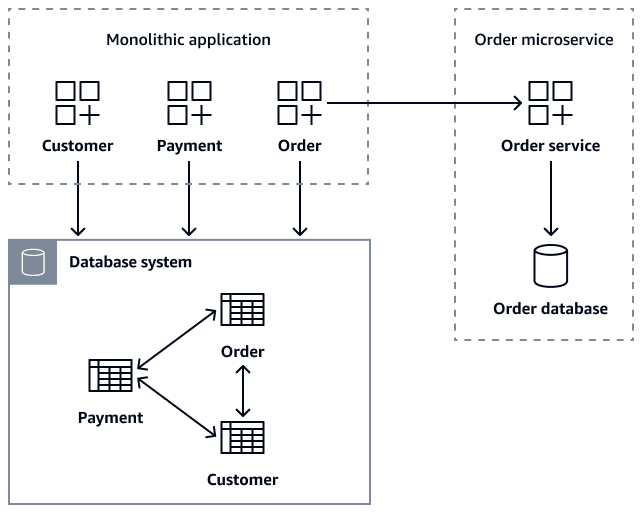
マイクロサービスの移行中、移行時の安全対策としてモノリシックデータベースのOrderテーブルを維持し、レガシーアプリケーションが機能し続けるようにすることができます。ただし、新しい注文関連のオペレーションはすべてOrder、マイクロサービス API を介してルーティングすることが重要です。マイクロサービス API は、バックアップとしてレガシーデータベースに書き込むと同時に、独自のデータベースを維持します。このデュアル書き込みパターンは、セーフティネットを提供します。これにより、システムの安定性を維持しながら、段階的な移行が可能になります。すべてのお客様が新しいマイクロサービスに正常に移行したら、モノリシックデータベースのレガシーOrderテーブルを廃止できます。モノリシックアプリケーションとそのデータベースを個別のCustomerOrderマイクロサービスに分解した後、データの一貫性を維持することが主な課題になります。
