翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データベースラッパーサービスパターンによるアクセスの制御
ラッパーサービスは、データベースのファサードとして機能するサービスレイヤーです。このアプローチは、将来の分解に備えながら既存の機能を維持する必要がある場合に特に役立ちます。このパターンは単純な原則に従います。何かが混乱しすぎる場合は、混乱を含めることから始めます。ラッパーサービスは、データベースにアクセスするための唯一の認可された方法となり、基盤となる複雑さを隠しながら制御されたインターフェイスを提供します。
このパターンは、複雑なスキーマが原因でデータベースをすぐに分解できない場合や、複数のサービスで継続的なデータアクセスが必要な場合に使用します。これは、システムの安定性を維持しながら慎重にリファクタリングする時間を提供するため、移行期間中は特に重要です。このパターンは、データの所有権を特定のチームに統合する場合や、新しいアプリケーションが複数のテーブルに集約されたビューを必要とする場合に適しています。
たとえば、次の場合にこのパターンを適用します。
-
スキーマの複雑さにより、すぐに分離できない
-
複数のチームに継続的なデータアクセスが必要
-
段階的なモダナイゼーションが推奨されます
-
チーム再構築には明確なデータ所有権が必要です
-
新しいアプリケーションには統合データビューが必要です
データベースラッパーサービスパターンの利点と制限
データベースラッパーパターンの利点は次のとおりです。
-
制御された増加 – ラッパーサービスは、データベーススキーマへの制御されていない追加を防止します。
-
明確な境界 — 実装プロセスは、明確な所有権と責任の境界を確立するのに役立ちます。
-
リファクタリングの自由 – ラッパーサービスを使用すると、コンシューマーに影響を与えることなく内部的な変更を行うことができます。
-
オブザーバビリティの向上 – ラッパーサービスは、モニタリングとログ記録のための単一のポイントです。
-
テストの簡素化 – ラッパーサービスを使用すると、サービスを消費してテスト用のモックバージョンを簡単に作成できます。
データベースラッパーパターンの制限は次のとおりです。
-
テクノロジーカップリング – ラッパーサービスは、消費するサービスと同じテクノロジースタックを使用する場合に最適です。
-
初期オーバーヘッド — ラッパーサービスには、パフォーマンスに影響を与える可能性のある追加のインフラストラクチャが必要です。
-
移行作業 – ラッパーサービスを実装するには、チーム間で調整して直接アクセスから移行する必要があります。
-
パフォーマンス – ラッピングサービスでトラフィックが多い、使用量が多い、または頻繁にアクセスする場合、サービスを消費するとパフォーマンスが低下する可能性があります。データベース上で、ラッパーサービスはページ分割、カーソル、データベース接続を処理する必要があります。ユースケースによっては、うまくスケーリングできず、抽出、変換、ロード (ETL) ワークロードに適していない可能性があります。
データベースラッパーサービスパターンの実装
データベースラッパーサービスパターンを実装するには、2 つのフェーズがあります。まず、データベースラッパーサービスを作成します。次に、それを通じてすべてのアクセスを指示し、アクセスパターンを文書化します。
フェーズ 1: データベースラッパーサービスの作成
データベースのゲートキーパーとして機能する軽量サービスレイヤーを作成します。最初は、既存のすべての機能をミラーリングする必要があります。このラッパーサービスは、すべてのデータベースオペレーションの必須アクセスポイントになり、直接データベースの依存関係をサービスレベルの依存関係に変換します。このレイヤーに詳細なログ記録とモニタリングを実装して、使用パターン、パフォーマンスメトリクス、アクセス頻度を追跡します。既存のストアドプロシージャは維持しますが、この新しいサービスインターフェイスを介してのみアクセスされるようにしてください。
フェーズ 2: アクセスコントロールの実装
ラッパーサービスを介してすべてのデータベースアクセスを体系的にリダイレクトし、データベースに直接アクセスする外部システムからデータベースの直接アクセス許可を取り消します。サービスが移行されるたびに、各アクセスパターンと依存関係を文書化します。この制御されたアクセスにより、外部コンシューマーを中断することなく、データベースコンポーネントの内部リファクタリングが可能になります。たとえば、複雑なトランザクションワークフローではなく、低リスクの読み取り専用オペレーションから始めます。
フェーズ 3: データベースのパフォーマンスをモニタリングする
ラッパーサービスをデータベースパフォーマンスの一元的なモニタリングポイントとして使用します。クエリの応答時間、使用パターン、エラー率、リソース使用率などの主要なメトリクスを追跡します。パフォーマンスしきい値と異常なパターンのアラートを設定します。例えば、実行速度の遅いクエリ、接続プールの使用率、トランザクションスループットをモニタリングして、潜在的な問題を事前に特定します。
この統合ビューを使用して、クエリの調整、リソース割り当ての調整、使用パターン分析を通じてデータベースのパフォーマンスを最適化します。ラッパーサービスの一元化された性質により、一貫したパフォーマンス標準を維持しながら、改善を実装し、すべてのコンシューマーへの影響を検証することが容易になります。
データベースラッパーサービスを実装するためのベストプラクティス
以下のベストプラクティスは、データベースラッパーサービスの実装に役立ちます。
-
Start small – 既存の機能を単純にプロキシする最小限のラッパーから始めます。
-
安定性の維持 – 内部改善を行いながら、サービスインターフェイスを安定させます。
-
使用状況のモニタリング – アクセスパターンを理解するための包括的なモニタリングを実装する
-
所有権のクリア — 専用チームを割り当てて、ラッパーと基盤となるスキーマの両方を維持します。
-
ローカルストレージを奨励する – チームが自分のデータベースにデータを保存するよう促す
シナリオベースの例
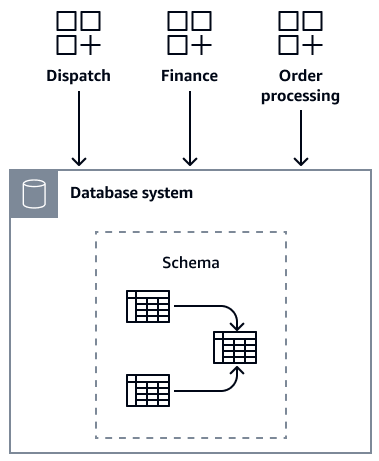
このセクションでは、AnyCompany Books という名前の架空の企業がデータベースラッパーパターンを使用してモノリシックデータベースシステムへのアクセスを制御する方法について説明します。AnyCompany Books には、ディスパッチ、財務、注文処理の 3 つの重要なサービスがあります。これらのサービスは、中央データベースへのアクセスを共有します。各サービスは、異なるチームによって管理されます。時間の経過とともに、特定のニーズに合わせてデータベーススキーマを個別に変更します。これにより、依存関係のウェブが複雑になり、データベース構造がますます複雑になっています。
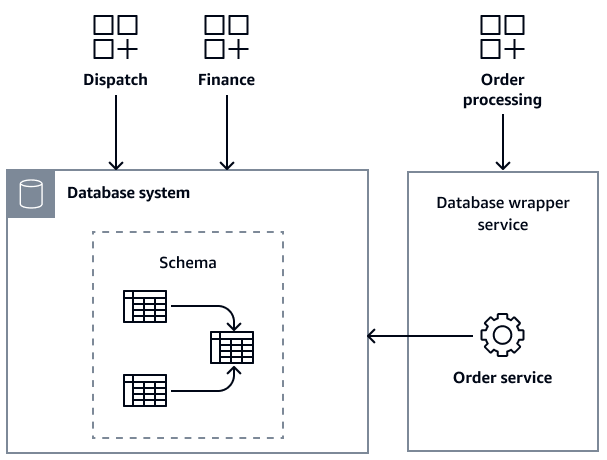
会社のアプリケーションアーキテクトまたはエンタープライズアーキテクトは、このモノリシックデータベースを分解する必要があることを認識しています。目標は、メンテナンス性を向上させ、チーム間の依存関係を減らすために、各サービスに独自の専用データベースを提供することです。ただし、大きな課題に直面しています。3 つのチームすべてが進行中のプロジェクトのためにデータベースを積極的に変更し続けている間、データベースを分解することはほぼ不可能です。スキーマの継続的な変更とチーム間の調整の欠如により、大規模な再構築を試みることは非常にリスクが高くなります。
アーキテクトは、データベースラッパーサービスパターンを使用して、モノリシックデータベースへのアクセスの制御を開始します。まず、Order サービスと呼ばれる特定のモジュールのデータベースラッパーサービスを設定します。次に、データベースに直接アクセスするのではなく、注文処理サービスをリダイレクトしてラッパーサービスにアクセスします。次の図は、変更されたインフラストラクチャを示しています。