翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
散布-収集パターン
Intent
散布-収集パターンは、メッセージルーティングパターンであり、これによって、類似または関連するリクエストを複数の受信者にブロードキャストし、アグリゲータというコンポーネントを使用して受信者からのレスポンスを 1 つのメッセージに集約します。このパターンは、並列化の実現、処理レイテンシーの削減、非同期通信の処理に有用です。同期アプローチによる、散布-収集パターンの実装は簡単ですが、それ以上に効果的なアプローチを取るには、メッセージングサービスの有無にかかわらず、非同期通信でのメッセージルーティングとして実装する必要があります。
導入する理由
アプリケーション処理において、シーケンシャル処理に時間がかかりそうなリクエストを、複数のリクエストに分割し並列処理することができ、API コールで複数の外部システムにリクエストを送信し、レスポンスを取得することも可能です。散布-収集パターンが便利な例として、複数ソースから入力が必要な場合が挙げられます。このパターンで結果を集約すると、情報に基づく意思決定や、リクエストに最適なレスポンスの選択を行いやすくなります。
散布-収集パターンは、その名前が示すように、2 つのフェーズで構成されます。
-
散布フェーズ: リクエストメッセージを処理し、複数の受信者に並行して送信します。このフェーズの間、リクエストをネットワーク全体に散布し、即時のレスポンスを待たずに実行し続けます。
-
収集フェーズ: 受信者からレスポンスを収集し、それらをフィルタリングするか、統合レスポンスとして結合します。すべてのレスポンスを収集した後は、1 つのレスポンスに集約することも、最適なレスポンスを選択して、詳細に処理することもできます。
適用対象
散布-収集は、次の場合に使用します。
-
正確なレスポンスを作成するために、さまざまな API からデータを集約し、統合する計画を立てている。このパターンでは、各種ソースからの情報全体をまとまった形で統合できます。例えば、予約システムで、複数の受信者にリクエストを行い、複数の外部パートナーから見積もりを取得できます。
-
トランザクションを完了するために、同じリクエストを複数の受信者に同時送信する必要がある。例えば、このパターンでインベントリデータを並行してクエリし、製品の可用性を確認できます。
-
信頼性とスケーラビリティに優れたシステムを実装して、複数の受信者にリクエストを配布することで、負荷分散を実現する必要がある。ある受信者が処理に失敗したり、負荷が高かったりする場合でも、他の受信者がリクエストを処理できます。
-
複数のデータソースが含まれる複雑なクエリを実装する場合に、パフォーマンスを最適化する必要がある。クエリを関連データベースに散布して、一部の結果を収集し、包括的な回答にまとめることができます。
-
マップ削減処理の一種を実装しており、この処理では、複数のデータ処理エンドポイントへのルーティングによって、シャーディングとレプリケーションを行う。結果の一部をフィルタリングして結合し、適切なレスポンスを作成できます。
-
key-value データベースにおいて書き込みが多いワークロードのパーティションキースペースに、書き込みオペレーションを分散する必要がある。アグリゲータによって、各シャードのデータをクエリして結果を読み取り、それらを 1 つのレスポンスに統合できます。
問題点と考慮事項
-
耐障害性: このパターンでは、並行して動作する複数の受信者に依存するため、障害を円滑に処理することが不可欠です。受信者側の失敗がシステム全体に与える影響を軽減するために、冗長性、レプリケーション、障害検出などの戦略を実装すると良いでしょう。
-
スケールアウト上の制約: 処理ノードの総数が増えると、関連するネットワークオーバーヘッドも増大します。ネットワークを介したどのようなリクエストによっても、レイテンシーが増大し、並列化の利点が損なわれる可能性があります。
-
レスポンス時間上のボトルネック: 最終処理の完了前にすべての受信者からのレスポンスを処理する必要があるオペレーションの場合、システム全体のパフォーマンスは、最も遅い受信者のレスポンス時間の制約を受けます。
-
部分的なレスポンス: 複数の受信者にリクエストを散布している場合、一部の受信者でタイムアウトが発生することがあります。こうした場合は、レスポンスが不完全であることがクライアントに伝わる仕組みを実装しなければなりません。UI フロントエンドを使用してレスポンス集約の詳細を表示するのも良いでしょう。
-
データ整合性: 複数の受信者を対象にデータを処理する場合は、データ同期および競合解決の手法を慎重に検討して、最終的に、正確で一貫性がある集計結果を得られるようにする必要があります。
実装
高レベルのアーキテクチャ
散布-収集パターンでは、ルートコントローラーを使用して、処理対象の受信者にリクエストを散布します。散布フェーズでは、このパターンによって 2 つの仕組みを使用し、受信者にメッセージを送信できます。
-
分散による散布: アプリケーションには、結果取得のために呼び出す必要がある既知の受信者リストがあります。受信者は、一意の関数を持つ異なるプロセスや、処理負荷を分散するためにスケールアウトされた単一のプロセスである可能性があります。いずれかの処理ノードがタイムアウトしたり、レスポンスが遅延したりすると、コントローラーによって、処理を別のノードに再分散することができます。
-
オークションによる散布: パブリッシュ – サブスクライブパターンを使用して、対象の受信者にメッセージをブロードキャストします。パブリッシュ – サブスクライブパターンこの場合、受信者はいつでもメッセージをサブスクライブしたり、サブスクリプションから脱退したりできます。
分散による散布
「分散による散布」方式では、ルートコントローラーによって受信リクエストを独立したタスクに分割し、使用可能な受信者に割り当てます (散布フェーズ)。各受信者 (プロセス、コンテナ、または Lambda 関数) は、独立して並列に計算を行い、レスポンスの一部を生成し、タスクを完了すると、アグリゲータに応答を送信します (収集フェーズ)。アグリゲータは、レスポンスの一部を結合し、最終結果をクライアントに返します。このワークフローを次の図に示します。
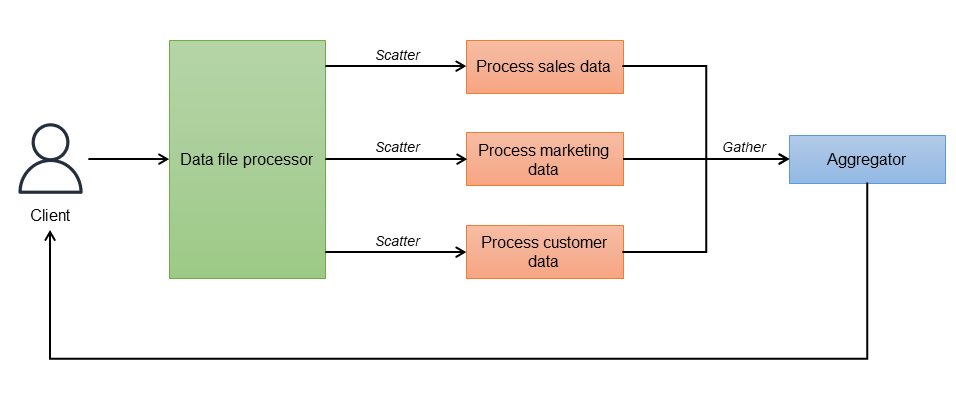
コントローラー (データファイルプロセッサ) は、一連の呼び出し全体をオーケストレーションするもので、呼び出す予約エンドポイントをすべて認識しています。コントローラーにタイムアウトパラメータを設定すると、時間がかかりすぎるレスポンスを無視できます。リクエストが送信されると、アグリゲータは各エンドポイントからのレスポンスを待ちます。レジリエンスを実装する場合は、各マイクロサービスを複数のインスタンスで構成してデプロイし、負荷分散を行うと良いでしょう。アグリゲータは、結果を取得してそれらを 1 つのレスポンスメッセージに結合します。さらに重複データを削除して、その後の処理に備えます。タイムアウトしたレスポンスは、無視されます。別のアグリゲータサービスを使用せず、コントローラーをアグリゲータとして機能させることもできます。
オークションによる散布
コントローラーが受信者を認識していない場合、または受信者が疎結合の場合は、「オークションによる散布」方式を使用できます。この方式では、受信者がトピックをサブスクライブし、コントローラーがトピックにリクエストを発行します。受信者は、結果をレスポンスキューに発行します。ルートコントローラーは受信者を認識していないため、収集プロセスでアグリゲータ (別のメッセージングパターン) を使用してレスポンスを収集し、単一のレスポンスメッセージとして抽出します。アグリゲータは、一意の ID を使用してリクエストグループを識別します。
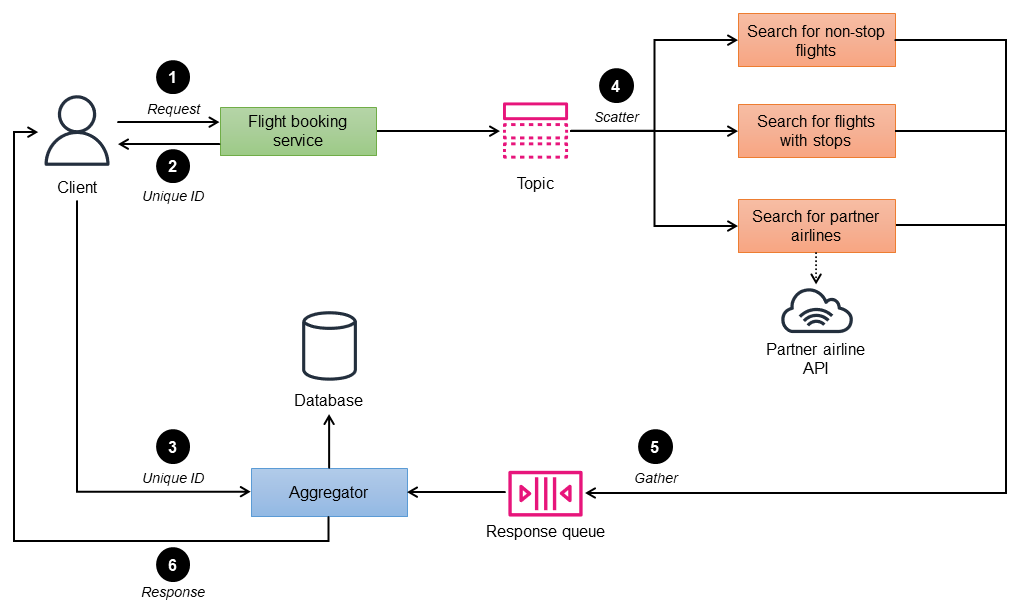
次の図に示す例では、「オークションによる散布」方式を使用して、航空会社のウェブサイトにフライト予約サービスを実装しています。ウェブサイトでは、ユーザーが航空会社独自のキャリアと、そのパートナーキャリアからフライトを検索して表示でき、検索のステータスもリアルタイムで表示される必要があります。フライト予約サービスは、直行便、経由便、パートナー航空会社という 3 つの検索マイクロサービスで構成されます。パートナー航空会社を検索する際には、パートナーの API エンドポイントを呼び出してレスポンスを取得します。
-
フライト予約サービス (コントローラー) が、検索条件をクライアントからの入力として受け取り、リクエストを処理してトピックに発行します。
-
コントローラーは、一意の ID を使用して、各リクエストグループを識別します。
-
クライアントが、ステップ 6 の一意の ID をアグリゲータに送信します。
-
予約検索マイクロサービス (予約トピックをサブスクライブ済み) が、リクエストを受け取ります。
-
マイクロサービスは、リクエストを処理し、指定された検索条件の座席が利用可能かどうかレスポンスキューに返します。
-
アグリゲータが、すべてのレスポンスメッセージを照合し、一時データベースに保存します。さらに、フライトを一意の ID でグループ化して、単一の統合レスポンスを作成し、クライアントに送信します。
を使用した実装 AWS のサービス
分散による散布
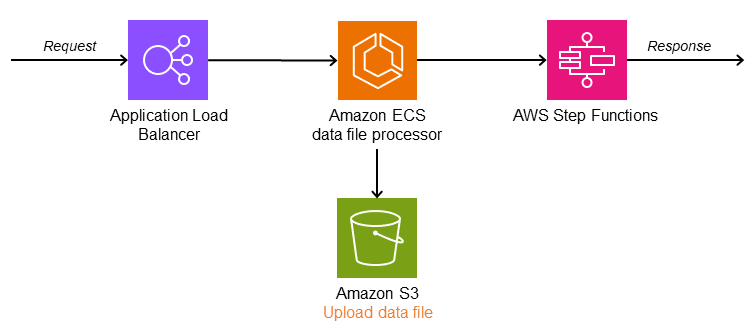
次のアーキテクチャでは、ルートコントローラーは、受信リクエストデータを個々の Amazon Simple Storage Service (Amazon S3) バケットに分割し、ワークフローを開始するデータファイルプロセッサ (Amazon ECS) です。 AWS Step Functions このワークフローにより、データをダウンロードして、並列ファイル処理を開始します。Parallel ステートにより、すべてのタスクからレスポンスが返るのを待ち、 AWS Lambda 関数はデータを集約し、Amazon S3 に保存します。
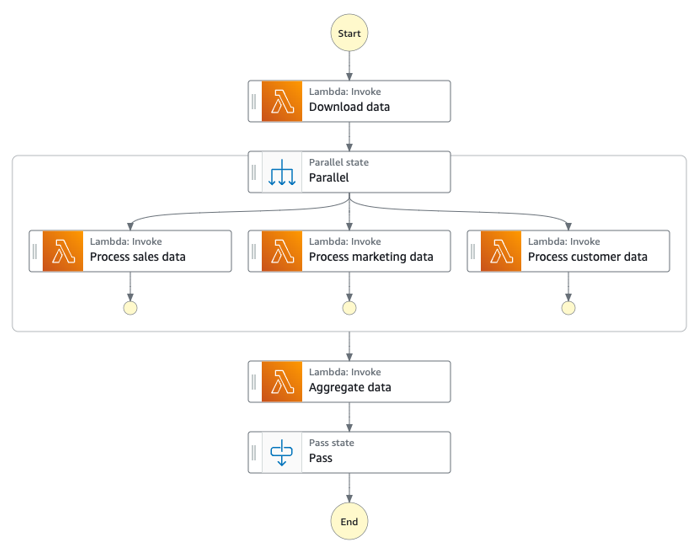
次の図は、Parallel ステートの Step Functions ワークフローを示しています。
オークションによる散布
次の図は、入札方法別の散布図の AWS アーキテクチャを示しています。ルートコントローラーであるフライト予約サービスによって、フライト検索リクエストを複数のマイクロサービスに分散します。パブリッシュ – サブスクライブチャネルは、通信用のマネージドメッセージングサービスである Amazon Simple Notification Service (Amazon SNS) を使用して実装します。Amazon SNS では、分離されたマイクロサービスアプリケーション間のメッセージ、またはユーザーへの直接通信がサポートされています。受信者のマイクロサービスを、Amazon Elastic Kubernetes Service (Amazon EKS) または Amazon Elastic Container Service (Amazon ECS) にデプロイすると、管理とスケーラビリティが向上します。フライト結果サービスにより、結果がクライアントに返ります。または Amazon ECS AWS Lambda や Amazon EKS などの他のコンテナオーケストレーションサービスに実装できます。
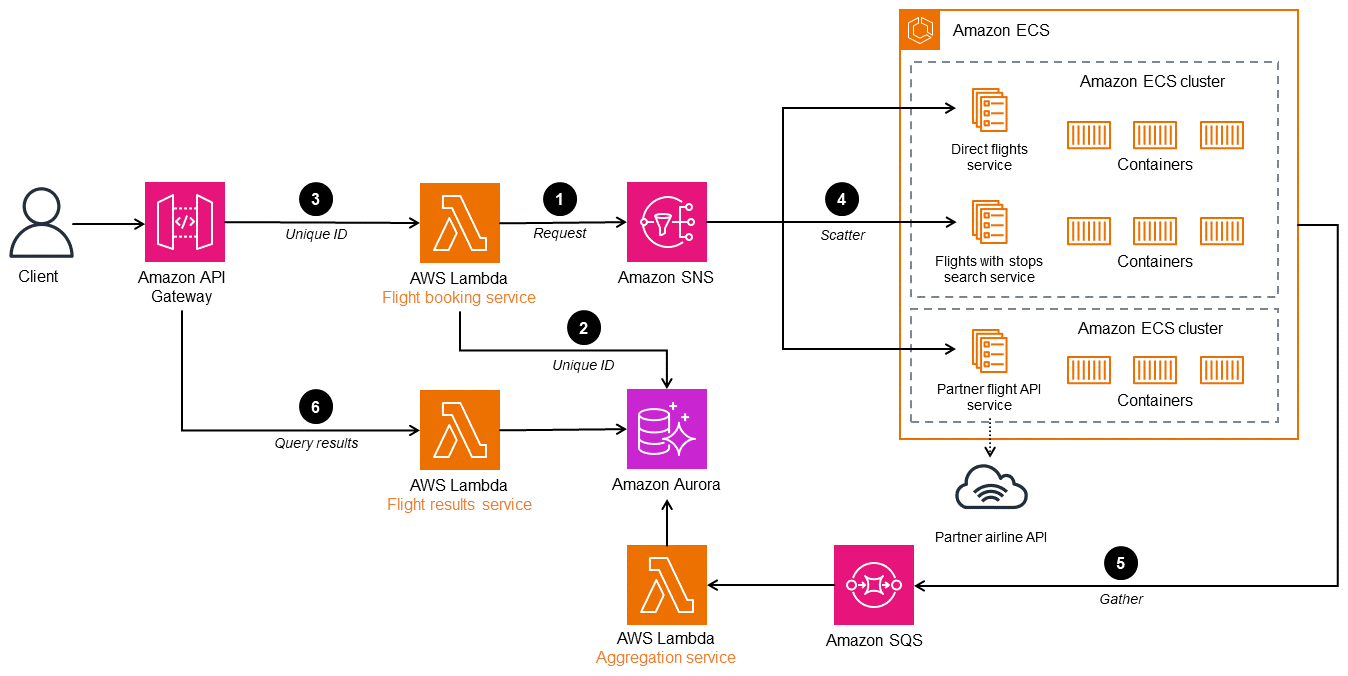
-
フライト予約サービス (コントローラー) が、検索条件をクライアントからの入力として受け取り、リクエストを処理して SNS トピックに発行します。
-
このコントローラーは、一意の ID を Amazon Aurora データベースに発行して、リクエストを識別します。
-
クライアントが、ステップ 6 の一意の ID をクライアントに送信します。
-
予約検索マイクロサービス (予約トピックをサブスクライブ済み) が、リクエストを受け取ります。
-
マイクロサービスは、リクエストを処理し、指定された検索条件の座席が利用可能かどうかを Amazon Simple Queue Service (Amazon SQS) のレスポンスキューに返します。アグリゲータが、すべてのレスポンスメッセージを照合し、一時データベースに保存します。
-
フライト結果サービスが、フライトを一意の ID でグループ化して、単一の統合レスポンスを作成し、クライアントに送信します。
このアーキテクチャに別の航空会社検索を追加する場合は、その SNS トピックをサブスクライブし、SQS キューへの発行を行うマイクロサービスを追加します。
要約すると、散布-収集パターンを実装した分散システムでは、効率的な並列化の実現、レイテンシーの削減、非同期通信のシームレスな処理が可能になります。
GitHub リポジトリ
このパターンのサンプルアーキテクチャの完全な実装については、https://github.com/aws-samples/asynchronous-messaging-workshop/tree/master/code/lab-3
ワークショップ
-
散布-収集のラボ
(Decoupled Microservices ワークショップ)
ブログの参考情報
関連情報
-
パブリッシュ – サブスクライブパターン
