翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
インプレース移行
インプレース移行により、すべてのデータファイルを書き直す必要がなくなります。代わりに、Iceberg メタデータファイルが生成され、既存のデータファイルにリンクされます。この方法は通常、特に Parquet、Avro、ORC などの互換性のあるファイル形式を持つ大規模なデータセットやテーブルの場合、より高速でコスト効率が高くなります。
注記
Amazon S3 Tables への移行時にインプレース移行を使用することはできません。
Iceberg には、インプレース移行を実装するための 2 つの主要なオプションがあります。
-
スナップショット
プロシージャを使用して、ソーステーブルを変更せずに新しい Iceberg テーブルを作成します。詳細については、Iceberg ドキュメントの「スナップショットテーブル 」を参照してください。 -
移行
手順を使用して、ソーステーブルの代替として新しい Iceberg テーブルを作成します。詳細については、Iceberg ドキュメントの「テーブルの移行 」を参照してください。この手順は Hive メタストア (HMS) で機能しますが、現在 と互換性がありません AWS Glue Data Catalog。このガイドの後半のセクションの「テーブル移行手順のレプリケート AWS Glue Data Catalog」は、データカタログと同様の結果を達成するための回避策を提供します。
snapshot または を使用してインプレース移行を実行した後migrate、一部のデータファイルは移行されないままになる場合があります。これは通常、ライターが移行中または移行後にソーステーブルに書き込むときに発生します。これらの残りのファイルを Iceberg テーブルに組み込むには、add_files
次のように、Athena で作成および入力された Parquet ベースのproductsテーブルがあるとします。
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
以下のセクションでは、この表で snapshotおよび migrateの手順を使用する方法について説明します。
オプション 1: スナップショット手順
snapshot この手順では、別の名前の新しい Iceberg テーブルを作成しますが、ソーステーブルのスキーマとパーティション化をレプリケートします。このオペレーションでは、アクション中とアクション後の両方でソーステーブルが完全に変更されません。テーブルの軽量コピーを効果的に作成します。これは、元のデータソースへの変更をリスクにさらすことなく、シナリオやデータ探索をテストする場合に特に役立ちます。このアプローチにより、元のテーブルと Iceberg テーブルの両方が利用可能な移行期間が可能になります (このセクションの最後にある注記を参照)。テストが完了したら、すべてのライターとリーダーを新しいテーブルに移行することで、新しい Iceberg テーブルを本番環境に移行できます。
snapshot この手順は、任意の Amazon EMR デプロイモデル (EC2 上の Amazon EMR、EKS 上の Amazon EMR、EMR Serverless など) および で Spark を使用して実行できます AWS Glue。
Spark snapshot 手順を使用してインプレース移行をテストするには、次の手順に従います。
-
Spark アプリケーションを起動し、次の設定で Spark セッションを設定します。
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
snapshot手順を実行して、元のテーブルデータファイルを指す新しい Iceberg テーブルを作成します。spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)出力データフレームには、
imported_files_count(追加されたファイルの数) が含まれます。 -
クエリを実行して新しいテーブルを検証します。
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
注意事項
-
プロシージャを実行すると、ソーステーブルのデータファイルを変更すると、生成されたテーブルが同期解除されます。追加した新しいファイルは Iceberg テーブルに表示されず、削除したファイルは Iceberg テーブルのクエリ機能に影響します。同期の問題を回避するには:
-
新しい Iceberg テーブルが本番稼働用である場合は、元のテーブルに書き込むすべてのプロセスを停止し、新しいテーブルにリダイレクトします。
-
移行期間が必要な場合、または新しい Iceberg テーブルがテスト用である場合は、このセクションの後半の「インプレース移行後の Iceberg テーブルの同期の維持」を参照してください。
-
-
snapshotプロシージャを使用すると、作成された Iceberg テーブルのテーブルプロパティfalseで プロパティが にgc.enabled設定されます。この設定ではexpire_snapshots、、remove_orphan_files、 などのアクションをPURGEオプションDROP TABLEで禁止します。これにより、データファイルが物理的に削除されます。ソースファイルに直接影響しない Iceberg 削除またはマージオペレーションは引き続き許可されます。 -
データファイルを物理的に削除するアクションに制限なしで新しい Iceberg テーブルを完全に機能させるには、
gc.enabledテーブルプロパティを に変更できますtrue。ただし、この設定により、ソースデータファイルに影響を与えるアクションが許可され、元のテーブルへのアクセスが破損する可能性があります。したがって、元のテーブルの機能を維持する必要がなくなった場合にのみ、gc.enabledプロパティを変更します。例えば、次のようになります。spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
オプション 2: 移行手順
migrate この手順では、ソーステーブルと同じ名前、スキーマ、パーティショニングを持つ新しい Iceberg テーブルを作成します。この手順を実行すると、ソーステーブルがロックされ、名前が <table_name>_BACKUP_ (またはbackup_table_nameプロシージャパラメータで指定されたカスタム名) に変更されます。
注記
drop_backup プロシージャパラメータを に設定した場合true、元のテーブルはバックアップとして保持されません。
したがって、migrateテーブルプロシージャでは、アクションが実行される前にソーステーブルに影響するすべての変更を停止する必要があります。migrate 手順を実行する前に、以下を実行します。
-
ソーステーブルを操作するすべてのライターを停止します。
-
Iceberg をネイティブにサポートしていないリーダーとライターを変更して、Iceberg サポートを有効にします。
例えば、次のようになります。
-
Athena は変更なしで動作し続けます。
-
Spark には以下が必要です。
-
クラスパスに含める Iceberg Java Archive (JAR) ファイル (このガイドの前半のセクションの「Amazon EMR での Iceberg の使用」および「Iceberg の使用 AWS Glue」を参照してください)。
-
次の Spark セッションカタログ設定 (Iceberg 以外のテーブルの組み込みカタログ機能を維持しながら Iceberg サポートを追加
SparkSessionCatalogするために使用します)。-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
プロシージャを実行したら、新しい Iceberg 設定でライターを再起動できます。
現在、Data Catalog は RENAMEオペレーションをサポートしていないため AWS Glue Data Catalog、migrateこの手順は と互換性がありません。したがって、Hive Metastore を使用している場合にのみ、この手順を使用することをお勧めします。データカタログを使用している場合は、次のセクションで代替アプローチを参照してください。
migrate この手順は、すべての Amazon EMR デプロイモデル (EC2 上の Amazon EMR、EKS 上の Amazon EMR、EMR Serverless) および で実行できますが AWS Glue、Hive メタストアへの接続を設定する必要があります。Amazon EMR on EC2 は、セットアップの複雑さを最小限に抑える Hive メタストア設定が組み込まれているため、推奨される選択肢です。
Hive Metastore migrate で設定された Amazon EMR on EC2 クラスターから Spark プロシージャを使用してインプレース移行をテストするには、次の手順に従います。
-
Spark アプリケーションを起動し、Iceberg Hive カタログ実装を使用するように Spark セッションを設定します。たとえば、 CLI
pysparkを使用している場合:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Hive メタストアに
productsテーブルを作成します。これはソーステーブルであり、一般的な移行に既に存在します。-
Hive Metastore で
products外部 Hive テーブルを作成し、Amazon S3 の既存のデータを参照します。spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
MSCK REPAIR TABLEコマンドを使用して既存のパーティションを追加します。spark.sql(f""" MSCK REPAIR TABLE products """ ) -
SELECTクエリを実行して、テーブルにデータが含まれていることを確認します。spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)サンプル出力:

-
-
Iceberg
migrateの手順を使用します。df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()出力データフレームには 、
migrated_files_count(Iceberg テーブルに追加されたファイルの数) が含まれます。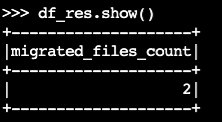
-
バックアップテーブルが作成されたことを確認します。
spark.sql("show tables").show()サンプル出力:
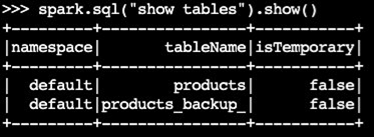
-
Iceberg テーブルをクエリしてオペレーションを検証します。
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
注意事項
-
プロシージャを実行すると、Iceberg サポートで適切に設定されていない場合、ソーステーブルにクエリまたは書き込む現在のプロセスがすべて影響を受けます。したがって、以下のステップに従うことをお勧めします。
-
移行前にソーステーブルを使用してすべてのプロセスを停止します。
-
移行を実行します。
-
適切な Iceberg 設定を使用してプロセスを再アクティブ化します。
-
-
移行プロセス中にデータファイルの変更が発生した場合 (新しいファイルが追加されるか、ファイルが削除された場合)、生成されたテーブルは同期しなくなります。同期オプションについては、このセクションの後半の「インプレース移行後に Iceberg テーブルを同期させる」を参照してください。
でのテーブル移行手順のレプリケート AWS Glue Data Catalog
以下の手順に従って AWS Glue Data Catalog 、移行手順の結果を (元のテーブルをバックアップして Iceberg テーブルに置き換える) でレプリケートできます。
-
スナップショットプロシージャを使用して、元のテーブルのデータファイルを指す新しい Iceberg テーブルを作成します。
-
データカタログで元のテーブルメタデータをバックアップします。
-
GetTable API を使用して、ソーステーブル定義を取得します。
-
GetPartitions API を使用して、ソーステーブルのパーティション定義を取得します。
-
CreateTable API を使用して、データカタログにバックアップテーブルを作成します。
-
CreatePartition または BatchCreatePartition API を使用して、データカタログのバックアップテーブルにパーティションを登録します。
-
-
gc.enabledIceberg テーブルプロパティを に変更falseして、完全なテーブルオペレーションを有効にします。 -
元のテーブルを削除 (Drop) します。
-
テーブルのルートロケーションのメタデータフォルダで Iceberg テーブルメタデータ JSON ファイルを見つけます。
-
元のテーブル名とプロシージャによって作成された
metadata.jsonファイルの場所を指定して register_tablesnapshotプロシージャを使用して、データカタログに新しいテーブルを登録します。spark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
インプレース移行後の Iceberg テーブルの同期の維持
add_files この手順では、既存のデータを Iceberg テーブルに柔軟に組み込むことができます。具体的には、Iceberg のメタデータレイヤーで絶対パスを参照することで、既存のデータファイル (Parquet ファイルなど) を登録します。デフォルトでは、プロシージャはすべてのテーブルパーティションから Iceberg テーブルにファイルを追加しますが、特定のパーティションからファイルを選択的に追加できます。この選択的なアプローチは、いくつかのシナリオで特に役立ちます。
-
最初の移行後に新しいパーティションがソーステーブルに追加された場合。
-
最初の移行後にデータファイルが既存のパーティションに追加または削除された場合。ただし、変更されたパーティションを再追加するには、最初にパーティションを削除する必要があります。詳細については、このセクションの後半で説明します。
インプレース移行 (snapshot または migrate) の実行後に add_fileプロシージャを使用して、新しい Iceberg テーブルをソースデータファイルと同期させる際の考慮事項を次に示します。
-
ソーステーブルの新しいパーティションに新しいデータが追加されたら、 オプションで
partition_filteradd_filesプロシージャを使用して、これらの追加を Iceberg テーブルに選択的に組み込みます。spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)または
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
add_filesプロシージャは、partition_filterオプションを指定すると、ソーステーブル全体または特定のパーティション内のファイルをスキャンし、見つかったすべてのファイルを Iceberg テーブルに追加しようとします。デフォルトでは、check_duplicate_filesプロシージャプロパティは に設定されます。これによりtrue、ファイルが Iceberg テーブルに既に存在する場合、プロシージャは実行されません。これは、以前に追加されたファイルをスキップする組み込みオプションがなく、無効にするとcheck_duplicate_filesファイルが 2 回追加され、重複が生じるため、重要です。ソーステーブルに新しいファイルが追加されたら、次の手順に従います。-
新しいパーティションの場合は、
add_filesで を使用してpartition_filter、新しいパーティションからファイルのみをインポートします。 -
既存のパーティションの場合、まず Iceberg テーブルからパーティションを削除し、次にそのパーティション
add_filesに対して を指定して再実行しますpartition_filter。例えば、次のようになります。# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
注記
add_files オペレーションごとに、追加されたデータを含む新しい Iceberg テーブルスナップショットが生成されます。
適切なインプレース移行戦略の選択
最適なインプレース移行戦略を選択するには、次の表の質問を検討してください。
質問 |
推奨事項 |
説明 |
|---|---|---|
Hive テーブルと Iceberg テーブルの両方をテストや段階的な移行のためにアクセスできるようにしながら、データを書き換えずにすばやく移行したいですか? |
|
|
Hive メタストアを使用していて、データを書き換えることなく、すぐに Hive テーブルを Iceberg テーブルに置き換えたいですか? |
|
注: このオプションは Hive メタストアと互換性がありますが、 と互換性がありません AWS Glue Data Catalog。 移行後に追加または変更されたパーティションを組み込むには、 |
を使用していて AWS Glue Data Catalog 、データを書き換えることなく、Hive テーブルを Iceberg テーブルにすぐに置き換えたいですか? |
|
注: このオプションでは、メタデータバックアップの AWS Glue API コールを手動で処理する必要があります。 移行後に追加または変更されたパーティションを組み込むには、 |
