翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
での Apache Iceberg のリファレンスアーキテクチャ AWS
このセクションでは、バッチ取り込みや、バッチデータ取り込みとストリーミングデータ取り込みを組み合わせたデータレイクなど、さまざまなユースケースでベストプラクティスを適用する方法の例を示します。
毎晩のバッチ取り込み
この架空のユースケースでは、Iceberg テーブルがクレジットカード取引を毎晩取り込むとします。各バッチには増分更新のみが含まれており、ターゲットテーブルにマージする必要があります。1 年に数回、完全な履歴データを受信します。このシナリオでは、次のアーキテクチャと設定をお勧めします。
注: これは単なる例です。最適な設定は、データと要件によって異なります。
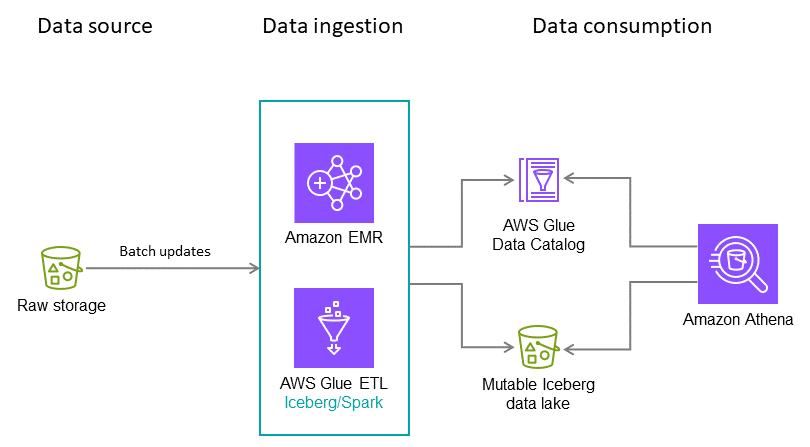
推奨事項:
-
ファイルサイズ: Apache Spark タスクは 128 MB のチャンクでデータを処理するため、128 MB。
-
書き込みタイプ: copy-on-write。このガイドの前半で説明したように、このアプローチは、データが読み取りに最適化された方法で書き込まれるようにするのに役立ちます。
-
パーティション変数: year/month/day。仮定のユースケースでは、最近のデータを最も頻繁にクエリしますが、過去 2 年間のデータに対して完全なテーブルスキャンを実行することがあります。パーティショニングの目的は、ユースケースの要件に基づいて高速読み取りオペレーションを促進することです。
-
ソート順: タイムスタンプ
-
データカタログ: AWS Glue Data Catalog
バッチ取り込みとほぼリアルタイムの取り込みを組み合わせたデータレイク
アカウントとリージョン間でバッチデータとストリーミングデータを共有するデータレイクを Amazon S3 にプロビジョニングできます。アーキテクチャ図と詳細については、 AWS ブログ記事「Build a transactional data lake using Apache Iceberg AWS Glue」および「 と AWS Lake Formation Amazon Athena を使用したクロスアカウントデータ共有
