翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
並列化のワークフロー
このワークフローでは、タスクを独立したサブタスクに分割し、複数の LLM コールまたはエージェントで同時に処理できます。その後、出力はプログラムで集約され、結果に合成されます。
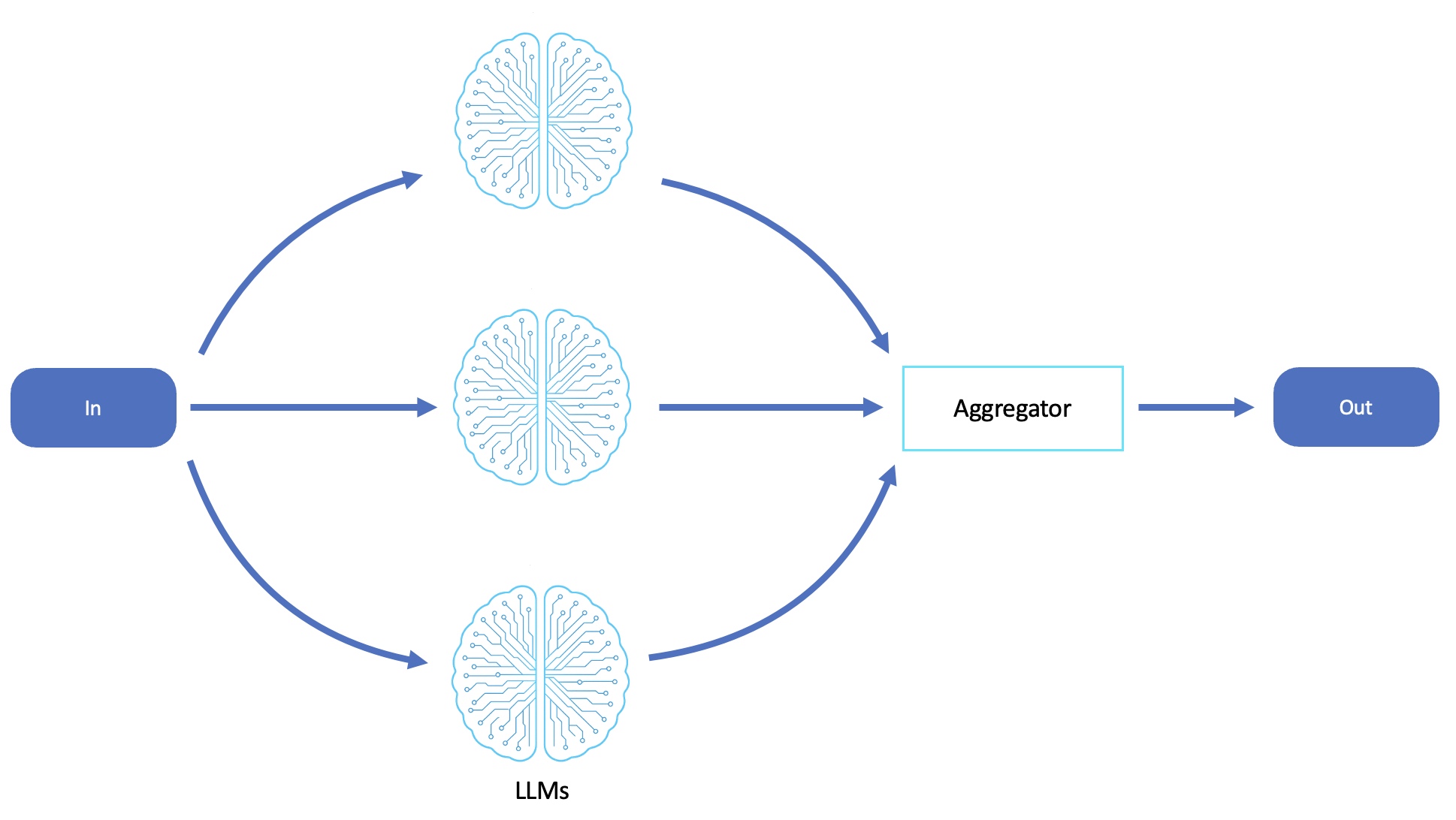
並列化ワークフローは、タスクを独立した非連続サブタスクに分割して同時に処理できる場合に使用します。これにより、効率、スループット、スケーラビリティが大幅に向上します。これは、エージェントが複数の入力にわたってコンテンツを分析または生成する必要がある、データ量の多い、バッチ指向、またはマルチパースペクティブな問題スペースで特に強力です。
並列化は、次の場合に特に効果的です。
-
サブタスクは相互の中間結果に依存しないため、調整せずに並行して実行できます。
-
タスクでは、同じ推論プロセスを多くの項目で繰り返します (複数のドキュメントを要約したり、オプションのリストを評価したりするなど)。
-
多様性、創造性、堅牢性を促進するために、複数の仮説や視点が並行して検討されます。
-
LLM の同時実行により、高ボリュームまたは高頻度のリクエストのレイテンシーを減らす必要があります。
-
このワークフローは、ドキュメント処理エージェント、調査または比較エンジン、バッチサマリ、マルチエージェントブレインストーミング、スケーラブルな分類またはラベル付けタスクで一般的に使用されます。特に、迅速で並行した推論がパフォーマンス上の利点である場合です。
機能
-
LLM タスクの並列実行 ( AWS Lambda、 AWS Fargate、または AWS Step Functions マップ状態を使用)
-
合成段階で結果の整列、検証、重複排除が必要
-
ステートレスエージェントループに最適
一般的なユースケース
-
複数のドキュメントまたは視点を並行して分析する
-
多様なドラフト、概要、または計画の生成
-
バッチジョブ間のスループットの高速化
