翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
評価者とリフレクション/絞り込みループのワークフロー
このワークフローは、1 つの LLM が結果を生成し、別の が結果を評価または批評するフィードバックループを提供します。これにより、自己リフレクション、最適化、反復的な改善が促進されます。
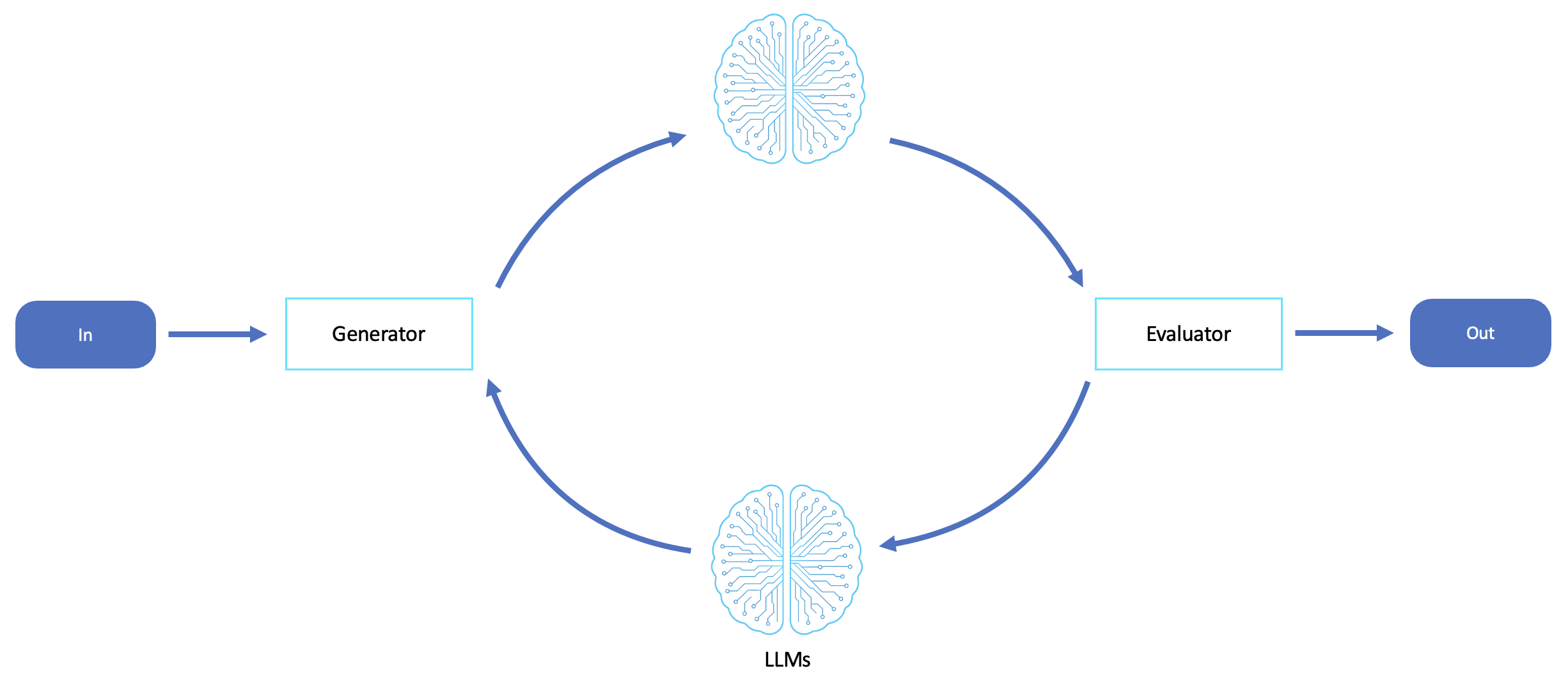
評価者ワークフローは、出力の品質、精度、調整が重要で、単一パス生成の信頼性が低い、または不十分なシナリオに最適です。このワークフローは、より高い正確性基準を満たすため、またはフィードバックに基づいて改善された代替案を検討するために、エージェントが出力を自己批判、反復、および絞り込む必要があるときに優れています。
このワークフローは、次の場合に特に効果的です。
-
出力には、主観的な品質メトリクス (スタイル、トーン、読みやすさなど) または目標基準 (正確性、安全性、パフォーマンスなど) が含まれます。
-
エージェントは、トレードオフを通じて推論し、制約を評価し、目標に向けて最適化する必要があります。
-
特に規制対象ドメイン、顧客向けドメイン、またはクリエイティブドメインでは、組み込みの冗長性と品質保証が必要です。
-
ヒューHuman-in-the-loopレビューは高価または利用できないため、自律的な検証が必要です。
このワークフローは、コンテンツ生成、コード合成とレビュー、ポリシーの適用、アライメントチェック、指示調整、RAG 後処理に使用されます。また、継続的なフィードバックが時間の経過とともにより良い対応を形成し、信頼できる自律的な決定ループを構築するのに役立つ自己改善エージェントにも役立ちます。
一般的なユースケース
-
ブルーチームエージェントと比較したレッドチームエージェント
-
コードまたは計画を生成、評価、および改訂するエージェント
-
品質保証、幻覚検出、スタイルの適用
機能
-
さまざまなモデルを使用した分離された生成と評価をサポート (生成には Claude、評価には Mistral など)
-
フィードバックは構造化され、改訂された出力を促すために使用されます。
-
複数の反復または収束のしきい値をサポート
