翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
基本的な推論エージェント
基本的な推論エージェントは、クエリに応答して論理推論または意思決定を実行するエージェント AI の最もシンプルな形式です。ユーザーまたはシステムからの入力を受け入れ、クエリを処理し、構造化プロンプトを使用してレスポンスを生成します。
このパターンは、特定のコンテキストに基づいて単一ステップの推論、分類、または要約を必要とするタスクに役立ちます。メモリ、ツール、状態管理を使用しないため、ステートレスで軽量で、大規模なワークフローで高度に構成できます。
アーキテクチャ
基本的な推論エージェントのフローを次の図に示します。
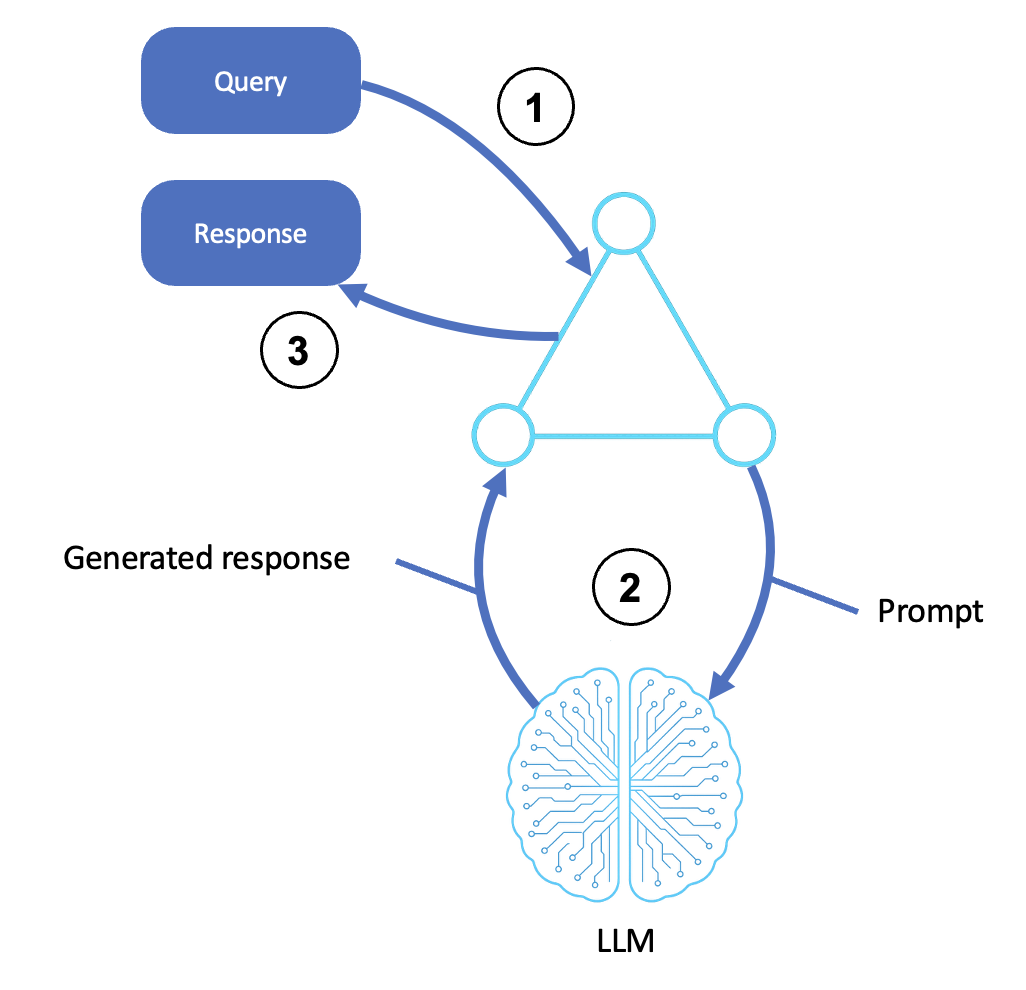
説明
-
入力を受け取る
-
ユーザー、システム、またはアップストリームエージェントがクエリまたは命令を送信します。
-
入力はエージェントシェルまたはオーケストレーションレイヤーに引き渡されます。
-
このステップには、前処理、プロンプトテンプレート作成、目標の特定が含まれます。
-
-
LLM を呼び出します
-
エージェントはクエリを構造化プロンプトに変換し、LLM に送信します (Amazon Bedrock 経由など)。
-
LLM は、事前トレーニング済みの知識とコンテキストを使用して、プロンプトに基づいてレスポンスを生成します。
-
生成された出力には、推論ステップ (chain-of-thought)、最終的な回答、またはランク付けされたオプションが含まれます。
-
-
レスポンスを返します。
-
生成された出力は、エージェントのインターフェイスに中継されます。
-
これには、フォーマット、後処理、または API レスポンスが含まれます。
-
機能
-
自然言語または構造化された入力をサポート
-
プロンプトエンジニアリングを使用して動作をガイドします
-
ステートレスでスケーラブル
-
UI、CLI、APIs、パイプラインに埋め込むことができます
制限事項
-
メモリまたは履歴認識がない
-
外部ツールやデータソースとやり取りしない
-
推論時に LLM が知っているものに限定
一般的なユースケース
-
会話の質問と回答
-
ポリシーの説明と概要
-
意思決定のためのガイダンス
-
軽量で自動化されたチャットボットフロー
-
分類、ラベル付け、スコアリング
実装のガイダンス
次のツールとサービスを使用して、基本的な推論エージェントを作成できます。
-
Amazon Bedrock for LLM 呼び出し (Anthropic、AI21、Meta)
-
Amazon API Gateway または AWS Lambda を使用してステートレスマイクロサービスとして公開する
-
Parameter Store に保存されているプロンプトテンプレート AWS Secrets Manager、またはコードとして保存されているプロンプトテンプレート
概要
基本的な推論エージェントは、シンプルな構造のため、基本的なものです。目標はインテリジェントな出力につながる推論パスに変換するコア機能を備えています。このパターンは、多くの場合、ツールベースのエージェントや取得拡張生成 (RAG) を使用するエージェントなど、高度なパターンの出発点です。また、大規模なワークフローの信頼性の高いモジュールコンポーネントでもあります。
エージェント RAG
Retrieval-augmented generation (RAG) は、情報の取得とテキスト生成を組み合わせて、正確でコンテキストに応じたレスポンスを作成する手法です。RAG を使用すると、エージェントは LLM をエンゲージする前に関連する外部情報を取得できます。これにより、エージェントの決定をup-to-date、事実、またはドメイン固有の情報に基づいて判断することで、エージェントの有効なメモリと推論の精度が向上します。事前トレーニング済みの重みのみに依存するステートレス LLMs とは対照的に、RAG にはコンテキストでプロンプトを動的に強化する外部ナレッジ検索レイヤーがあります。
アーキテクチャ
RAG パターンのロジックを次の図に示します。
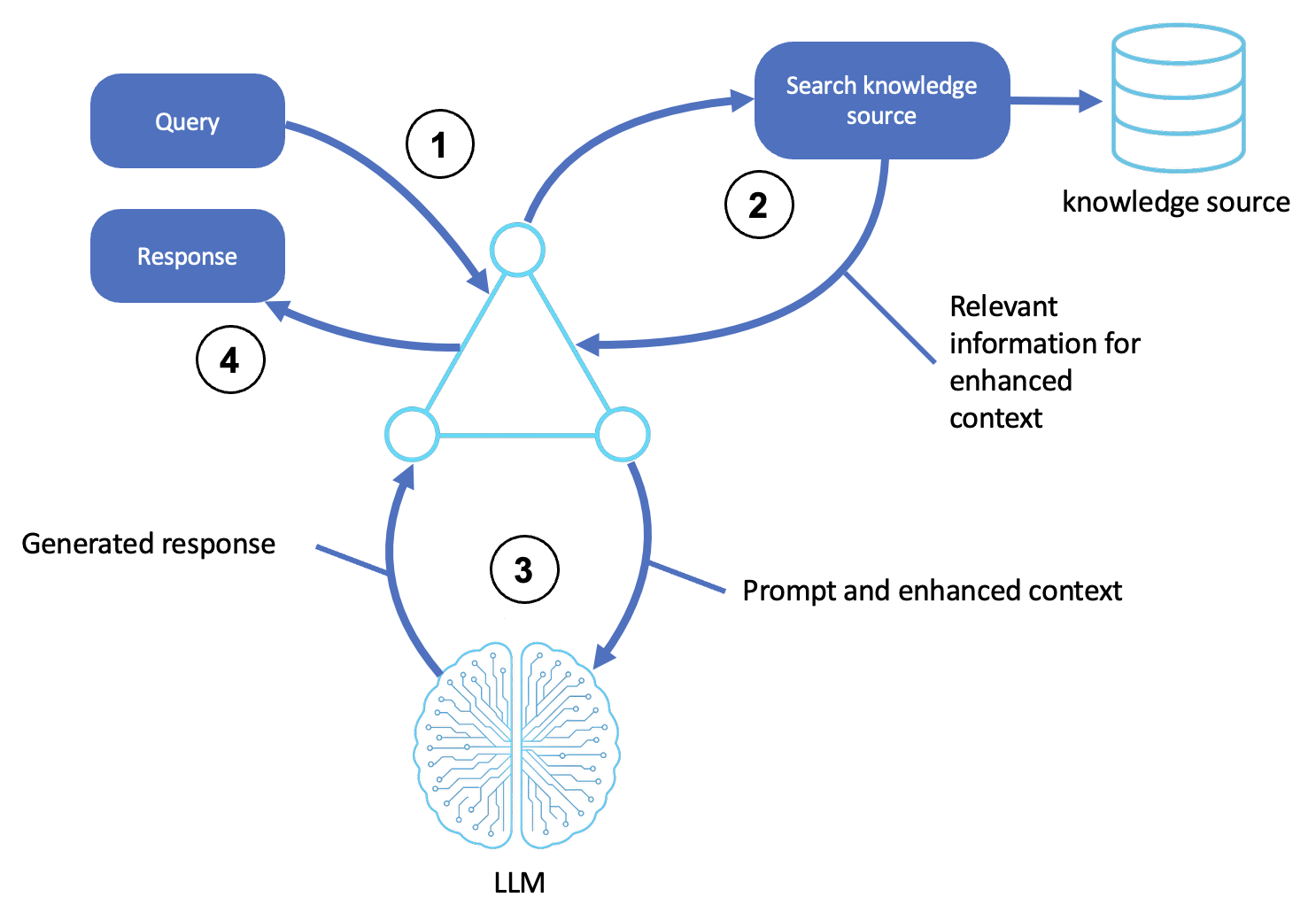
説明
-
クエリを受信する
-
ユーザーまたはアップストリームシステムがクエリまたは目標をエージェントに送信します。
-
エージェントシェルはリクエストを受け入れ、推論のプロンプトとしてフォーマットします。
-
-
外部ソースを検索します。
-
エージェントは、クエリから概念とインテントを識別します。
-
セマンティック検索またはキーワードマッチングを使用して、ベクトルストア、データベース、ドキュメントインデックスなどのナレッジソースをクエリします。
-
最も関連性の高いパッセージ、ドキュメント、またはエンティティは、次のステップで使用するために取得されます。
-
-
コンテキストレスポンスを生成します。
-
エージェントは、取得した情報でプロンプトを強化し、LLM のコンテキスト拡張入力を形成します。
-
LLM は、生成推論 (chain-of-thoughtやリフレクションなど) を使用して入力を処理し、正確なレスポンスを生成します。
-
-
最終出力を返します。
-
エージェントは、出力を任意の通信ヘッダーまたは必要な形式にラップして準備し、ユーザーまたは呼び出しシステムに返します。
-
(オプション) 取得したドキュメントと LLM 出力は、今後のクエリのためにログに記録、スコアリング、メモリに保存される場合があります。
-
機能
-
ロングテールドメインやエンタープライズ固有のドメインでも事実に基づく出力
-
モデルを微調整しないメモリ拡張
-
各クエリとユーザーの状態に基づく動的コンテキスト
-
ベクトルデータベース、セマンティックインデックス、メタデータフィルタリングとの完全な互換性
一般的なユースケース
-
エンタープライズナレッジアシスタント
-
規制コンプライアンスボット
-
カスタマーサポート副操縦士
-
検索が強化されたチャットボット
-
デベロッパードキュメントエージェント
実装のガイダンス
次のツールとサービスを使用して、RAG を使用するエージェントを作成します。
-
Amazon Bedrock for LLM 呼び出し
-
ドキュメントまたは構造化データ検索用の Amazon Kendra、OpenSearch、または Amazon Aurora
-
ドキュメントストレージ用の Amazon Simple Storage Service (Amazon S3)
-
AWS Lambda 検索、プロンプト、LLM 推論をオーケストレーションする
-
エージェントとのナレッジベースの統合 (メモリプラグイン、セマンティックリトリーバー、または Amazon Bedrock を使用)
概要
エージェント RAG は、静的モデル推論を動的な実世界のインテリジェンスに接続します。これにより、エージェントは知らないものを検索し、取得した知識から回答を合成し、信頼性の高い監査可能な応答を生成できます。
RAG パターンは、再トレーニングなしでナレッジアクセスをスケールするインテリジェントなエージェントを構築するための基盤です。多くの場合、ツールの使用、計画、長期メモリを含む、より複雑なオーケストレーションパターンの先駆けとなります。
