翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS ParallelCluster Auto Scaling
注記
このセクションは、AWS ParallelClusterバージョン 2.11.4 以前のバージョンにのみ適用されます。バージョン 2.11.5 以降、AWS ParallelClusterは SGE または Torque スケジューラの使用をサポートしていません。2.11.4 までのバージョンで引き続き使用できますが、サービスチームやAWSサポートチームによるAWS今後の更新やトラブルシューティングのサポートを受けることはできません。
AWS ParallelClusterバージョン 2.9.0 以降、Auto Scaling は Slurm Workload Manager () での使用はサポートされていませんSlurm。Slurm と複数のキュースケーリングの詳細については、「マルチキューモードのチュートリアル」を参照してください。
このトピックで説明するオートスケーリング戦略は、Son of Grid Engine (SGE) または Torque Resource Manager (Torque) のいずれかで展開される HPC クラスターに適用されます。これらのスケジューラのいずれかを使用してデプロイすると、AWS ParallelClusterは、コンピューティングノードの Auto Scaling グループを管理し、必要に応じてスケジューラ構成を変更することで、スケーリング機能を実装します。に基づく HPC クラスターの場合AWS Batch、AWS ParallelClusterはAWSマネージドジョブスケジューラによって提供される Elastic Scaling 機能に依存します。詳細については、「Amazon EC2 Auto Scaling User Guide」(Amazon EC2 Auto Scaling ユーザーガイド) の「What is Amazon EC2 Auto Scaling」(Amazon EC2 Auto Scaling とは) を参照してください。
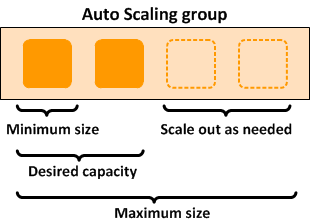
でデプロイされたクラスターAWS ParallelClusterは、いくつかの点で伸縮自在です。initial_queue_size を設定すると、ComputeFleet Auto Scaling グループの最小サイズの値と、必要な容量の値が指定されます。max_queue_size を設定すると、ComputeFleet Auto Scaling グループの最大サイズの値が指定されます。
スケールアップ
毎分、ヘッドノードでは jobwatcher
SGE スケジューラでは、実行する多数のスロットがジョブごとに必要です (1 つのスロットが 1 つの処理ユニット (例: vCPU) に対応します)。現在保留中のジョブを処理するために必要なインスタンスの数を評価する場合、jobwatcher は 1 つのコンピューティングノードの容量でリクエストされたスロットの合計数を除算します。利用可能な vCPU の数に相当するコンピューティングノードの容量は、クラスター設定で指定されている Amazon EC2 インスタンスタイプによって異なります。
Slurm (AWS ParallelClusterバージョン 2.9.0 より前) とスTorqueケジューラでは、状況に応じて、各ジョブで各ノードのノード数とスロット数の両方が必要になる場合があります。jobwatcher では、新しい計算要件を満たすために必要なコンピューティングノードの数をリクエストごとに決定します。例えば、あるクラスターのコンピューティングインスタンスタイプが c5.2xlarge (8 vCPU) であり、3 つの 保留中のキューに登録されたジョブの要件が以下であると仮定します。
-
job1: 2 ノード/4 スロット
-
job2: 3 ノード/2 スロット
-
job3: 1 ノード/4 スロット
この例の jobwatcher では、3 つのジョブを処理するために、Auto Scaling グループに 3 つの新しいコンピューティングインスタンスが必要です。
現在の制限: オートスケールアップロジックは、部分的にロードされたビジーノードを考慮しません。例えば、ジョブを実行しているノードでは、スロットが空いていてもビジーとみなされます。
スケールダウン
各コンピューティングノードで nodewatcher
-
インスタンスで scaledown_idletime より長い期間ジョブが実行されていない (デフォルト設定は 10 分)
-
クラスター内に保留中のジョブがない
インスタンスを終了するために、nodewatcher は、TerminateInstanceInAutoScalingGroup API オペレーションを呼び出します。その結果、Auto Scaling グループのサイズが Auto Scaling グループの最小サイズを上回ると、インスタンスは削除されます。このプロセスでは、実行中のジョブに影響を及ぼすことなく、クラスターをスケールダウンすることができます。また、固定ベース数のインスタンスにより伸縮自在なクラスターを有効にします。
静的クラスター
スケールの値は、HPC の場合も他のワークロードと同じです。ここでの唯一の違いは、AWS ParallelClusterには、具体的にインテリジェントな方法で操作させるコードがあることです。例えば、静的クラスターが必要な場合は、initial_queue_size パラメータおよび max_queue_size パラメータを必要なクラスターの正確なサイズに設定し、その後 maintain_initial_size パラメータを true に設定します。これにより、ComputeFleet Auto Scaling グループの最小容量、最大容量、および必要な容量に対して同じ値が設定されます。
