翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon OpenSearch Serverless とは
Amazon OpenSearch Serverless は、Amazon OpenSearch Service のオンデマンドのサーバーレスオプションであり、OpenSearch クラスターのプロビジョニング、設定、チューニングといった複雑な運用を排除します。クラスターを自己管理したくない組織や、大規模なデプロイの運用に必要となる専用リソースや高度な知識を持たない組織に最適です。OpenSearch Serverless を使用することで、基盤となるインフラストラクチャを管理することなく、大容量のデータを検索して分析できます。
OpenSearch Serverless コレクションとは、特定のワークロードやユースケースをサポートするために連携して機能する OpenSearch インデックスのグループを指します。コレクションは、手動のプロビジョニングが必要なセルフマネージド型の OpenSearch クラスターと比べて運用を簡素化します。
コレクションは、プロビジョニングされた OpenSearch Service ドメインと同じタイプの、大容量かつ分散型で可用性の高いストレージボリュームを使用しますが、手動による設定やチューニング操作を減らすことで複雑さが大幅に解消されます。OpenSearch Serverless エンドポイントとのすべての通信では TLS 1.2 暗号化が使用され、クライアントからエンドポイントへの転送中にデータが暗号化されます。また、データはコレクションの内部コンポーネント間で転送中に暗号化されます。OpenSearch Serverless は、データを分析するためのインターフェイスである OpenSearch Dashboards もサポートしています。
OpenSearch Serverless はオープンソースの OpenSearch と互換性があります。新しいバージョンがリリースされると、OpenSearch Serverless はコレクションを自動的にアップグレードして、新しい機能、バグ修正、パフォーマンス強化を組み込みます。
OpenSearch Serverless では OpenSearch オープンソーススイートと同じ取り込みオペレーションやクエリ API オペレーションがサポートされているため、既存のクライアントやアプリケーションを引き続き使用できます。OpenSearch Serverless を使用するには、クライアントが OpenSearch 3.x と互換性がある必要があります。詳細については、「Amazon OpenSearch Serverless コレクションへのデータの取り込み」を参照してください。
トピック
OpenSearch Serverless のユースケース
OpenSearch Serverless は、主に次の 2 つのユースケースをサポートしています。
-
ログ分析 – ログ分析セグメントは、オペレーションインサイトとユーザーの行動に関するインサイトを得るために、マシン生成による大量の半構造化された時系列データを分析することに重点を置きます。
-
全文検索 – 全文検索セグメントが、社内ネットワーク内のアプリケーション (コンテンツ管理システム、法的文書) や、e コマースウェブサイトのコンテンツ検索などのインターネット向けアプリケーションを強化します。
コレクションを作成するときは、これらのユースケースのいずれかを選択します。詳細については、「コレクションタイプを選択する」を参照してください。
仕組み
従来の OpenSearch クラスターには、インデックス作成オペレーションと検索オペレーションの両方を実行する単一のインスタンスセットがあり、インデックスストレージはコンピューティング性能と密接に結びついています。これに対し、OpenSearch Serverless はインデックス作成 (取り込み) コンポーネントを検索 (クエリ) コンポーネントから分離するクラウドネイティブなアーキテクチャを採用しており、Amazon S3 をインデックスのプライマリデータストレージとして使用します。
この分離されたアーキテクチャでは、検索機能とインデックス作成機能を相互に独立して、さらに S3 のインデックス化されたデータとも無関係にスケーリングできます。また、このアーキテクチャでは、取り込みオペレーションとクエリオペレーションを分離できるため、リソースを競合させることなく同時に実行できます。
コレクションにデータを書き込むと、OpenSearch Serverless はそのデータをインデックス作成用コンピューティングユニットに配信します。インデックス作成用コンピューティングユニットは、受信データを取り込み、インデックスを S3 に移動します。コレクションデータに対して検索を実行すると、OpenSearch Serverless はクエリ実行対象のデータを保持する検索用コンピューティングユニットにリクエストをルーティングします。検索コンピューティングユニットは、インデックス化されたデータを S3 から直接ダウンロードし (まだローカルにキャッシュされていない場合)、検索オペレーションを実行し、集計を実行します。
次の図は、この分離されたアーキテクチャを示しています。
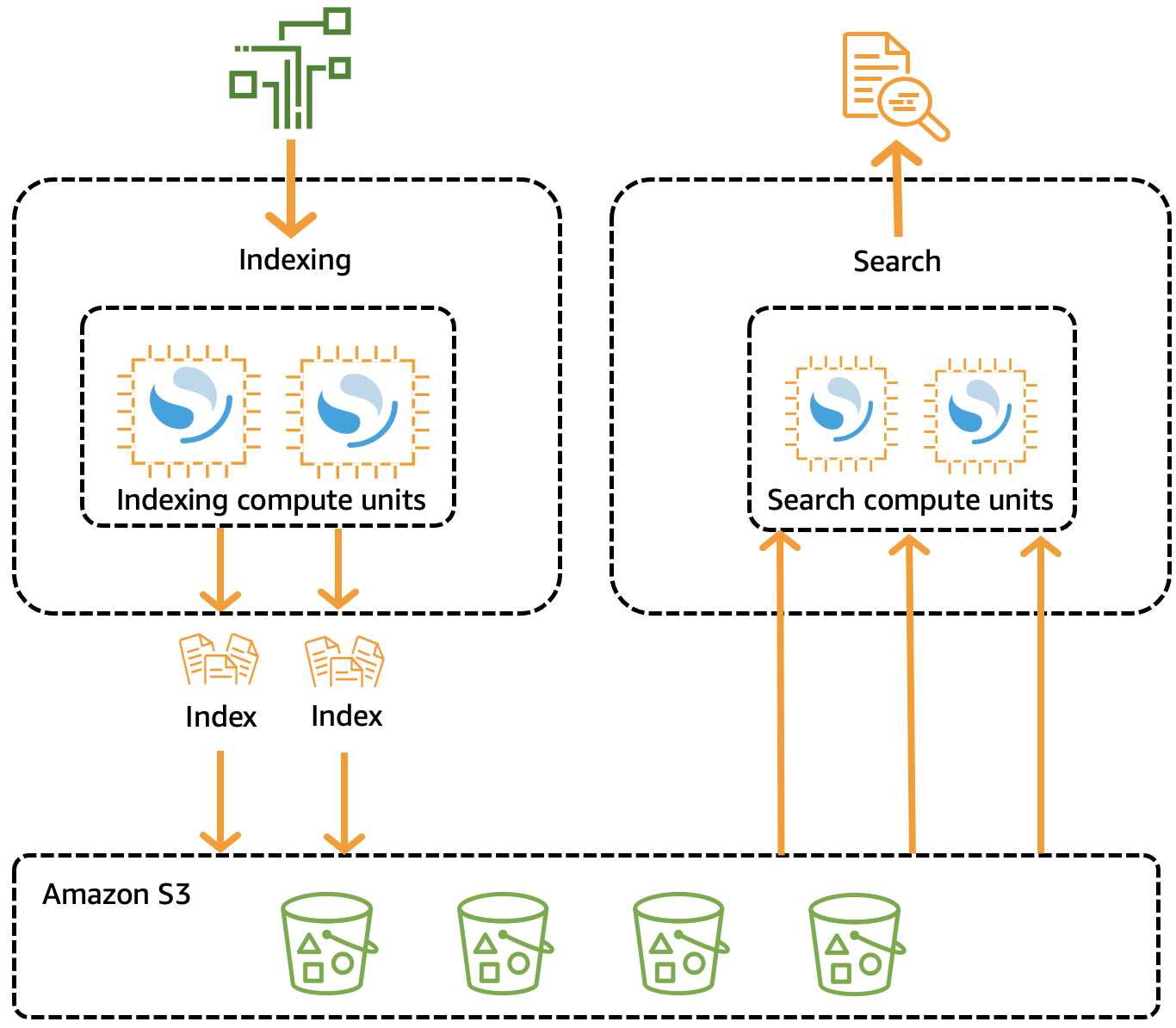
データインジェスト、検索、およびクエリの実行に必要な OpenSearch Serverless のコンピューティング性能は、OpenSearch Compute Unit (OCU) で測定されます。各 OCU は、6 GiB のメモリと対応する仮想 CPU (vCPU)、および Amazon S3 へのデータ転送を組み合わせたものです。
OpenSearch Serverless OCUs を個別にプロビジョニングします。OpenSearch Serverless OCUs を追加します。 キャパシティの設定キャパシティーは、コンピューティング使用量の減少に伴ってスケールダウンされます。
これらの OCUs」を参照してください。 OpenSearch
コレクションタイプを選択する
OpenSearch Serverless は、主に次の 3 つのコレクションタイプをサポートしています。
[時系列] – 大量の半構造化マシン生成データをリアルタイムで分析し、運用、セキュリティ、ユーザー行動、およびビジネスパフォーマンスに関するインサイトを提供するログ分析セグメント。
注記
時系列コレクションは Classic コレクションでのみ使用できます。NextGen コレクションは現在、検索タイプとベクトル検索タイプのみをサポートしています。
[検索] – 社内ネットワーク内のアプリケーション (コンテンツ管理システム、法的ドキュメントレポジトリ) や、e コマースウェブサイト検索やコンテンツ検出などのインターネット向けアプリケーションをサポートする全文検索機能。
[ベクトル検索] – ベクトル埋め込みのセマンティック検索は、ベクトルデータ管理を簡素化し、機械学習 (ML) で拡張された検索エクスペリエンスを実現します。チャットボット、パーソナルアシスタント、不正検出などの生成 AI アプリケーションをサポートします。
コレクションを初めて作成するときに、コレクションタイプを選択します。
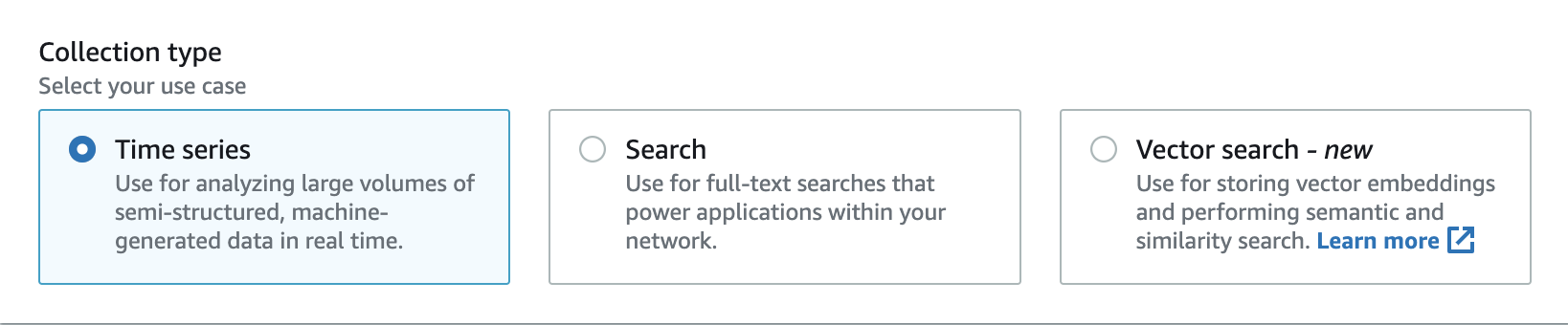
選択するコレクションタイプは、コレクションに取り込む予定のデータの種類と、そのデータへのクエリ実行方法によって異なります。コレクションの作成後にコレクションタイプを変更することはできません。
コレクションタイプには、次の大きな違いがあります。
-
検索およびベクトル検索コレクションでは、迅速なクエリ応答時間を確保するため、すべてのデータがホットストレージに保存されます。時系列コレクションは、ホットストレージとウォームストレージを組み合わせて使用します。この場合、より頻繁にアクセスされるデータのクエリ応答時間を最適化するために、最新のデータがホットストレージに保存されます。
-
時系列コレクションの場合、カスタムドキュメント ID でインデックスを作成したり、アップサートリクエストで更新したりすることはできません。この操作は検索のユースケース専用です。代わりにドキュメント ID を使用して更新できます。詳細については、「サポートされる OpenSearch API オペレーションとアクセス許可」を参照してください。
-
検索および時系列コレクションの場合、k-NN タイプのインデックスは使用できません。
サポートされている AWS リージョン
OpenSearch Serverless は、OpenSearch Service AWS リージョン が利用可能な のサブセットで使用できます。サポートされているリージョンのリストについては、「AWS 全般のリファレンス」の「Amazon OpenSearch Service エンドポイントとクォータ」を参照してください。
制限事項
OpenSearch Serverless には次の制約事項があります。
-
一部の OpenSearch API オペレーションがサポートされていません。「サポートされる OpenSearch API オペレーションとアクセス許可」を参照してください。
-
一部の OpenSearch プラグインがサポートされていません。「サポートされている OpenSearch プラグイン」を参照してください。
-
現在、マネージド型の OpenSearch Service ドメインから Serverless コレクションにデータを自動的に移行する方法はありません。ドメインからコレクションにデータを再インデックスする必要があります。
-
コレクションへのクロスアカウントアクセスはサポートされていません。他のアカウントからのコレクションを暗号化またはデータアクセスポリシーに含めることはできません。
-
カスタムの OpenSearch プラグインはサポートされていません。
-
自動スナップショットは、OpenSearch Serverless コレクションでサポートされています。手動スナップショットはサポートされていません。詳細については、「スナップショットを使用したコレクションのバックアップ」を参照してください。
-
クロスリージョン検索およびレプリケーションはサポートされていません。
-
1 つのアカウントおよびリージョンで使用できるサーバーレスリソースの数には制限があります。「OpenSearch Serverless のクォータ」を参照してください。
-
検索コレクションと時系列コレクションのインデックスの更新間隔は約 10 秒です。
-
シャードの数、間隔の数、更新間隔は変更できず、OpenSearch サーバーレス によって処理されます。シャーディング戦略はコレクションタイプとトラフィックに基づいています。例えば、時系列コレクションでは、書き込みトラフィックのボトルネックに基づいてプライマリシャードをスケーリングします。
