翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Neptune ML の Gremlin 推論クエリ
Neptune ML 機能 で説明しているように、Neptune ML は次の種類の推論タスクを実行できるトレーニングモデルをサポートしています。
ノード分類 — 頂点プロパティのカテゴリカル特徴を予測します。
ノードリグレッション — 頂点の数値プロパティを予測します。
エッジ分類 — エッジプロパティのカテゴリ別特徴を予測します。
エッジリグレッション — エッジの数値プロパティを予測します。
リンク予測 — 始点ノードと送信エッジが与えられた終点ノード、または終点ノードと着信エッジを指定した始点ノードを予測します。
これらのさまざまなタスクを、GroupLens Reserch
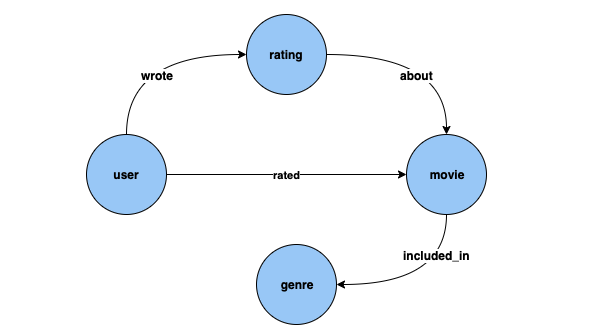
ノード分類: 上記のデータセットでは、Genre は、エッジ included_in によって頂点タイプ Movie に接続されている頂点タイプです。ただし、データセットを微調整して Genre を頂点タイプ Movie のカテゴリ別Genre は、ノード分類モデルを使用して解くことができます。
ノードリグレッション: 頂点タイプ Rating を、timestamp および score のようなプロパティを持つと考えると、Rating に対する数値 Score を推論する問題は、ノードリグレッションモデルを使用して解くことができます。
エッジ分類: 同様に、Rated エッジに関して、Love、Like、Dislike、Neutral、Hate のうち 1 つの値となる可能性があるプロパティ Scale がある場合、新しい映画/レーティング Rated エッジに対する推論の問題 Scale は、エッジ分類モデルを使用して解けます。
エッジリグレッション: 同様に、同じように Rated エッジに関して、レーティングの数値を保持する Score プロパティがある場合、これはエッジリグレッションモデルから推測できます。
リンク予測: 特定の映画を評価する可能性が最も高い上位 10 人のユーザーを見つけたり、特定のユーザーが評価する可能性が最も高い上位 10 本の映画を見つけたりするなどの問題は、リンク予測に該当します。
注記
Neptune ML ユースケースについては、各ユースケースについて実践的に理解できるように設計された非常に豊富なノートブックセットがあります。Neptune ML CloudFormation テンプレートを使用して Neptune ML クラスターを作成するときに、これらのノートブックを Neptune クラスターと一緒に作成できます。これらのノートブックは、GitHub
トピック
