翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# Lake Formation でのオープンテーブルストレージフォーマットのアクセス許可の設定
AWS Lake Formation は、[Apache Iceberg](https://iceberg.apache.org/)、[Apache Hudi](https://hudi.incubator.apache.org/)、[Linux 基盤 Delta Lake](https://delta.io/) などの *Open Table Formats* (OTFs) のアクセス許可の管理をサポートしています。このチュートリアルでは、 AWS Glue Data Catalog でシンボリックリンク[マニフェスト](https://docs.delta.io/latest/presto-integration.html)テーブルを使用して Iceberg、Hudi、Delta Lake を作成し AWS Glue、Lake Formation を使用してきめ細かなアクセス許可を設定し、Amazon Athena を使用してデータをクエリする方法について説明します。
**注記**
AWS 分析サービスは、すべてのトランザクションテーブル形式をサポートしているわけではありません。詳細については、「[他の AWS サービスの使用](working-with-services.md)」を参照してください。このチュートリアルでは、 AWS Glue ジョブのみを使用して、データカタログに新しいデータベースとテーブルを手動で作成する方法について説明します。
このチュートリアルには、クイックセットアップ用の AWS CloudFormation テンプレートが含まれています。このテンプレートを参照し、ニーズに合わせてカスタマイズできます。
**Topics**
+ [対象者](#tut-otf-roles)
+ [前提条件](#tut-otf-prereqs)
+ [ステップ 1: リソースをプロビジョニングする](#set-up-otf-resources)
+ [ステップ 2: Iceberg テーブルのアクセス許可をセットアップする](#set-up-iceberg-table)
+ [ステップ 3: Hudi テーブルのアクセス許可をセットアップする](#set-up-hudi-table)
+ [ステップ 4: Delta Lake テーブルのアクセス許可をセットアップする](#set-up-delta-table)
+ [ステップ 5: AWS リソースをクリーンアップする](#otf-tut-clean-up)
## 対象者
このチュートリアルは、IAM 管理者、データレイク管理者、ビジネスアナリストを対象としています。次の表は、このチュートリアルで Lake Formation による管理対象テーブルの作成に使用するロールのリストです。
| ロール | 説明 |
| --- | --- |
| IAM 管理者 | IAM ユーザーおよびロール、Amazon S3 バケットを作成できるユーザー。AdministratorAccess AWS 管理ポリシーがあります。 |
| データレイク管理者 | Data Catalog へのアクセス、データベースの作成、および他のユーザーへの Lake Formation 許可の付与を実行できるユーザー。IAM 許可の数は IAM 管理者よりも少ないですが、データレイクを管理するには十分な許可を持っています。 |
| ビジネスアナリスト | データレイクに対してクエリを実行できるユーザー。クエリを実行するためのアクセス許可を持っています。 |
## 前提条件
このチュートリアルを開始する前に、正しいアクセス許可を持つユーザーとしてサインイン AWS アカウント できる が必要です。詳細については、「[にサインアップする AWS アカウント](getting-started-setup.md#sign-up-for-aws)」および「[管理アクセスを持つユーザーを作成する](getting-started-setup.md#create-an-admin)」を参照してください。
このチュートリアルでは、ユーザーが IAM のロールおよびポリシーに精通していることを前提としています。IAM については、「[IAM ユーザーガイド](https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html)」を参照してください。
このチュートリアルを完了するには、次の AWS リソースを設定する必要があります。
+ データレイク管理ユーザー
+ Lake Formation データレイクの設定
+ Amazon Athena エンジンバージョン 3
**データレイク管理者を作成するには**
1. Lake Formation コンソール ([https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/)) に管理者ユーザーとしてサインインします。このチュートリアルでは、米国東部 (バージニア北部) リージョンにリソースを作成します。
1. ナビゲーションペインの Lake Formation コンソールの **[許可]** で **[管理ロールとタスク]** を選択します。
1. **[データレイク管理者]** で **[管理者を選択]** を選択します。
1. ポップアップウィンドウの **[データレイク管理者の管理]** の **[IAM ユーザーとロール]** で、**[IAM 管理者ユーザー]** を選択します。
1. **[保存]** を選択します。
**データレイク設定を有効にするには**
1. Lake Formation コンソール ([https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/)) を開きます。ナビゲーションペインの **[Data catalog]** で **[Settings]** (設定) を選択します。次のチェックを外します。
+ 新しいデータベースには IAM アクセスコントロールのみを使用する。
+ 新しいデータベース内の新しいテーブルには IAM アクセスコントロールのみを使用する。
1. **[クロスアカウントバージョン設定]** で、クロスアカウントバージョンとして **[バージョン 3]** を選択します。
1. **[保存]** を選択します。
**Amazon Athena エンジンをバージョン 3 にアップグレードするには**
1. [https://console.aws.amazon.com/athena/](https://console.aws.amazon.com/athena/home) で Athena コンソールを開きます。
1. **[ワークグループ]** を選択し、プライマリワークグループを選択します。
1. ワークグループのバージョンが 3 以上であることを確認してください。そうでない場合は、ワークグループを編集し、**[クエリエンジンのアップグレード]** で **[手動]** を選択し、バージョン 3 を選択します。
1. **[Save changes]** (変更の保存) をクリックします。
## ステップ 1: リソースをプロビジョニングする
このセクションでは、 CloudFormation テンプレートを使用して AWS リソースを設定する方法について説明します。
**CloudFormation テンプレートを使用してリソースを作成するには**
1. 米国東部 (バージニア北部) リージョンの IAM 管理者として [https://console.aws.amazon.com/cloudformation](https://console.aws.amazon.com/cloudformation/) で AWS CloudFormation コンソールにサインインします。
1. [[スタックの起動]](https://us-east-1.console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks/new?templateURL=https://lf-public.s3.amazonaws.com/cfn/lfotfsetup.template) を選択します。
1. **[Create Stack]** (スタックの作成) 画面で、**[Next]** (次へ) を選択します。
1. **[Stack name]** (スタック名) を入力します。
1. [**次へ**] を選択します。
1. 次のページで、**[Next]** (次へ) を選択します。
1. 最終ページの詳細を確認し、**IAM リソースを作成する AWS CloudFormation 可能性があることを確認します。**
1. **[作成]** を選択します。
スタックの作成には、最大 2 分かかる場合があります。
クラウドフォーメーションスタックを起動すると、以下のリソースが作成されます。
+ lf-otf-datalake-123456789012 – データを保存する Amazon S3 バケット
**注記**
Amazon S3 バケット名に追加されたアカウント ID は、アカウント ID に置き換えられます。
+ lf-otf-tutorial-123456789012 – クエリ結果と AWS Glue ジョブスクリプトを保存する Amazon S3 バケット
+ lficebergdb – AWS Glue Iceberg データベース
+ lfhudidb – AWS Glue Hudi データベース
+ lfdeltadb – AWS Glue デルタデータベース
+ native-iceberg-create – データカタログに Iceberg テーブルを作成する AWS Glue ジョブ
+ native-hudi-create – データカタログに Hudi テーブルを作成する AWS Glue ジョブ
+ native-delta-create – データカタログに Delta テーブルを作成する AWS Glue ジョブ
+ LF-OTF-GlueServiceRole – ジョブを実行する AWS Glue ために渡す IAM ロール。このロールには、Data Catalog、Amazon S3 バケットなどのリソースにアクセスするために必要なポリシーがアタッチされています。
+ LF-OTF-RegisterRole – Amazon S3 ロケーションを Lake Formation に登録するための IAM ロール。このロールには、`LF-Data-Lake-Storage-Policy` が関連付けられています。
+ lf-consumer-analystuser – Athena を使用してデータをクエリする IAM ユーザー
+ lf-consumer-analystuser-credentials – に保存されているデータアナリストユーザーのパスワード AWS Secrets Manager
スタックの作成が完了したら、出力タブに移動して、次の値を書き留めます。
+ AthenaQueryResultLocation – Athena クエリ出力の Amazon S3 ロケーション
+ BusinessAnalystUserCredentials – データアナリストユーザーのパスワード
パスワード値を取得するには:
1. Secrets Manager コンソールに移動して、`lf-consumer-analystuser-credentials` 値を選択します。
1. **[シークレット値]** セクションで、**[シークレット値の取得]** を選択します。
1. パスワードのシークレット値を書き留めておきます。
## ステップ 2: Iceberg テーブルのアクセス許可をセットアップする
このセクションでは、 で Iceberg テーブルを作成し AWS Glue Data Catalog、 でデータアクセス許可を設定し AWS Lake Formation、Amazon Athena を使用してデータをクエリする方法について説明します。
**Iceberg テーブルを作成するには**
このステップでは、データカタログに Iceberg トランザクションテーブルを作成する AWS Glue ジョブを実行します。
1. データレイク管理者ユーザーとして、米国東部 (バージニア北部) リージョンの [https://console.aws.amazon.com/glue/](https://console.aws.amazon.com/glue/) で AWS Glue コンソールを開きます。
1. 左側のナビゲーションペインで、**[ジョブ]** を選択します。
1. `native-iceberg-create` を選択します。
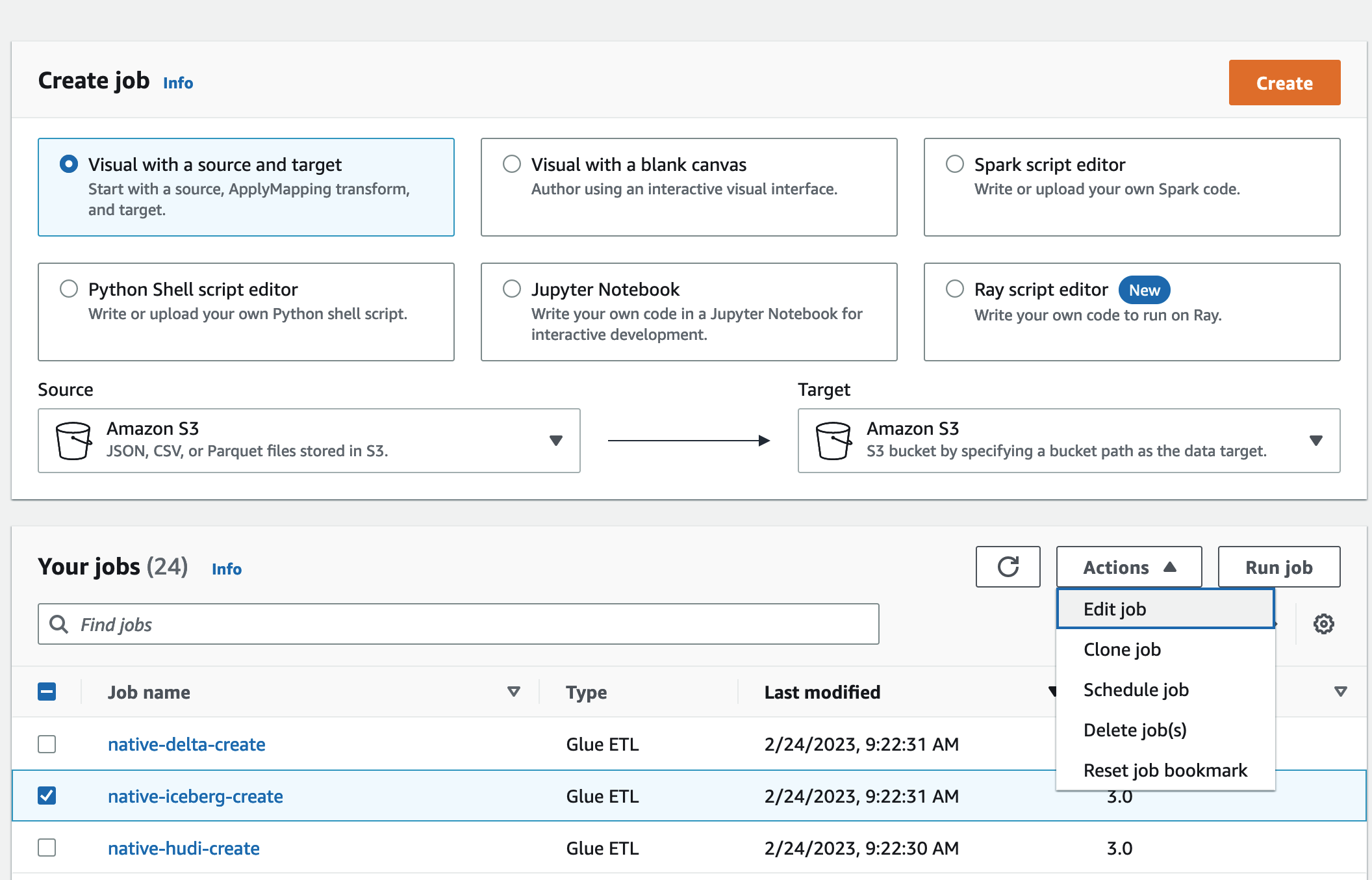
1. **[アクション]** で **[ジョブの編集]** を選択します。
1. **ジョブの詳細**で、**高度なプロパティ**を展開し、**Hive メタストア AWS Glue Data Catalog として使用 の横にあるチェックボックス**をオンにして、 にテーブルメタデータを追加します AWS Glue Data Catalog。これは、ジョブで使用される Data Catalog リソースのメタストア AWS Glue Data Catalog として を指定し、後で Lake Formation のアクセス許可をカタログリソースに適用できるようにします。
1. **[保存]** を選択します。
1. [**Run (実行)**] を選択します。実行中、ジョブのステータスを表示できます。
AWS Glue ジョブの詳細については、「 *AWS Glue デベロッパーガイド*」の「 [AWS Glue コンソールでのジョブの使用](https://docs.aws.amazon.com/glue/latest/dg/console-jobs.html)」を参照してください。
このジョブは、`lficebergdb` データベースに `product` という名前を付けた Iceberg テーブルを作成します。Lake Formation コンソールの製品テーブルを確認してください。
**データロケーションを Lake Formation に登録するには**
次に、Amazon S3 パスをデータレイクのロケーションとして登録します。
1. Lake Formation コンソール ([https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/)) をデータレイク管理者ユーザーとして開きます。
1. ナビゲーションペインの **[登録および取り込み]** で **[データレイクのロケーション]** を選択します。
1. コンソールの右上で、**[ロケーションを登録]** を選択します。
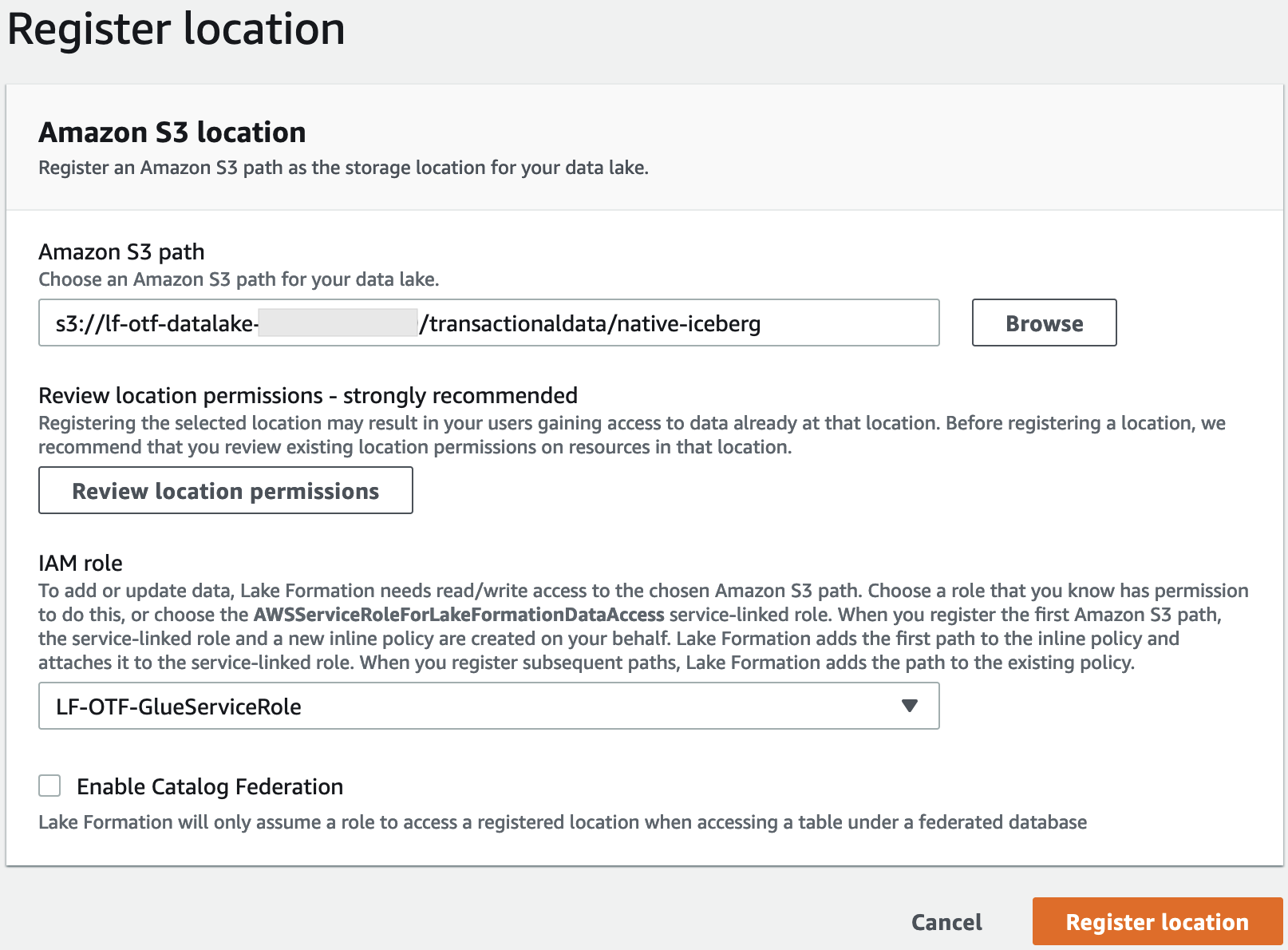
1. **[ロケーションを登録]** ページで、次のように入力します。
+ **[Amazon S3 パス]** – **[ブラウズ]** を選択して `lf-otf-datalake-123456789012` を選択します。Amazon S3 ルートロケーションの横にある右矢印 (>) をクリックして、`s3/buckets/lf-otf-datalake-123456789012/transactionaldata/native-iceberg` ロケーションに移動します。
+ **[IAM ロール]** – IAM ロールとして `LF-OTF-RegisterRole` を選択します。
+ **[Register location]** (ロケーションを登録) を選択します。
データロケーションを Lake Formation へ登録する方法の詳細については、「[データレイクへの Amazon S3 ロケーションの追加](register-data-lake.md)」を参照してください。
**Iceberg テーブルで Lake Formation の権限を付与するには**
このステップでは、ビジネスアナリストユーザーにデータレイクのアクセス許可を付与します。
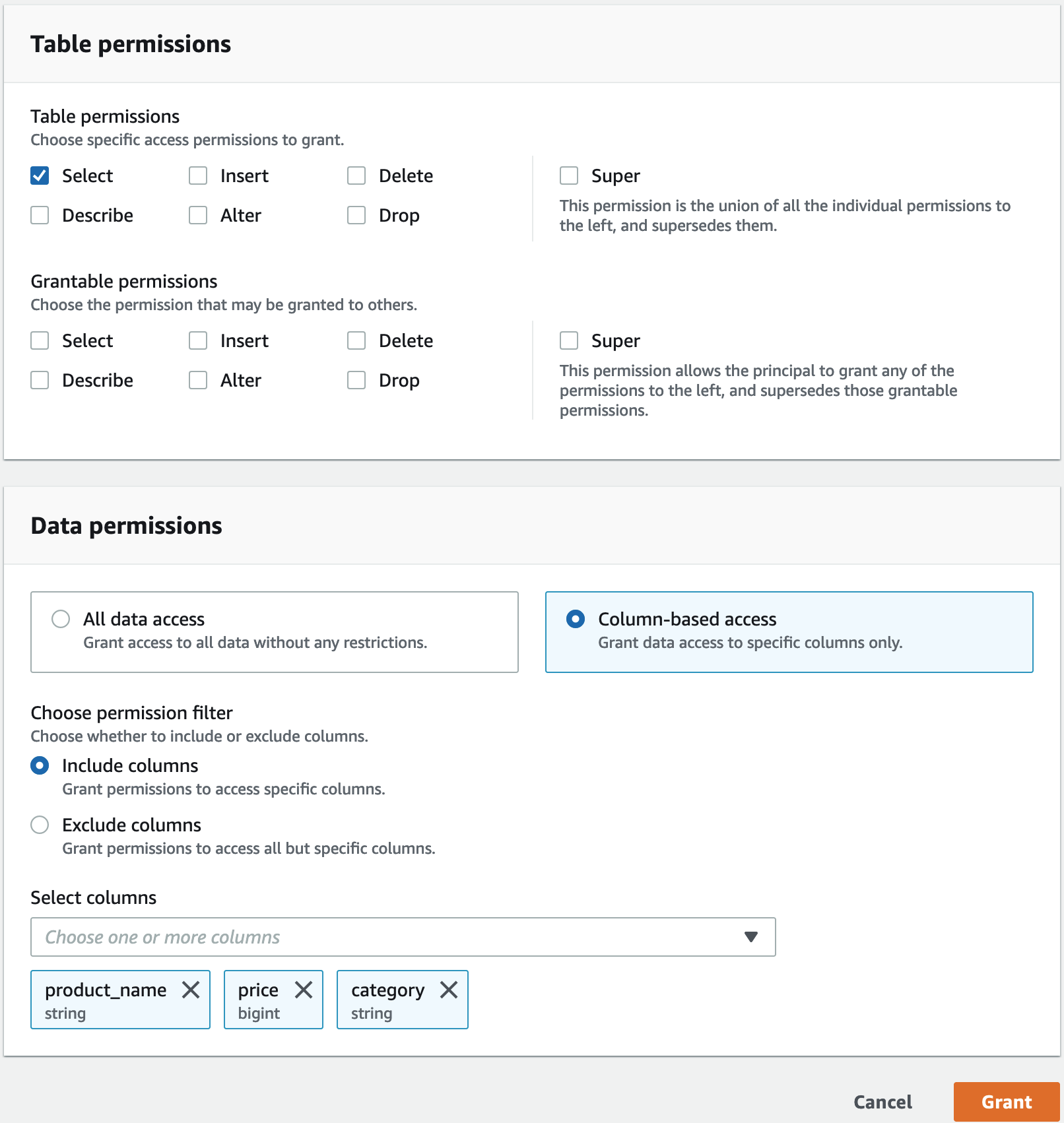
1. **[データレイクのアクセス許可]** で、**[付与]** を選択します。
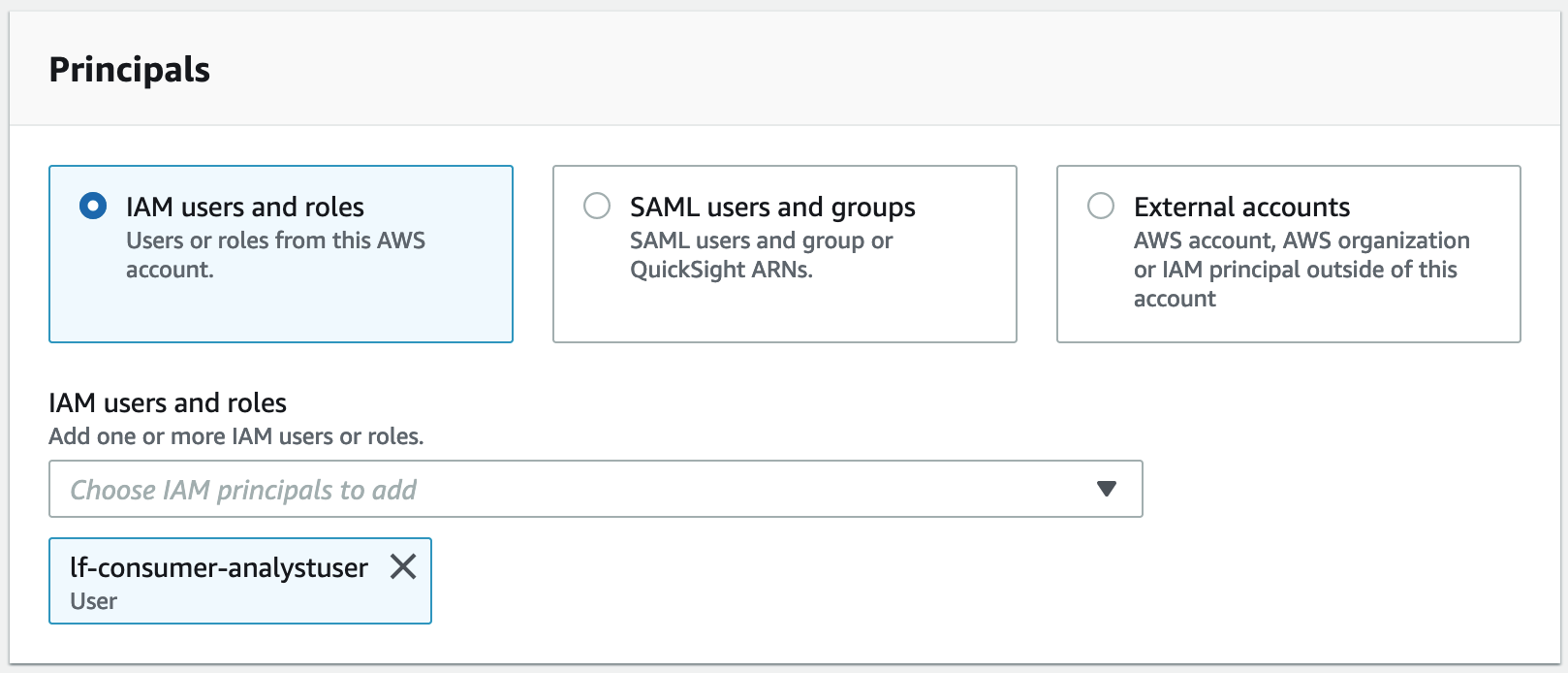
1. **[データのアクセス許可の付与]** 画面で、**[IAM ユーザーとロール]** を選択します。
1. ドロップダウンリストから [`lf-consumer-analystuser`] を選択します。
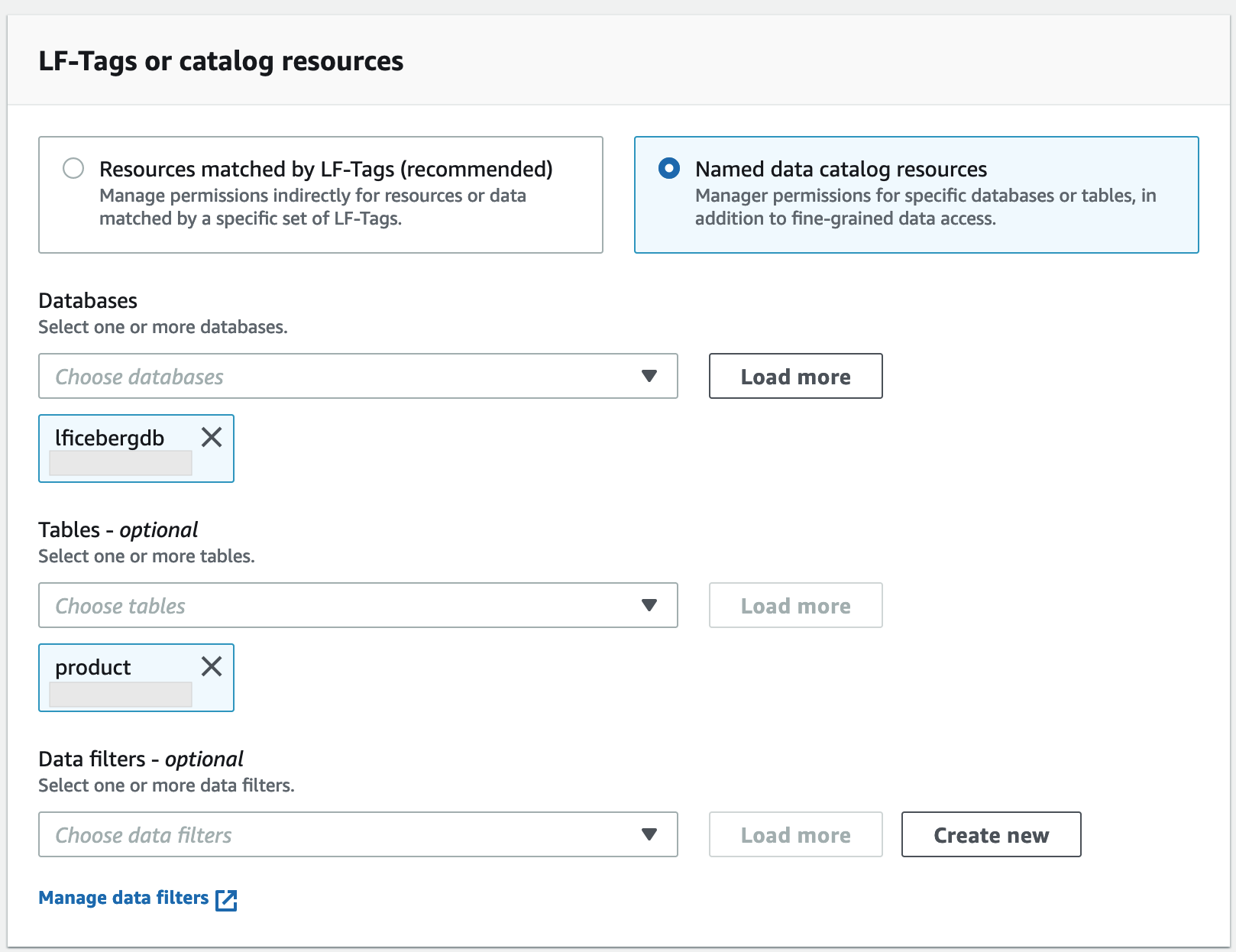
1. **[名前付きの Data Catalog リソース]** を選択します。
1. **[データベース]** には `lficebergdb` を選択します。
1. **[Tables]** (テーブル) には `product` を選択します。
1. 次に、列を指定して列ベースのアクセスを許可できます。
1. **[テーブル許可]** には **[選択]** を選択します。
1. **[データのアクセス許可]** で **[列ベースのアクセス]** を選択し、**[列を含める]** を選択します。
1. `product_name`、`price`、`category` 列を選択します。
1. **[付与]** を選択します。
**Athena を使用して Iceberg テーブルをクエリするには**
ここで Athena を使用し、作成した Iceberg テーブルに対するクエリを開始します。初めて Athena でクエリを実行する場合は、クエリ結果の場所を設定する必要があります。詳細については、「[クエリ結果の場所の指定](https://docs.aws.amazon.com/athena/latest/ug/querying.html#query-results-specify-location)」を参照してください。
1. データレイク管理者ユーザーとしてサインアウトし、 CloudFormation 出力から前に書き留めたパスワードを使用して、米国東部 (バージニア北部) リージョン`lf-consumer-analystuser`で としてサインインします。
1. [https://console.aws.amazon.com/athena/](https://console.aws.amazon.com/athena/home) で Athena コンソールを開きます。
1. **[設定]** を選択し、**[管理]** を選択します。
1. **クエリ結果の場所** ボックスに、 CloudFormation 出力で作成したバケットへのパスを入力します。`AthenaQueryResultLocation` (s3://lf-otf-tutorial-123456789012/athena-results/) の値をコピーして、**[保存]** を選択します。
1. 次のクエリを実行して、Iceberg テーブルに保存されている 10 個のレコードをプレビューします。
```
select * from lficebergdb.product limit 10;
```
Athena を使用して Iceberg テーブルをクエリする方法の詳細については、「*Amazon Athena ユーザーガイド*」の「[Iceberg テーブルへのクエリ](https://docs.aws.amazon.com/athena/latest/ug/querying-iceberg-table-data.html)」を参照してください。
## ステップ 3: Hudi テーブルのアクセス許可をセットアップする
このセクションでは、 で Hudi テーブルを作成し AWS Glue Data Catalog、 でデータアクセス許可を設定し AWS Lake Formation、Amazon Athena を使用してデータをクエリする方法について説明します。
**Hudi テーブルを作成するには**
このステップでは、データカタログに Hudi トランザクションテーブルを作成する AWS Glue ジョブを実行します。
1. 米国東部 (バージニア北部) リージョンで AWS Glue コンソール ([https://console.aws.amazon.com/glue/](https://console.aws.amazon.com/glue/)) にサインインします。
データレイク管理ユーザーとして開きます。
1. 左側のナビゲーションペインで、**[ジョブ]** を選択します。
1. `native-hudi-create` を選択します。
1. **[アクション]** で **[ジョブの編集]** を選択します。
1. **ジョブの詳細**で、**高度なプロパティ**を展開し、**Hive メタストア AWS Glue Data Catalog として使用 の横にあるチェックボックス**をオンにして、 にテーブルメタデータを追加します AWS Glue Data Catalog。これは、ジョブで使用される Data Catalog リソースのメタストア AWS Glue Data Catalog として を指定し、後で Lake Formation のアクセス許可をカタログリソースに適用できるようにします。
1. **[保存]** を選択します。
1. [**Run (実行)**] を選択します。実行中、ジョブのステータスを表示できます。
AWS Glue ジョブの詳細については、「 *AWS Glue デベロッパーガイド*」の「 [AWS Glue コンソールでのジョブの使用](https://docs.aws.amazon.com/glue/latest/dg/console-jobs.html)」を参照してください。
このジョブは、データベース:lfhudidb に Hudi(cow) テーブルを作成します。Lake Formation コンソールの `product` テーブルを確認してください。
**データロケーションを Lake Formation に登録するには**
次に、Amazon S3 パスをデータレイクのルートロケーションとして登録します。
1. Lake Formation コンソール ([https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/)) にデータレイク管理者ユーザーとしてサインインします。
1. ナビゲーションペインの **[登録および取り込み]** で **[データレイクのロケーション]** を選択します。
1. コンソールの右上で、**[ロケーションを登録]** を選択します。
1. **[ロケーションを登録]** ページで、次のように入力します。
+ **[Amazon S3 パス]** – **[ブラウズ]** を選択して `lf-otf-datalake-123456789012` を選択します。Amazon S3 ルートロケーションの横にある右矢印 (>) をクリックして、`s3/buckets/lf-otf-datalake-123456789012/transactionaldata/native-hudi` ロケーションに移動します。
+ **[IAM ロール]** – IAM ロールとして `LF-OTF-RegisterRole` を選択します。
+ **[Register location]** (ロケーションを登録) を選択します。
**Hudi テーブルでデータレイクのアクセス許可を付与するには**
このステップでは、ビジネスアナリストユーザーにデータレイクのアクセス許可を付与します。
1. **[データレイクのアクセス許可]** で、**[付与]** を選択します。
1. **[データのアクセス許可の付与]** 画面で、**[IAM ユーザーとロール]** を選択します。
1. ドロップダウンから `lf-consumer-analystuser`。
1. **[名前付きのデータカタログリソース]** を選択します。
1. **[データベース]** には `lfhudidb` を選択します。
1. **[Tables]** (テーブル) には `product` を選択します。
1. 次に、列を指定して列ベースのアクセスを許可できます。
1. **[テーブル許可]** には **[選択]** を選択します。
1. **[データのアクセス許可]** で **[列ベースのアクセス]** を選択し、**[列を含める]** を選択します。
1. `product_name`、`price`、`category` 列を選択します。
1. **[付与]** を選択します。
**Athena を使用して Hudi テーブルをクエリするには**
ここで Athena を使用し、作成した Hudi テーブルに対するクエリを開始します。初めて Athena でクエリを実行する場合は、クエリ結果の場所を設定する必要があります。詳細については、「[クエリ結果の場所の指定](https://docs.aws.amazon.com/athena/latest/ug/querying.html#query-results-specify-location)」を参照してください。
1. データレイク管理者ユーザーとしてサインアウトし、 CloudFormation 出力から前に書き留めたパスワードを使用して、米国東部 (バージニア北部) リージョン`lf-consumer-analystuser`で としてサインインします。
1. [https://console.aws.amazon.com/athena/](https://console.aws.amazon.com/athena/home) で Athena コンソールを開きます。
1. **[設定]** を選択し、**[管理]** を選択します。
1. **クエリ結果の場所** ボックスに、 CloudFormation 出力で作成したバケットへのパスを入力します。`AthenaQueryResultLocation` (s3://lf-otf-tutorial-123456789012/athena-results/) の値をコピーして、**[保存]** します。
1. 次のクエリを実行して、Hudi テーブルに保存されている 10 個のレコードをプレビューします。
```
select * from lfhudidb.product limit 10;
```
Hudi テーブルをクエリする方法の詳細については、「*Amazon Athena ユーザーガイド*」の「[Hudi テーブルのクエリ](https://docs.aws.amazon.com/athena/latest/ug/querying-hudi.html)」を参照してください。
## ステップ 4: Delta Lake テーブルのアクセス許可をセットアップする
このセクションでは、 にシンボリックリンクマニフェストファイルを含む Delta Lake テーブルを作成し、 でデータアクセス許可を設定し AWS Glue Data Catalog、Amazon Athena を使用してデータを AWS Lake Formation クエリする方法について説明します。
**Delta Lake テーブルを作成するには**
このステップでは、データカタログに Delta Lake トランザクションテーブルを作成する AWS Glue ジョブを実行します。
1. 米国東部 (バージニア北部) リージョンで AWS Glue コンソール ([https://console.aws.amazon.com/glue/](https://console.aws.amazon.com/glue/)) にサインインします。
データレイク管理ユーザーとして開きます。
1. 左側のナビゲーションペインで、**[ジョブ]** を選択します。
1. `native-delta-create` を選択します。
1. **[アクション]** で **[ジョブの編集]** を選択します。
1. **ジョブの詳細**で、**高度なプロパティ**を展開し、**Hive メタストア AWS Glue Data Catalog として使用** の横にあるチェックボックスをオンにして、 にテーブルメタデータを追加します AWS Glue Data Catalog。これは、ジョブで使用される Data Catalog リソースのメタストア AWS Glue Data Catalog として を指定し、後で Lake Formation のアクセス許可をカタログリソースに適用できるようにします。
1. **[保存]** を選択します。
1. **[アクション]** で **[実行]** を選択します。
このジョブは、`lfdeltadb` データベースに `product` という名前を付けた Delta Lake テーブルを作成します。Lake Formation コンソールの `product` テーブルを確認してください。
**データロケーションを Lake Formation に登録するには**
次に、Amazon S3 パスをデータレイクのルートロケーションとして登録します。
1. Lake Formation コンソール ([https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/)) をデータレイク管理者ユーザーとして開きます。
1. ナビゲーションペインの **[登録および取り込み]** で **[データレイクのロケーション]** を選択します。
1. コンソールの右上で、**[ロケーションを登録]** を選択します。
1. **[ロケーションを登録]** ページで、次のように入力します。
+ **[Amazon S3 パス]** – **[ブラウズ]** を選択して `lf-otf-datalake-123456789012` を選択します。Amazon S3 ルートロケーションの横にある右矢印 (>) をクリックして、`s3/buckets/lf-otf-datalake-123456789012/transactionaldata/native-delta` ロケーションに移動します。
+ **[IAM ロール]** – IAM ロールとして `LF-OTF-RegisterRole` を選択します。
+ **[Register location]** (ロケーションを登録) を選択します。
**Delta Lake テーブルでデータレイクのアクセス許可を付与するには**
このステップでは、ビジネスアナリストユーザーにデータレイクのアクセス許可を付与します。
1. **[データレイクのアクセス許可]** で、**[付与]** を選択します。
1. **[データのアクセス許可の付与]** 画面で、**[IAM ユーザーとロール]** を選択します。
1. ドロップダウンから `lf-consumer-analystuser`。
1. **[名前付きのデータカタログリソース]** を選択します。
1. **[データベース]** には `lfdeltadb` を選択します。
1. **[Tables]** (テーブル) には `product` を選択します。
1. 次に、列を指定して列ベースのアクセスを許可できます。
1. **[テーブル許可]** には **[選択]** を選択します。
1. **[データのアクセス許可]** で **[列ベースのアクセス]** を選択し、**[列を含める]** を選択します。
1. `product_name`、`price`、`category` 列を選択します。
1. **[付与]** を選択します。
**Athena を使用した Delta Lake テーブルをクエリするには**
ここで Athena を使用し、作成した Delta Lake テーブルに対するクエリを開始します。初めて Athena でクエリを実行する場合は、クエリ結果の場所を設定する必要があります。詳細については、「[クエリ結果の場所の指定](https://docs.aws.amazon.com/athena/latest/ug/querying.html#query-results-specify-location)」を参照してください。
1. データレイク管理者ユーザーとしてログアウトし、 CloudFormation 出力から前に書き留めたパスワードを使用して、米国東部 (バージニア北部) リージョン`BusinessAnalystUser`で としてログインします。
1. [https://console.aws.amazon.com/athena/](https://console.aws.amazon.com/athena/home) で Athena コンソールを開きます。
1. **[設定]** を選択し、**[管理]** を選択します。
1. **クエリ結果の場所** ボックスに、 CloudFormation 出力で作成したバケットへのパスを入力します。`AthenaQueryResultLocation` (s3://lf-otf-tutorial-123456789012/athena-results/) の値をコピーして、**[保存]** します。
1. 次のクエリを実行して、Delta Lake テーブルに保存されている 10 個のレコードをプレビューします。
```
select * from lfdeltadb.product limit 10;
```
Delta Lake テーブルをクエリする方法の詳細については、「*Amazon Athena ユーザーガイド*」の「[Delta Lake テーブルのクエリ](https://docs.aws.amazon.com/athena/latest/ug/delta-lake-tables.html)」を参照してください。
## ステップ 5: AWS リソースをクリーンアップする
**リソースをクリーンアップするには**
への不要な請求を防ぐには AWS アカウント、このチュートリアルで使用した AWS リソースを削除します。
1. IAM 管理者として [https://console.aws.amazon.com/cloudformation](https://console.aws.amazon.com/cloudformation/) の CloudFormation コンソールにサインインします。
1. [CloudFormation スタックを削除](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-console-delete-stack.html)します。作成したテーブルは、スタックと共に自動的に削除されます。