翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
外部メタストアを使用するデータセットのアクセス許可の管理
AWS Glue Data Catalog メタデータフェデレーション (データカタログフェデレーション) を使用すると、データカタログを Amazon S3 データのメタデータを保存する外部メタストアに接続し、 を使用してデータアクセス許可を安全に管理できます AWS Lake Formation。メタデータを外部メタストアからデータカタログに移行する必要はありません。
データカタログは、一元化されたメタデータリポジトリを提供し、異種システム間でのデータの管理と発見を容易にします。組織がデータカタログ内のデータを管理する場合、 AWS Lake Formation を使用して Amazon S3 内のデータセットへのアクセスを制御できます。
注記
現在、Apache Hive (バージョン 3 以降) メタストアフェデレーションのみをサポートしています。
データカタログフェデレーションを設定するには、 で GlueDataCatalogFederation-HiveMetastore
リファレンス実装は、AWS Glue Data Catalog フェデレーション - Hive メタストア
AWS SAM アプリケーションは、データカタログを Hive メタストアに接続するために必要な次のリソースを作成してデプロイします。
AWS Lambda 関数 – データカタログと Hive metastore の間で通信するフェデレーションサービスの実装をホストします。 は、この Lambda 関数を AWS Glue 呼び出して Hive メタストアからメタデータオブジェクトを取得します。
Amazon API Gateway – すべての呼び出しを Lambda 関数にルーティングするプロキシとして機能する Hive メタストアの接続エンドポイント。
IAM ロール - データカタログと Hive メタストア間の接続を作成するために必要なアクセス許可を持つロール。
AWS Glue connection – Amazon API Gateway エンドポイントと、エンドポイントを呼び出す IAM ロールを保存する AWS Glue 接続 Amazon API Gateway のタイプ。
テーブルをクエリすると、 AWS Glue サービスは Hive メタストアへのランタイム呼び出しを行い、メタデータを取得します。Lambda 関数は、Hive メタストアとデータカタログ間のトランスレータとして機能します。
接続を確立した後、Hive メタストアのメタデータをデータカタログと同期するために、Hive メタストア接続の詳細を使用してデータカタログにフェデレーションデータベースを作成し、このデータベースを Hive データベースにマッピングする必要があります。データベースは、データカタログ外のエンティティを指す場合、フェデレーションデータベースと呼ばれます。
タグベースのアクセスコントロールと名前付きリソースメソッドを使用して Lake Formation のアクセス許可をフェデレーションデータベースに適用し、複数 AWS アカウント、 AWS Organizations、および組織単位 (OUs) 間で共有できます。フェデレーションデータベースは、別のアカウントの IAM プリンシパルと直接共有することもできます。
外部 Hive テーブルで Lake Formation データフィルターを使用すると、列レベル、行レベル、およびセルレベルできめ細かいアクセス許可を定義できます。Amazon Athena、Amazon Redshift、または Amazon EMR を使用して、Lake Formation が管理する外部 Hive テーブルにクエリを実行できます。
クロスアカウントデータ共有およびデータフィルタリングの詳細については、以下を参照してください。
データカタログメタデータフェデレーションの手順の概要
-
AWS SAM アプリケーションをデプロイし、フェデレーションデータベースを作成するための適切なアクセス許可を持つ IAM ユーザーとロールを作成します。
-
外部 Hive メタストアを使用するデータセットの
Enable Data Catalog federationオプションを選択して、Amazon S3 のデータロケーションを Lake Formation に登録します。 AWS SAM アプリケーション設定 (AWS Glue 接続名、Hive メタストアへの URL、Lambda 関数パラメータ) を設定し、 AWS SAM アプリケーションをデプロイします。
-
AWS SAM アプリケーションは、外部 Hive メタストアをデータカタログに接続するために必要なリソースをデプロイします。
-
Hive データベースとテーブルに Lake Formation アクセス許可を適用するには、Hive メタストア接続の詳細を使用してデータカタログにデータベースを作成し、このデータベースを Hive データベースにマッピングします。
フェデレーションデータベースのアクセス許可を、自分のアカウントまたは別のアカウントのプリンシパルに付与します。
注記
Lake Formation のアクセス許可を適用しなくても、データカタログを外部 Hive メスタストアに接続したり、フェデレーションデータベースを作成したり、Hive データベースやテーブルでクエリや ETL スクリプトを実行したりできます。Lake Formation に登録されていない Amazon S3 のソースデータの場合、アクセスは Amazon S3 の IAM アクセス許可ポリシーと AWS Glue アクションによって決まります。
制限事項については、「Hive メタデータストアのデータ共有に関する考慮事項と制限事項」を参照してください。
ワークフロー
次の図は、 AWS Glue Data Catalog を外部 Hive メタストアに接続するためのワークフローを示しています。
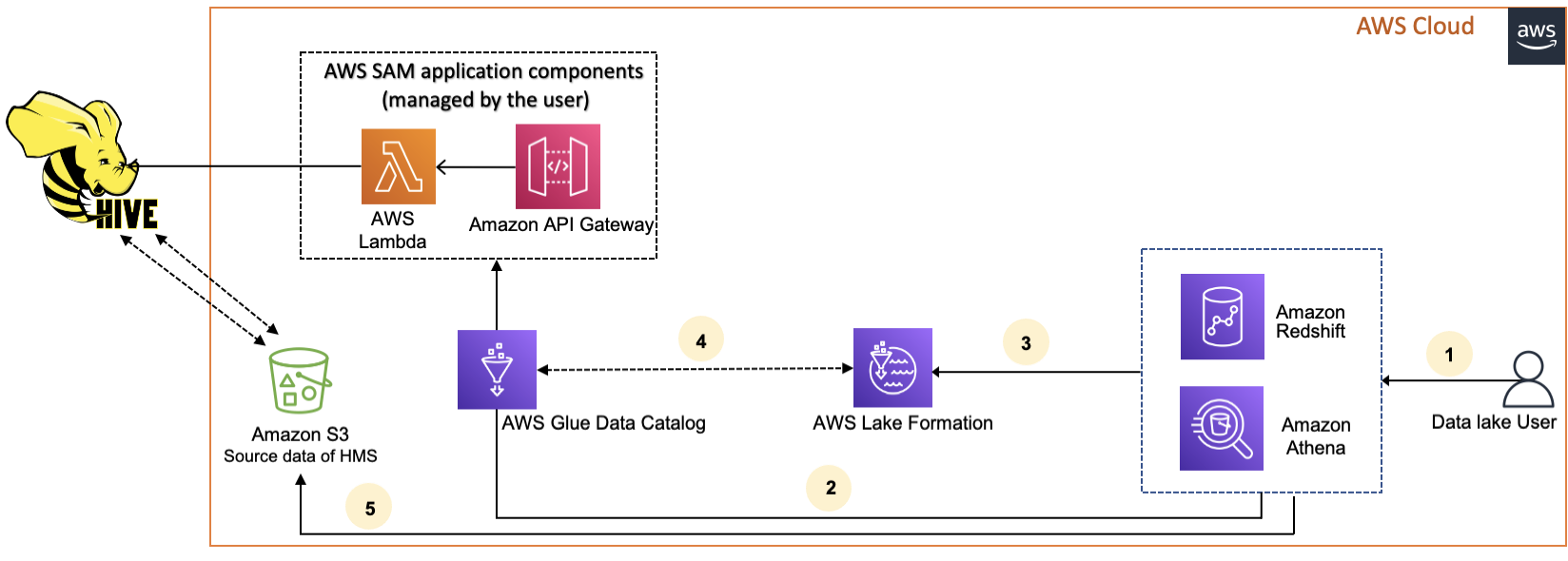
-
プリンシパルは、Athena や Redshift Spectrum などの統合サービスを使用してクエリを送信します。
統合サービスは、メタデータの Data Catalog を呼び出します。これにより、その背後で利用可能な Hive メタストアエンドポイントが呼び出され Amazon API Gateway、メタデータリクエストへの応答を受け取ります。
-
統合サービスが Lake Formation にリクエストを送信し、テーブル情報とテーブルにアクセスするための認証情報を検証します。
-
Lake Formation はリクエストを承認し、統合アプリケーションに一時的な認証情報を提供して、データアクセスを許可します。
統合サービスが Lake Formation から受け取った一時的な認証情報を使用して Amazon S3 からデータを読み取り、結果をプリンシパルと共有します。
