翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon S3 Tables と AWS Glue Data Catalog および の統合 AWS Lake Formation
Amazon S3 Tables は、分析ワークロードに特別に最適化された S3 ストレージを提供し、クエリのパフォーマンスを向上させながらコストを削減します。S3 Tables のデータは、新しいバケットタイプ、つまりテーブルをサブリソースとして保存するテーブルバケットに保存されます。S3 テーブルには Apache Iceberg 標準のサポートが組み込まれているため、Apache Spark などの一般的なクエリエンジンを使用して、Amazon S3 テーブルバケット内の表形式データに対して簡単にクエリを実行できます。
Amazon S3 Tables は、IAM アクセスコントロールまたは IAM および Lake Formation 許可 AWS Glue Data Catalog を使用して と統合できます。
-
IAM アクセスコントロール: IAM ポリシーを使用して S3 テーブルとデータカタログへのアクセスを制御します。このアクセスコントロールアプローチでは、リソースにアクセスするには、S3 Tables リソースと Data Catalog オブジェクトの両方に対する IAM アクセス許可が必要です。
-
Lake Formation アクセスコントロール: データカタログを介した S3 テーブルへのアクセスを制御するために AWS Glue 、IAM アクセス許可に加えて AWS Lake Formation 許可を使用します。このモードでは、プリンシパルは Data Catalog を操作するための IAM アクセス許可を必要とし、Lake Formation 許可によってプリンシパルがアクセスできるカタログリソース (データベース、テーブル、列、行) が決まります。このモードは、粗粒度のアクセスコントロール (データベースレベルとテーブルレベルの権限) ときめ細かなアクセスコントロール (列レベルと行レベルのセキュリティ) の両方をサポートします。登録されたロールが設定され、認証情報供給が有効になっている場合、Lake Formation は登録されたロールを使用してプリンシパルに代わって認証情報を提供するため、プリンシパルに S3 Tables IAM アクセス許可は必要ありません。Lake Formation アクセスコントロールは、サードパーティーの分析エンジンの認証情報供給もサポートしています。
このセクションでは、以下のシナリオ AWS Lake Formation で との統合を設定するためのガイダンスを提供します。
-
シナリオ A: IAM アクセスコントロールを使用して S3 テーブルとデータカタログを統合したため、使用する予定です AWS Lake Formation。詳細については、「S3 Tables 統合のアクセスコントロールの変更」を参照してください。
-
シナリオ B: を使用して S3 テーブルとデータカタログを統合する予定 AWS Lake Formation で、現在アカウントとリージョンに統合されていません。Amazon S3 テーブルカタログを データカタログおよび Lake Formation と統合するための前提条件 セクションから開始し、 に従いますAmazon S3 Tables 統合の有効化。
-
シナリオ C: を使用して S3 テーブルとデータカタログを統合し AWS Lake Formation 、IAM を使用する予定です。詳細については、「S3 Tables 統合のアクセスコントロールの変更」を参照してください。
S3 Tables と AWS 分析サービスとの統合の手順に従って、 AWS Glue Data Catalog とテーブルリソースにアクセスし、 AWS 分析サービスと連携するための適切なアクセス許可があることを確認してください。
トピック
データカタログと Lake Formation の統合の仕組み
S3 テーブルカタログを データカタログおよび Lake Formation と統合すると、 AWS Glue サービスは AWS リージョンに固有のアカウントのデフォルトデータカタログに s3tablescatalog という名前の単一のフェデレーティッドカタログを作成します。統合では、アカウントとフェデレーティッドカタログ内のすべての Amazon S3 テーブルバケットリソース AWS リージョン を次の方法でマッピングします。
Amazon S3 テーブルバケットは、データカタログ内のマルチレベルカタログになります。
-
関連付けられた Amazon S3 名前空間は、データカタログにデータベースとして登録されます。
-
テーブルバケット内の Amazon S3 Tables は、データカタログ内のテーブルになります。
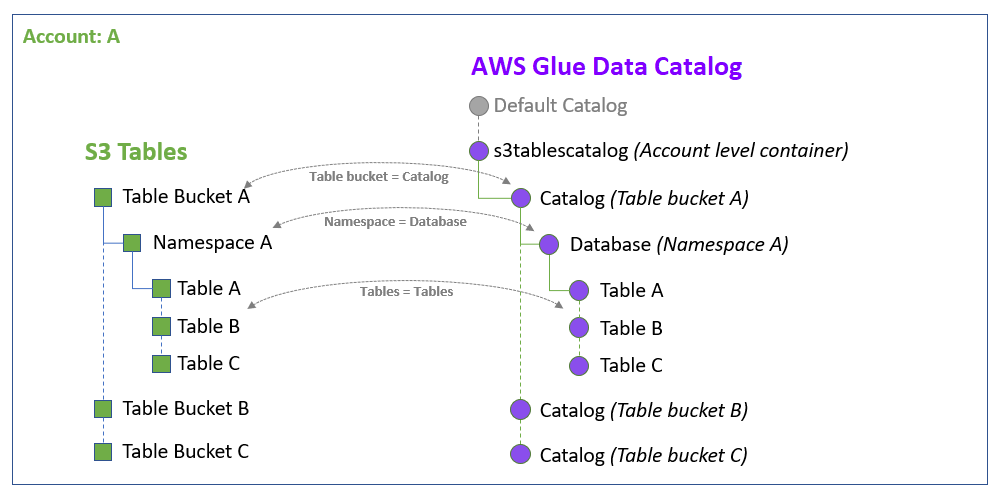
Lake Formation と統合した後、テーブルバケットカタログに Apache Iceberg テーブルを作成し、 Amazon Athena Amazon EMR やサードパーティー AWS の分析エンジンなどの統合分析エンジンを介してそれらにアクセスできます。
統合で Lake Formation も有効にすると、きめ細かなアクセスコントロールが可能になります AWS Lake Formation。このセキュリティアプローチは、 (IAM) アクセス許可に加えて AWS Identity and Access Management 、テーブルを操作する前に、テーブルに対する Lake Formation アクセス許可を IAM プリンシパルに付与する必要があることを意味します。
AWS Lake Formationには、2 つの主な許可タイプがあります。
-
メタデータに対するアクセス許可は、データカタログ内でメタデータデータベースとテーブルを作成、読み取り、更新、削除できるかどうかを制御します。
-
基になるデータに対するアクセス許可は、データカタログリソースの参照先となる Amazon S3 の場所にデータを読み書きできるかどうかを制御します。
Lake Formation では、独自のアクセス許可モデルと IAM アクセス許可モデルを組み合わせて使用して、データカタログリソースと基になるデータへのアクセスを制御します。
-
データカタログリソースまたは基になるデータへのアクセスリクエストが成功するには、そのリクエストが IAM と Lake Formation の両方によるアクセス許可のチェックに合格する必要があります。
-
IAM アクセス許可は Lake Formation および AWS Glue APIs とリソースへのアクセスを制御し、Lake Formation アクセス許可は Data Catalog リソース、Amazon S3 ロケーション、および基盤となるデータへのアクセスを制御します。
Lake Formation 許可は付与されたリージョン内でのみ適用されます。プリンシパルが Lake Formation 許可を付与されるには、データレイク管理者または必要なアクセス許可を持つ別のプリンシパルによって認可される必要があります。
