翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
チュートリアル: Amazon Kendra を使用したメタデータに富んだインテリジェントな検索ソリューションの構築
このチュートリアルでは、Amazon Kendra
Amazon Kendra は、非構造化自然言語データリポジトリの検索インデックスを構築できるインテリジェントな検索サービスです。お客様が関連する回答を簡単に検索してフィルタリングできるようにするには、Amazon Comprehend を使用してデータからメタデータを抽出し、Amazon Kendra 検索インデックスに取り込みます。
Amazon Comprehend は、エンティティを識別できる自然言語処理 (NLP) サービスです。エンティティは、データ内の人、場所、位置、組織、およびオブジェクトのリファレンスです。
このチュートリアルでは、ニュース記事のサンプルデータセットを使用して、エンティティを抽出し、メタデータに変換し、Amazon Kendra インデックスに取り込んで検索を実行します。追加されたメタデータを使用すると、これらのエンティティのサブセットを使用して検索結果をフィルタリングでき、検索の精度が向上します。このチュートリアルに従うことで、専門的な機械学習知識がなくても、エンタープライズデータの検索ソリューションを作成する方法を学習します。
このチュートリアルでは、以下のステップで検索ソリューションを構築する方法を示します。
-
Amazon S3 にニュース記事のサンプルデータセットを保存する。
-
Amazon Comprehend を使用してデータからエンティティを抽出します。
-
Python 3 スクリプトを実行してエンティティを Amazon Kendra インデックスメタデータ形式に変換し、このメタデータを S3 に保存します。
-
Amazon Kendra 検索インデックスを作成し、データとメタデータを取り込みます。
-
検索インデックスのクエリ。
以下の図に、このワークフローを示しています。
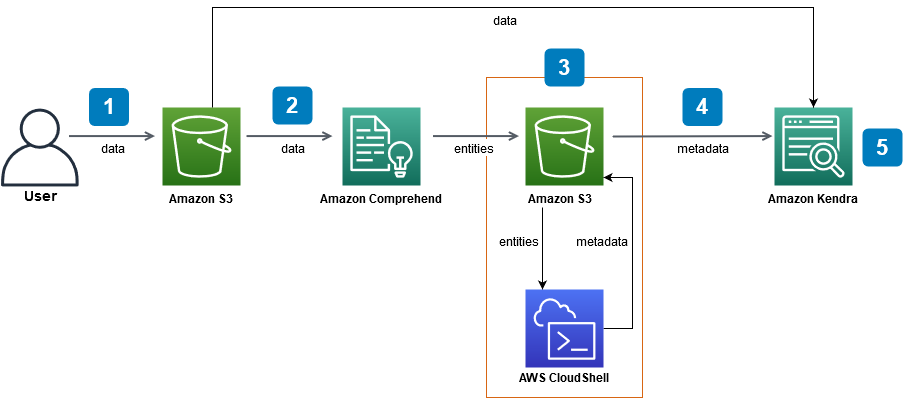
このチュートリアルを完了する予定時間: 1 時間
推定コスト: このチュートリアルの一部のアクションでは、 AWS アカウントに料金が発生します。各サービスのコストの詳細については、Amazon S3
トピック
前提条件
このチュートリアルを完了するには、以下のリソースが必要です。
-
AWS アカウント。 AWS アカウントがない場合は、「Amazon Kendra のセットアップ」の手順に従って AWS アカウントを設定します。
-
AWS コマネジメントコンソールにアクセスするための、Windows、macOS、および Linux を実行している開発用コンピュータ。詳細については、「 AWS マネジメントコンソールの設定」を参照してください。
-
AWS Identity and Access Management
(IAM) ユーザー。アカウントの IAM ユーザーとグループをセットアップする方法については、IAM ユーザーガイドの開始方法セクションを参照してください。 を使用している場合は AWS Command Line Interface、次のポリシーを IAM ユーザーにアタッチして、このチュートリアルを完了するために必要な基本的なアクセス許可を付与する必要があります。
詳細については、IAM ポリシーの作成およびIAM アイデンティティアクセス許可の追加と削除を参照してください。
-
AWS リージョンサービスリスト
。レイテンシーを減らすには、Amazon Comprehend と Amazon Kendra の両方でサポートされている地理的な場所に最も近い AWS リージョンを選択する必要があります。 -
(オプション) AWS Key Management Service。このチュートリアルでは暗号化を使用しませんが、特定のユースケースで暗号化のベストプラクティスを使用することをお勧めします。
-
(オプション) Amazon Virtual Private Cloud。このチュートリアルでは VPC を使用しませんが、VPC のベストプラクティスを使用して特定のユースケースでデータセキュリティを確保することをお勧めします。
