AWS Glue での Apache Spark の生成 AI アップグレード
AWS Glue の Spark アップグレードにより、データエンジニアや開発者は生成 AI を使用して既存の AWS Glue Spark ジョブを最新の Spark リリースにアップグレードして移行できます。データエンジニアはこれを使用して、AWS Glue Spark ジョブのスキャン、アップグレードプランの生成、プランの実行、出力の検証を行うことができます。Spark スクリプト、設定、依存関係、メソッド、機能の特定と更新に関する区別されていない作業を自動化することで、Spark のアップグレードにかかる時間とコストを削減します。

仕組み
アップグレード分析を使用すると、AWS Glue はジョブのコードのバージョンと設定の違いを特定して、アップグレードプランを生成します。アップグレードプランには、すべてのコード変更と必要な移行ステップの詳細が記載されています。次に、AWS Glue はアップグレードされたアプリケーションを環境で構築して実行することで、変更を検証し、ジョブを移行するためのコード変更のリストを生成します。更新されたスクリプトと、提案された変更の詳細を示す概要を表示できます。独自のテストを実行したら、変更を受け入れると、AWS Glue ジョブは新しいスクリプトで最新バージョンに自動的に更新されます。
ジョブとワークロードの複雑さによっては、アップグレード分析プロセスが完了するまでに時間がかかる場合があります。アップグレード分析の結果は、指定された Amazon S3 パスに保存されます。このパスを確認して、アップグレードと潜在的な互換性の問題を理解できます。アップグレード分析結果を確認したら、アップグレード前に実際のアップグレードを続行するか、ジョブに必要な変更を加えるかを決定できます。
前提条件
生成 AI を使用して AWS Glue のジョブをアップグレードするには、次の前提条件が必要です:
-
AWS Glue 2 PySpark ジョブ – AWS Glue 5 にアップグレードできるのは AWS Glue 2 ジョブのみです。
-
分析の開始、結果の確認、ジョブのアップグレードには IAM アクセス許可が必要です。詳細については、下記の アクセス許可 セクションの例を参照してください。
-
AWS KMS を使用して分析アーティファクトを暗号化する場合は、追加の AWS AWS KMS 許可が必要です。詳細については、下記の AWS KMS ポリシー セクションの例を参照してください。
アクセス許可
-
次のアクセス許可を使用して、発信者の IAM ポリシーを更新します:
-
アップグレードするジョブの実行ロールを更新して、次のインラインポリシーを含めます:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }例えば、Amazon S3 パス
s3://amzn-s3-demo-bucket/upgraded-resultを使用している場合、ポリシーは次のようになります:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
AWS KMS ポリシー
分析の開始時に独自のカスタム AWS KMS キーを渡すには、次のセクションを参照して、AWS KMS キーに対する適切なアクセス許可を設定してください。
このポリシーにより、AWS KMS キーに対する暗号化と復号の両方のアクセス許可が付与されます。
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
アップグレード分析の実行とアップグレードスクリプトの適用
アップグレード分析を実行すると、[ジョブ] ビューから選択したジョブでアップグレードプランが生成されます。
-
ジョブ から AWS Glue 2.0 ジョブを選択し、アクション メニューから アップグレード分析の実行 を選択します。
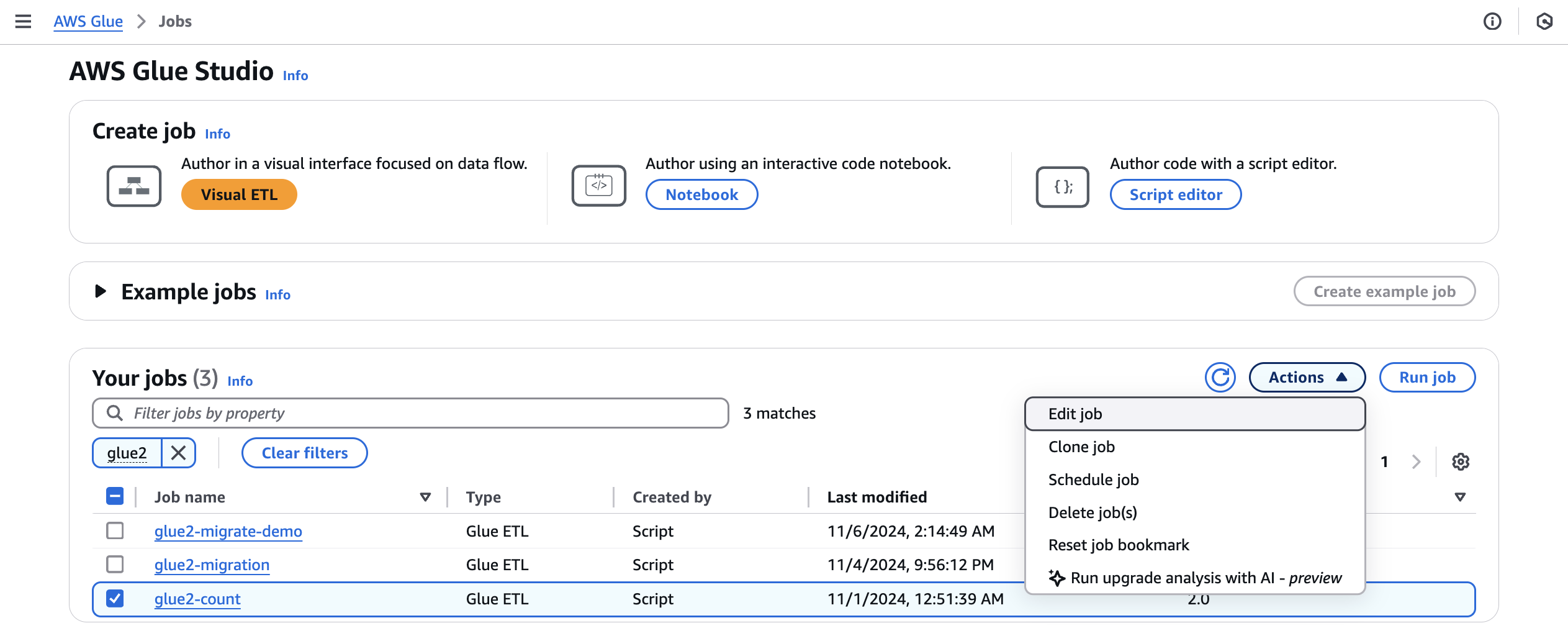
-
モーダルで、生成されたアップグレードプランを [結果パス] に保存するためのパスを選択します。これは、アクセスおよび書き込みが可能な Amazon S3 バケットである必要があります。
![このスクリーンショットは、完了したアップグレード分析を示しています。[アップグレードされたスクリプトを適用] のボタンが表示されます。](images/upgrade-analysis-configuration-options.png)
-
必要に応じて、追加オプションを設定します:
-
実行設定 – オプション: 実行設定は、アップグレード分析中に実行される検証実行のさまざまな側面をカスタマイズできるオプション設定です。この設定は、アップグレードされたスクリプトの実行に使用され、コンピューティング環境のプロパティ (ワーカータイプ、ワーカー数など) を選択できます。変更を確認して受け入れ、本番環境に適用する前に、本番稼働用以外の開発者アカウントを使用してサンプルデータセットで検証を実行する必要があります。実行設定には、以下のカスタマイズ可能なパラメータが含まれます:
-
ワーカータイプ: 検証の実行に使用するワーカーのタイプを指定できるため、要件に基づいて適切なコンピューティングリソースを選択できます。
-
ワーカーの数: 検証実行用にプロビジョニングするワーカーの数を定義できるため、ワークロードのニーズに応じてリソースをスケーリングできます。
-
ジョブタイムアウト (分単位): このパラメータを使用すると、検証実行の時間制限を設定して、リソースの過剰な消費を防ぐために、指定された期間後にジョブが終了するようにできます。
-
セキュリティ設定: 暗号化やアクセスコントロールなどのセキュリティ設定を設定して、検証実行中のデータやリソースを確実に保護できます。
-
追加のジョブパラメータ: 必要に応じて、新しいジョブパラメータを追加して、検証実行の実行環境をさらにカスタマイズできます。
実行設定を活用することで、特定の要件に合わせて検証実行を調整できます。例えば、より小さなデータセットを使用するように検証実行を設定できます。これにより、分析をより迅速に完了し、コストを最適化できます。この方法により、検証フェーズ中のリソース使用率と関連コストを最小限に抑えながら、アップグレード分析を効率的に実行できます。
-
-
暗号化設定 – オプション:
-
アップグレードアーティファクトの暗号化を有効にする: 結果パスにデータを書き込むときに、保存時の暗号化を有効にします。アップグレードアーティファクトを暗号化しない場合は、このオプションはオフのままにします。
-
-
-
[実行] を選択してアップグレード分析を開始します。分析の実行中に、アップグレード分析タブで結果を表示できます。分析の詳細ウィンドウには、分析に関する情報とアップグレードアーティファクトへのリンクが表示されます。
-
結果パス — 結果の概要とアップグレードスクリプトが格納されます。
-
Amazon S3 のアップグレードされたスクリプト – Amazon S3 のアップグレードスクリプトの場所。アップグレードを適用する前にスクリプトを表示できます。
-
Amazon S3 のアップグレード概要 – Amazon S3 のアップグレード概要の場所。アップグレードを適用する前に、アップグレードの概要を表示できます。
-
-
アップグレード分析が正常に完了したら、アップグレードスクリプトを適用して、[アップグレードスクリプトを適用] を選択することでジョブを自動的にアップグレードできます。
適用すると、AWS Glue バージョンが 4.0 に更新されます。新しいスクリプトは、[スクリプト] タブに表示されます。
![このスクリーンショットは、完了したアップグレード分析を示しています。[アップグレードされたスクリプトを適用] のボタンが表示されます。](images/upgrade-analysis-analysis-details-preview.png)
アップグレードの概要について
この例では、AWS Glue ジョブをバージョン 2.0 からバージョン 4.0 にアップグレードするプロセスを示します。サンプルジョブは Amazon S3 バケットから製品データを読み取り、Spark SQL を使用してデータにいくつかの変換を適用し、変換された結果を Amazon S3 バケットに保存します。
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

概要に基づいて、スクリプトを AWS Glue 2.0 から AWS Glue 4.0 に正常にアップグレードするために、AWS Glue が提案した 4 つの変更があります。
-
Spark SQL 設定 (spark.sql.adaptive.enabled): この変更は、Spark SQL アダプティブクエリ実行の新しい機能が Spark 3.2 から導入されたため、アプリケーションの動作を復元するためのものです。この設定の変更を検査し、必要に応じてさらに有効または無効にできます。
-
DataFrame API の変更: パスオプションは、
load()などの他の DataFrameReader オペレーションと共存できません。前の動作を維持するために、AWS Glue はスクリプトを更新して新しい SQL 設定 (spark.sql.legacy.pathOptionBehavior.enabled) を追加しました。 -
Spark SQL API の変更: 最初の引数として
0$を禁止するように、format_string(strfmt, obj, ...)のstrfmtの動作が更新されました。互換性を確保するために、AWS Glue は代わりに最初の引数として1$を使用するようにスクリプトを変更しました。 -
Spark SQL API の変更:
unbase64関数は不正な形式の文字列入力を許可しません。前の動作を維持するために、AWS Glue はtry_to_binary関数を使用するようにスクリプトを更新しました。
進行中のアップグレード分析の停止
進行中のアップグレード分析をキャンセルすることも、分析を停止することもできます。
-
[アップグレード分析] タブを選択します。
-
実行中のジョブを選択し、[停止] を選択します。これにより、分析が停止します。その後、同じジョブで別のアップグレード分析を実行できます。

考慮事項
Spark アップグレードの使用を開始する際には、サービスの最適な使用について考慮すべき重要な点がいくつかあります。
-
サービスの範囲と制限: 現在のリリースでは、PySpark コードを AWS Glue バージョン 2.0 からバージョン 5.0 にアップグレードすることに重点を置いています。現時点では、サービスは追加のライブラリ依存関係に依存しない PySpark コードを処理します。AWS アカウントで最大 10 個のジョブの自動アップグレードを同時に実行できるため、システムの安定性を維持しながら複数のジョブを効率的にアップグレードできます。
-
PySpark ジョブのみがサポートされています。
-
アップグレード分析は 24 時間後にタイムアウトします。
-
1 つのジョブに対して一度に実行できるアクティブなアップグレード分析は 1 つだけです。アカウントレベルでは、最大 10 個のアクティブなアップグレード分析を同時に実行できます。
-
-
アップグレードプロセス中のコストの最適化: Spark アップグレードでは生成 AI を使用して複数の反復でアップグレードプランを検証するため、各反復はアカウントで AWS Glue ジョブとして実行されるため、コスト効率を高めるためには、検証ジョブの実行設定を最適化することが不可欠です。これを実現するには、アップグレード分析を開始するときに次のように実行設定を指定することをお勧めします:
-
本番稼働用以外のデベロッパーアカウントを使用して、本番稼働用データを表すが、Spark Upgrades での検証にはサイズが小さいサンプルモックデータセットを選択します。
-
G.1X ワーカーなどの適切なサイズのコンピューティングリソースを使用し、サンプルデータを処理するための適切なワーカー数を選択します。
-
該当する場合は AWS Glue ジョブの自動スケーリングを有効にして、ワークロードに応じてリソースを自動的に調整します。
例えば、本番稼働用ジョブが 20 G.2X ワーカーでテラバイトのデータを処理する場合、アップグレードジョブを、2 G.2X ワーカーで数ギガバイトの代表的なデータを処理するように設定し、検証のために自動スケーリングを有効にする可能性があります。
-
-
ベストプラクティス: 非本番環境のジョブでアップグレードジャーニーを開始することを強くお勧めします。この方法により、アップグレードワークフローに慣れ、サービスがさまざまなタイプの Spark コードパターンをどのように処理するかを理解することができます。
-
アラームと通知: ジョブで生成 AI アップグレード機能を利用する場合は、失敗したジョブ実行のアラーム/通知がオフになっていることを確認します。アップグレードプロセス中に、アップグレードされたアーティファクトが提供される前に、アカウントで最大 10 件のジョブ実行が失敗することがあります。
-
異常検出ルール: アップグレード中のジョブでも異常検出ルールをオフにします。中間ジョブの実行中に出力フォルダに書き込まれたデータが、アップグレード検証が進行している間、想定どおりの形式ではない可能性があります。
-
べき等ジョブでアップグレード分析を使用する: べき等ジョブでアップグレード分析を使用して、後続の各検証ジョブ実行試行が前のものと類似し、問題が発生しないようにします。べき等ジョブは、同じ入力データで複数回実行できるジョブであり、毎回同じ出力を生成します。AWS Glue で Apache Spark の生成 AI アップグレードを使用する場合、サービスは検証プロセスの一環としてジョブの反復を複数回実行します。各イテレーション中に、Spark コードと設定を変更してアップグレードプランを検証します。Spark ジョブが「べき等」でない場合、同じ入力データで複数回実行すると問題が発生する可能性があります。
サポート対象のリージョン
Apache Spark の生成 AI アップグレードは、次のリージョンで利用できます。
-
アジアパシフィック: 東京 (ap-northeast-1)、ソウル (ap-northeast-2)、ムンバイ (ap-south-1)、シンガポール (ap-southeast-1)、シドニー (ap-southeast-2)
-
北米: カナダ (ca-central-1)
-
欧州: フランクフルト (eu-central-1)、ストックホルム (eu-north-1)、アイルランド (eu-west-1)、ロンドン (eu-west-2)、パリ (eu-west-3)
-
南米: サンパウロ (sa-east-1)
-
米国: バージニア北部 (us-east-1)、オハイオ (us-east-2)、オレゴン (us-west-2)
Spark アップグレードのクロスリージョン推論
Spark アップグレードは Amazon Bedrock を利用しており、クロスリージョン推論 (CRIS) を活用します。CRIS により、Spark アップグレードは地理的に最適なリージョンを自動的に選択して推論リクエストを処理し (詳細はこちら)、利用可能なコンピューティングリソースとモデルの可用性を最大化し、最高のカスタマーエクスペリエンスを提供します。クロスリージョン推論の使用に追加コストはかかりません。
クロスリージョン推論リクエストは、データが最初に存在していた地域の一部である AWS リージョン内に保持されます。例えば、米国内で行われたリクエストは、米国の AWS リージョン内に保持されます。データはプライマリリージョンにのみ保存されますが、クロスリージョン推論を使用する場合、入力プロンプトと出力結果がプライマリリージョン外に移動することがあります。すべてのデータは Amazon の安全なネットワーク経由で暗号化されて送信されます。
